






Redis 核心机制深度解析
一、Redis为什么快?
1. 内存存储
-
全内存操作:数据存储在内存中,读写速度比磁盘高几个数量级.,
基于内存:Redis 是一种基于内存的数据库,数据存储在内存中,数据的读写速度非常快,因为内存访问速度比硬盘访问速度快得多。
-
避免磁盘I/O瓶颈:不受传统数据库磁盘寻道时间限制
2. 单线程架构
-
无锁竞争:单线程处理命令,避免多线程上下文切换和锁竞争
-
原子性保证:所有命令天然具备原子性
-
高效事件模型:基于Reactor模式的I/O多路复用(epoll/kqueue)
-
不需要进行线程切换和上下文切换。这大大提高了 Redis 的运行效率和响应速度。
3. 高效数据结构
| 数据结构 | 时间复杂度 | 特殊优化 |
|---|---|---|
| 哈希表 | O(1) | 渐进式rehash |
| 跳表 | O(logN) | 多层索引 |
| 压缩列表 | O(N) | 内存连续存储 |
| 快速列表 | O(N) | 链表+ziplist混合 |
4. 多路复用 I/O 模型:
Redis 在单线程的基础上,采用了I/O 多路复用技术,实现了单个线程同时处理多个客户端连接的能力,从而提高了 Redis 的并发性能。
-
管道技术:批量命令减少网络往返
-
协议简单:RESP协议解析高效
5.多线程的引入:
在Redis 6.0中,为了进一步提升IO的性能,引入了多线程的机制。采用多线程,使得网络处理的请求并发进行,就可以大大的提升性能。多线程除了可以减少由于网络 I/O 等待造成的影响,还可以充分利用 CPU 的多核优势。
二、Lua脚本原子性保证
底层原理
Lua脚本可以保证原子性,因为Redis会将Lua脚本封装成一个单独的事务,而这个单独的事务会在Redis客户端运行时,由Redis服务器自行处理并完成整个事务,如果在这个进程中有其他客户端请求的时候,Redis将会把它暂存起来,等到 Lua 脚本处理完毕后,才会再把被暂存的请求恢复。
1. 原子性原理
-
单线程执行:整个脚本作为一个命令执行,期间不会处理其他命令
-
脚本缓存:SHA1缓存脚本避免重复传输
2. 实现计数器
-- 实现原子计数器
local current = redis.call('GET', KEYS[1])
local new = current + ARGV[1]
redis.call('SET', KEYS[1], new)
return new
3. 注意事项
Redis保证以原子方式执行Lua脚本,但是不保证脚本中所有操作要么都执行或者都回滚。
为什么不能回滚呢?:
支持回滚将对 Redis 的简洁性和性能产生重大影响。因为Redis的设计就是简单、高效等,所以引入事务的回滚机制会让系统更加的复杂,并且影响性能。从使用场景上来说,Redis一般都是被用作缓存的,不太需要很复杂的事务支持,当人们需要复杂的事务时会考虑持久化的关系型数据库。相比于关系型数据库,Redis是通过单线程执行的,在执行过程中,出现错误的概率比较低,并且这些问题一般来编译阶段都应该被发现,所以就不太需要引入回滚机制。
-
无回滚机制:脚本执行中途出错不会回滚已执行命令
-
超时处理:默认5秒超时(可通过
lua-time-limit调整) -
脚本签名:使用
EVALSHA执行缓存脚本
三、Redis事务机制和lua脚本的对比
Redis中是支持事务的,他的事务主要目的是保证多个命令执行的原子性,即要在一个原子操作中执行,不会被打断。需要注意的是,Redis的事务是不支持回滚的
1. 事务特性
| 特性 | 说明 | ACID对比 |
|---|---|---|
| 原子性 | 命令队列的原子执行 | 部分满足 |
| 一致性 | 执行错误会保证数据一致 | 满足 |
| 隔离性 | 单线程天然隔离 | 完全满足 |
| 持久性 | 依赖持久化配置 | 可选 |
2. 事务命令
Redis事务相关的命令主要有以下几个:
●MULTI:标记一个事务块的开始。
●DISCARD:取消事务,放弃执行事务块内的所有命令。
●EXEC:执行所有事务块内的命令。
●UNWATCH:取消 WATCH 命令对所有 key 的监视。
●WATCH key [key ...]:监视一个(或多个) key ,如果在事务执行之前这个(或这些) key 被其他命令所改动,那么事务将被打断。也可以用来实现乐观锁
> MULTI # 开启事务 > SET k1 v1 # 命令入队 > SET k2 v2 > EXEC # 执行事务 # 监视键(乐观锁) > WATCH k1 > MULTI > SET k1 new_v > EXEC # 如果k1被修改则事务失败
3. 与lua脚本对比
Redis的事务在执行过程中,如果有某一个命令失败了,是不影响后续命令的执行的,而Lua脚本中,如果执行过程中某个命令执行失败了,是会影响后续命令执行的。
在Redis的事务执行时,每一条命令都需要和Redis服务器进行一次交互,我们可以在Redis事务过程中,MULTI 和 EXEC 之间发送多个 Redis 命令给到Redis服务器,这些命令会被服务器缓存起来,但并不会立即执行。但是每一条命令的提交都需要进行一次网络交互。
而Lua脚本则不需要,只需要一次性的把整个脚本提交给Redis即可。网络交互比事务要少。
在 Redis 的事务中,事务内的命令都是独立执行的,并且在没有执行EXEC命令之前,命令是没有被真正执行的,所以后续命令是不会也不能依赖于前一个命令的结果的。
而在Lua 脚本中是可以依赖前一个命令的结果的,Lua 脚本中的多个命令是依次执行的,我们可以利用前一个命令的结果进行后续的处理。
借助Lua脚本,我们可以实现非常丰富的各种分支流程控制,以及各种运算相关操作。而Redis的事务本身是不支持这些操作的。
四、内存淘汰策略
1. 淘汰策略配置
# redis.conf maxmemory-policy volatile-lru
2. 策略分类
内存 淘汰策略:
noeviction:不会淘汰任何键值对,而是直接返回错误信息。
●allkeys-lru:从所有 key 中选择最近最少使用的那个 key 并删除。
●volatile-lru:从设置了过期时间的 key 中选择最近最少使用的那个 key 并删除。
●allkeys-random:从所有 key 中随机选择一个 key 并删除。
●volatile-random:从设置了过期时间的 key 中随机选择一个 key 并删除。
●volatile-ttl:从设置了过期时间的 key 中选择剩余时间最短的 key 并删除。
● volatile-lfu:淘汰的对象是带有过期时间的键值对中,访问频率最低的那个。
●allkeys-lfu:淘汰的对象则是所有键值对中,访问频率最低的那个。
删除 策略
Redis 的过期策略采用的是定期删除和惰性删除相结合的方式。
●定期删除:Redis 默认每隔 100ms 就随机抽取一些设置了过期时间的 key,并检查其是否过期,如果过期才删除。定期删除是 Redis 的主动删除策略,它可以确保过期的 key 能够及时被删除,但是会占用 CPU 资源去扫描 key,可能会影响 Redis 的性能。
●惰性删除:当一个 key 过期时,不会立即从内存中删除,而是在访问这个 key 的时候才会触发删除操作。惰性删除是 Redis 的被动删除策略,它可以节省 CPU 资源,但是会导致过期的 key 始终保存在内存中,占用内存空间。
Redis默认同时开启定期删除和惰性删除两种过期策略。
3. LRU算法优化
-
近似LRU:随机采样5个键淘汰最久未使用的
-
LFU支持:4.0+版本支持LFU(最不经常使用)
// Redis近似LRU实现(简化)
key *evictPoolSample(dict *dict, int count) {
keys = randomSample(dict, count);
return findOldestKey(keys);
}
五、持久化机制
1. RDB(快照)
特点:
-
二进制全量备份
-
fork子进程执行,不影响主进程
-
恢复速度快
手动触发
在Redis中,我们可以通过以下命令手动生成 RDB 文件:
●SAVE:会阻塞 Redis 服务器,直到快照完成。
●BGSAVE:在后台异步生成 RDB 文件,不会阻塞 Redis。
配置:
save 900 1 # 900秒内1次修改触发 save 300 10 # 300秒内10次修改 dbfilename dump.rdb
流程:
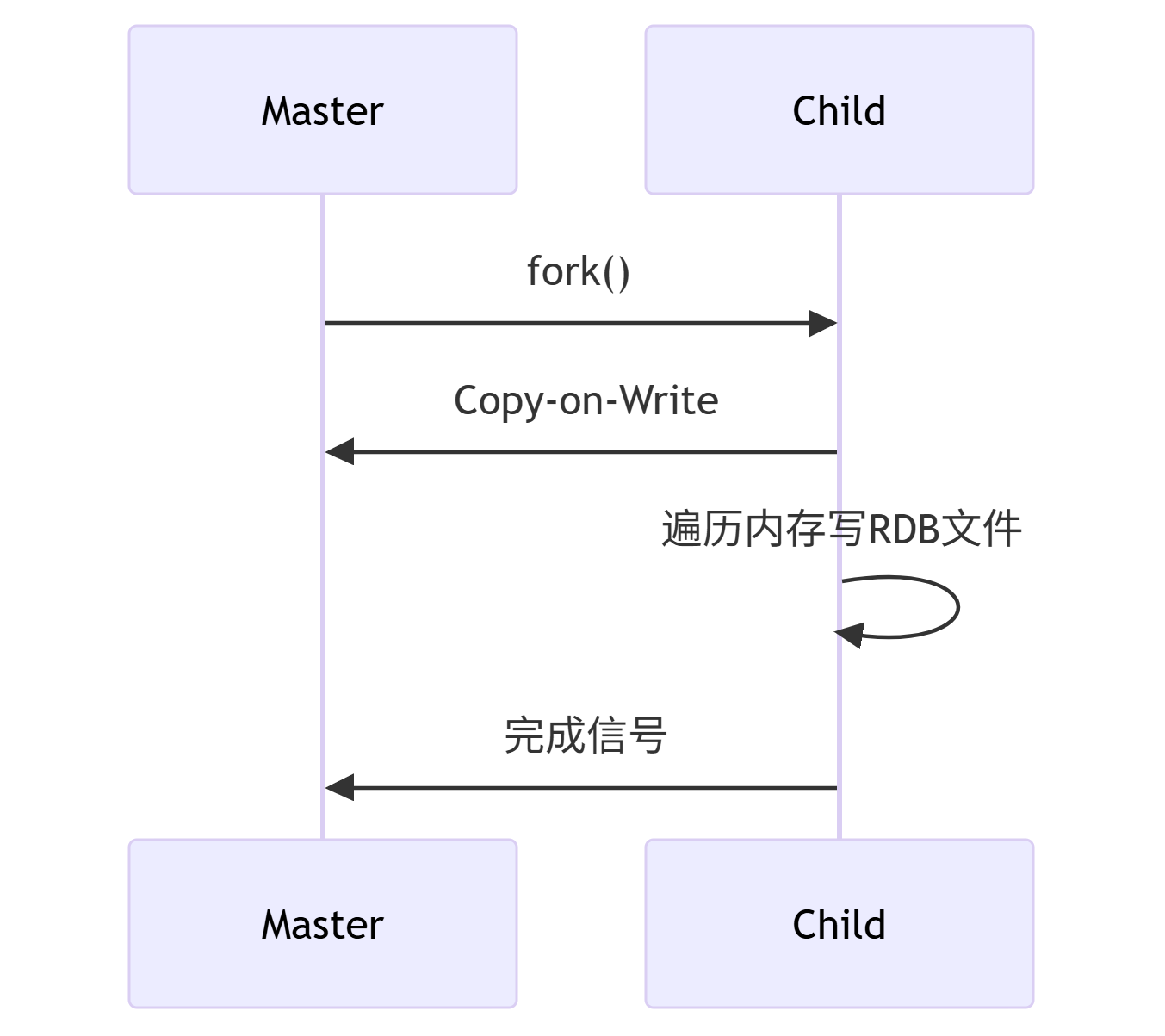
2. AOF(追加日志)
AOF有三种数据写回策略,分别是Always,Everysec和No。
●Always,同步写回:每个写命令执行完,立马同步地将日志写回磁盘;
●Everysec,每秒写回:每个写命令执行完,只是先把日志写到AOF文件的内存缓冲区,每隔一秒把缓冲区中的内容写入磁盘;
●No,操作系统控制的写回:每个写命令执行完,只是先把日志写到AOF文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘。
特点:
-
记录所有写命令
-
支持每秒/每次/不同步三种策略
-
可重写压缩
配置:
appendonly yes appendfsync everysec # 每秒同步 auto-aof-rewrite-percentage 100
重写过程:
-
fork子进程
-
子进程扫描内存生成新AOF
-
期间增量命令写入缓冲区
-
重写完成后合并缓冲区
3. 混合持久化(4.0+)
aof-use-rdb-preamble yes # AOF文件包含RDB头部
4.能不能完全保持数据不丢失
但是即使是在always策略下,也不能保证100%不丢失数据的,主要出于以下原因:
1磁盘和系统故障:如果在写入操作和同步到磁盘之间发生硬件故障或系统崩溃,可能会丢失最近的写操作。
2操作系统缓冲区:即使Redis请求立即将数据同步到磁盘,操作系统的I/O缓冲区可能会导致实际写入磁盘的操作延迟发生。如果在写入缓冲区之后,没写磁盘前,机器挂了,那么数据就丢了。
操作系统缓冲区,通常指的是操作系统用于管理数据输入输出(I/O)的一种内存区域。当程序进行文件写入操作时,数据通常首先被写入到这个缓冲区,而不是直接写入到硬盘。
3磁盘写入延迟:磁盘的写入并非实时完成,特别是在涉及到机械硬盘时,写入延迟主要由磁盘旋转速度(RPM)和寻道时间决定。如果在这这个延迟过程中,机器挂了,那么数据也就丢了。
六、集群机制
1. 数据分片
-
哈希槽:16384个槽,每个节点负责部分槽
-
键路由:
CRC16(key) % 16384
// 槽位计算(简化) int slot = crc16(key) % 16384;
2. 集群架构
和 MySQL 对跨库事务支持存在限制一样,在 Redis Cluster 中使用事务和 Lua 脚本时,也是有一定的限制的。
在 Redis Cluster 中,事务不能跨多个节点执行。事务中涉及的所有键必须位于同一节点上。如果尝试在一个事务中包含多个分片的键,事务将失败。另外,对 WATCH 命令也用同样的限制,要求他只能监视位于同一分片上的键。
和事务相同,执行 Lua 脚本时,脚本中访问的所有键也必须位于同一节点。Redis 不会在节点之间迁移数据来支持跨节点的脚本执行。Lua 脚本执行为原子操作,但是如果脚本因为某些键不在同一节点而失败,整个脚本将终止执行,可能会影响数据的一致性。
可以使用hashtag(干预 hash 结果)、应用层处理、拆分操作实现集群上的lua脚本
| 组件 | 作用 |
|---|---|
| 主节点 | 处理读写,复制数据 |
| 从节点 | 故障转移备用 |
| 哨兵 | 监控与自动故障转移(独立模式) |
3. 故障转移
-
节点间PING/PONG检测
-
超过半数主节点认为某节点下线
-
从节点发起选举
-
新主节点接管槽位
4. 分区容忍性
-
gossip协议:节点间状态传播
-
重定向:MOVED/ASK响应引导客户端
-
跨槽操作限制:需使用hash tag确保同节点
# hash tag示例(确保同节点)
SET user:{1000}:name "Alice"
SET user:{1000}:age 30
脑裂问题
Redis的脑裂问题可能发生在网络分区或者主节点出现问题的时候:
●网络分区:网络故障或分区导致了不同子集之间的通信中断。
○Master节点,哨兵和Slave节点被分割为了两个网络,Master处在一个网络中,Slave库和哨兵在另外一个网络中,此时哨兵发现和Master连不上了,就会发起主从切换,选一个新的Master,这时候就会出现两个主节点的情况。
●主节点问题:集群中的主节点之间出现问题,导致不同的子集认为它们是正常的主节点。
○Master节点有问题,哨兵就会开始选举新的主节点,但是在这个过程中,原来的那个Master节点又恢复了,这时候就可能会导致一部分Slave节点认为他是Master节点,而另一部分Slave新选出了一个Master
脑裂问题可能导致以下问题:
●数据不一致:不同子集之间可能对同一数据进行不同的写入,导致数据不一致。
●重复写入:在脑裂解决后,不同子集可能尝试将相同的写入操作应用到主节点上,导致数据重复。
●数据丢失:新选出来的Master会向所有的实例发送slave of命令,让所有实例重新进行全量同步,而全量同步首先就会将实例上的数据先清空,所以在主从同步期间在原来那个Master上执行的命令将会被清空。
Redis 已经提供了两个配置项可以帮我们做这个事儿,分别是 min-slaves-to-write 和 min-slaves-max-lag。
min-slaves-to-write:主库能进行数据同步的最少从库数量;
min-slaves-max-lag:主从库间进行数据复制时,从库给主库发送 ACK 消息的最大延迟秒数。
七、典型应用场景
1. 缓存模式

2. 分布式锁
需要考虑互斥性、可重入性、锁的性能,锁的有效时间、单点故障问题、网络分区问题、时钟飘逸问题
setnx+lua脚本实现
-- 原子获取锁
if redis.call('SETNX', KEYS[1], ARGV[1]) == 1 then
redis.call('EXPIRE', KEYS[1], ARGV[2])
return 1
end
Redisson实现
lock方法实现(阻塞型)
阻塞的方式去获取锁,如果获取锁失败会一直等待,直到获取成功。
RLock lock = redisson.getLock("myLock");
lock.lock(); // 阻塞方法,直到获取到锁
try {
// 执行代码
} finally {
lock.unlock();
}
trylock实现(没有设置超时时间是非阻塞的)
tryLock是尝试获取锁,如果能获取到直接返回true,如果无法获取到锁,他会按照我们指定的waitTime进行阻塞,在这个时间段内他还会再尝试获取锁。如果超过这个时间还没获取到则返回false。如果我们没有指定waitTime,那么他就在未获取到锁的时候,就直接返回false了。
RLock lock = redisson.getLock("myLock");
boolean isLocked = lock.tryLock(); // 非阻塞方法,立即返回获取结果
if (isLocked) {
try {
// 执行临界区代码
} finally {
lock.unlock();
}
} else {
// 获取锁失败,处理逻辑
}
Redisson看门狗机制:
自动续租:当一个Redisson客户端实例获取到一个分布式锁时,如果没有指定锁的超时时间,Watchdog会基于Netty的时间轮启动一个后台任务,定期向Redis发送命令,重新设置锁的过期时间,通常是锁的租约时间的1/3。这确保了即使客户端处理时间较长,所持有的锁也不会过期。
续期时长:默认情况下,每10s钟做一次续期,续期时长是30s。
停止续期:当锁被释放或者客户端实例被关闭时,Watchdog会自动停止对应锁的续租任务。
不管是解锁失败了,还是解锁时抛了异常,都还是会把本地的续期任务停止,避免下次续期。
如果 watchdog 失效了,或者是说该续期但是没有按时续期,主要有以下几个可能。
1、你主动设置了超时时间,在上面的文章中我们看了源码,深入的介绍了,当你调用 Redisson 的加锁方法时,如果自己指定了超时时间,redisson 就不会再帮你续期了。
2、没能及时的执行续期动作,续期是通过时间轮在后台执行的,如果到了该执行的时候,因为种种原因,没有执行成功,比如说机器崩溃了,或者机器的 CPU 被打满了,无法执行这个动作了,都有可能导致没能及时执行续期动作。
3、执行续期失败了,还有一种情况就是续期任务执行了,但是执行的时候失败了,比如 Redis服务器挂了,网络连不上了,也可能会导致无法续期。
Redisson 在加锁的时候,会把当前线程 ID 当作 hash结构中的 filed 进行存储下来。来保证可重入锁的。 Redisson 的 unlock 方法在解锁时,会去判断当前线程 ID 是否存在于redis 的加锁的 hash 结构中,如果有则认为可以解锁,如果没有,则无法解锁。
总结一下,就是加锁的时候把线程 id 存进去,解锁的时候再校验,一致就可以解,不一致就不能解。
3. 秒杀系统
1. 库存预扣减(DECR) 2. 订单队列(LPUSH) 3. 异步处理(BRPOP)
八:redis的性能优化
Redis 的 Pipeline
pipeline机制是一种用于优化网络延迟的技术,主要用于在单个请求/响应周期内执行多个命令。在没有 Pipeline 的情况下,每执行一个 Redis 命令,客户端都需要等待服务器响应之后才能发送下一个命令。这种往返通信尤其在网络延迟较高的环境中会显著影响性能。在 Pipeline 模式下,客户端可以一次性发送多个命令到 Redis 服务器,而无需等待每个命令的响应。Redis 服务器接收到这批命令后,会依次执行它们并返回响应。所以,Pipeline通过减少客户端与服务器之间的往返通信次数,可以显著提高性能,特别是在执行大量命令的场景中。
但是,需要注意的是,Pipeline是不保证原子性的,他的多个命令都是独立执行的,Redis并不保证这些命令可以以不可分割的原子操作进行执行。这是Pipeline和Redis的事务的最大的区别。
但是他们在命令执行上有一个相同点,那就是如果执行多个命令过程中,有一个命令失败了,其他命令还是会被执行,而不会回滚的。
Jedis使用案例
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Pipeline;
public class RedisPipelineExample {
public static void main(String[] args) {
// 连接到 Redis 服务器
try (Jedis jedis = new Jedis("localhost", 6379)) {
// 创建 Pipeline
Pipeline pipeline = jedis.pipelined();
// 向 Pipeline 添加命令
pipeline.set("foo", "bar");
pipeline.get("foo");
pipeline.incr("counter");
// 执行 Pipeline 中的所有命令,并获取响应
List<Object> responses = pipeline.syncAndReturnAll();
// 输出响应
for (Object response : responses) {
System.out.println(response);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
如何遍历所有的key?
在Redis中遍历所有的key,有两种办法,分别使用KEYS命令和SCAN命令。
KEYS命令:用于查找所有符合给定模式的键,例如KEYS *会返回所有键。它在小数据库中使用时非常快,但在包含大量键的数据库中使用可能会阻塞服务器,因为它一次性检索并返回所有匹配的键。
SCAN命令:提供了一种更安全的遍历键的方式,它以游标为基础分批次迭代键集合,每次调用返回一部分匹配的键。SCAN命令不会一次性加载所有匹配的键,因此不会像KEYS命令那样阻塞服务器,更适合用于生产环境中遍历键集合。
热key问题
如果在同一个时间点上,Redis中的同一个key被大量访问,就会导致流量过于集中,使得很多物理资源无法支撑,如网络带宽、物理存储空间、数据库连接等。对于热key的处理,主要在于事前预测和事中解决。JD有一个框架叫做hotkey,他就是专门做热key检测的,他的热key定义是在单位时间内访问超过设定的阈值频次就是热key,这个阈值需要业务自己设定,并不断的调整和优化。
热key定位:实时收集、提前预测
处理热key:
多级缓存:
热key备份
热key拆分
大key问题
Big Key是Redis中存储了大量数据的Key,不要误以为big key只是表示Key的值很大,他还包括这个Key对应的value占用空间很多的情况,通常在String、list、hash、set、zset等类型中出现的问题比较多。其中String类型就是字符串的值比较大,而其他几个类型就是其中元素过多的情况。
1、影响性能:由于big key的values占用的内存会很大,所以读取它们的速度会很慢,会影响系统的性能。
2、占用内存: 大量的big key也会占满Redis的内存,让Redis无法继续存储新的数据,而且也会导致Redis卡住
3、内存空间不均匀:比如在 Redis 集群中,可能会因为某个节点上存储了Big Key,导致多个节点之间内存使用不均匀。
4、影响Redis备份和恢复:如果从RDB文件中恢复全量数据时,可能需要大量的时间,甚至无法正常恢复。
5、搜索困难:由于大key可能非常大,因此搜索key内容时非常困难,并且可能需要花费较长的时间完成搜索任务。
6、迁移困难:大对象的迁移和复制压力较大,极易破坏缓存的一致性
7、过期执行耗时:如果 Bigkey 设置了过期时间,当过期后,这个 key 会被删除,而大key的删除过程也比较耗时
怎么识别呢大key呢?
用户可以通过在终端中输入“redis-cli –bigkeys” 来获取Redis中的big key。
处理大key
1、有选择地删除Big Key:针对Big Key,我们可以针对一些访问频率低的进行有选择性的删除,删除Big Key来优化内存占用。
2、除了手动删除以外,还可以通过合理的设置缓存TTL,避免过期缓存不及时删除而增大key大小。
3、Big Key的主要问题就是Big,所以我们可以想办法解决big的问题,那就是拆分呗,把big的key拆分开:
a、在业务代码中,将一个big key有意的进行拆分,比如根据日期或者用户尾号之类的进行拆分。使用小键替代大键可以有效减小存储空间,从而避免影响系统性能
b、使用Cluster集群模式,以将大 key 分散到不同服务器上,以加快响应速度。
4、部分迁移:将大键存放在单独的数据库中,从而实现对大键的部分迁移
其他:
1避免使用 KEYS 命令获取所有 key,因为该命令会遍历所有 key,可能会阻塞 Redis 的主线程。
2避免使用 FLUSHALL 或 FLUSHDB 命令清空 Redis 数据库,因为这会清空所有数据库中的数据,而不仅仅是当前数据库。
3避免在 Redis 中存储大的数据块,因为这会导致 Redis 实例内存占用过高,影响 Redis 的性能。
4合理设置过期时间,避免过期时间设置过短或过长,导致 Redis 实例内存占用过高或数据过期失效时间不准确。
5对于写入操作频繁的数据,考虑使用 Redis 的持久化机制进行数据持久化,以保证数据的可靠性。
6避免使用 Lua 脚本中的无限循环,因为这会导致 Redis 的主线程被阻塞。
7对于需要频繁更新的数据,可以使用 Redis 的 Hash 数据结构,以减少 Redis 实例的内存占用和网络传输数据量。因为Hash可以做部分更新。
8避免在 Redis 实例上运行复杂的计算逻辑,因为这会导致 Redis 的主线程被阻塞,影响 Redis 的性能。
9对于需要高可用的 Redis 实例,可以使用 Redis Sentinel 或 Redis Cluster 进行搭建,以实现 Redis 的高可用性。
10对于需要高并发的场景,可以使用 Redis 的分布式锁机制,以避免并发访问数据的冲突。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









