







基于Q-learning的gym'Pong-v4'●'◡'●
更多代码: gitee主页:https://gitee.com/GZHzzz
博客主页: CSDN:https://blog.csdn.net/gzhzzaa
写在前面
- 作为一个新手,写这个强化学习-基础知识专栏是想和大家分享一下自己强化学习的学习历程,希望大家互相交流一起进步!在我的gitee收集了强化学习经典论文:强化学习经典论文,搭建了基于pytorch的典型智能体模型,大家一起多篇多交流,互相学习啊!
Atari Pong
- Pong是起源于1972年美国的一款模拟两个人打乒乓球的游戏,近几年常用于测试强化学习算法的性能。这篇文章主要记录如何用DQN实现玩Atari游戏中的Pong,希望大家一起交流学习!

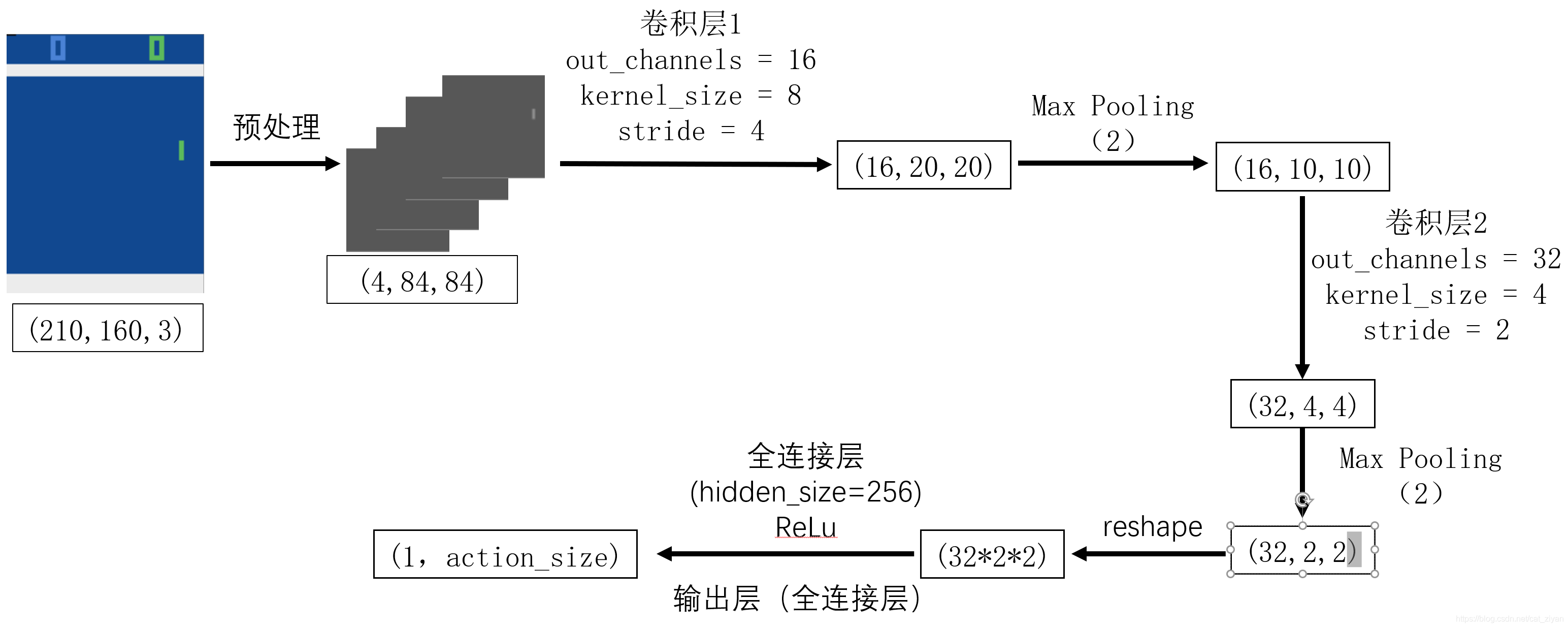
show me code, no bb
import copy
import logging
import itertools
import sys
import numpy as np
np.random.seed(0)
import pandas as pd
import gym
from gym.wrappers.atari_preprocessing import AtariPreprocessing
from gym.wrappers.frame_stack import FrameStack
import matplotlib.pyplot as plt
import torch
torch.manual_seed(0)
from torch import nn
from torch import optim
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s [%(levelname)s] %(message)s',
stream=sys.stdout, datefmt='%H:%M:%S')
env = FrameStack(AtariPreprocessing(gym.make('PongNoFrameskip-v4')),
num_stack=4)
env.env.env.unwrapped.np_random.seed(0) # set seed for noops
env.env.env.unwrapped.unwrapped.seed(0) # set seed for AtariEnv
for key in vars(env):
logging.info('%s: %s', key, vars(env)[key])
for key in vars(env.spec):
logging.info('%s: %s', key, vars(env.spec)[key])
class DQNReplayer:
def __init__(self, capacity):
self.memory = pd.DataFrame(index=range(capacity),
columns=['state', 'action', 'reward', 'next_state', 'done'])
self.i = 0
self.count = 0
self.capacity = capacity
def store(self, *args):
self.memory.loc[self.i] = args
self.i = (self.i + 1) % self.capacity
self.count = min(self.count + 1, self.capacity)
def sample(self, size):
indices = np 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











