






点击上方蓝字关注我们

计算机视觉研究院专栏
作者:Edison_G
人群计数是计算机视觉中的一项核心任务,旨在估计静止图像或视频帧中的行人数量。在过去的几十年中,研究人员在该领域投入了大量精力,并在提升现有主流基准数据集的性能方面取得了显着进展。

公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
关注并星标
从此不迷路
计算机视觉研究院

1
背景
人群计数是计算机视觉中的一项核心任务,旨在估计静止图像或视频帧中的行人数量。 在过去的几十年中,研究人员在该领域投入了大量精力,并在提升现有主流基准数据集的性能方面取得了显着进展。然而,训练卷积神经网络需要大规模和高质量的标记数据集,而注释像素级行人位置的成本高得令人望而却步。

此外,由于数据分布之间的域转移,在标签丰富的数据域(源域)上训练的模型不能很好地泛化到另一个标签稀缺域(目标域),这严重限制了现有方法的实际应用。
2
引言
最近的ICCV2021,腾讯优图出品了一个人群基数相关论文《Rethinking Counting and Localization in Crowds: A Purely Point-Based Framework》。
论文:https://arxiv.org/pdf/2107.12858.pdf

相比仅仅估计人群中的总人数,在人群中定位每个个体更为切合后续高阶人群分析任务的实际需求。但是,已有的基于定位的解决方法依赖于某些中间表示(如密度图或者伪目标框)作为学习目标,这不光容易引入误差,而且是一种反直觉的做法。

优图团队提出了一种完全基于点的全新框架,可同时用于人群计数和个体定位。针对基于该全新框架的方法,我们不满足于仅仅量化图像级别的绝对计数误差,因此研究者提出了一种全新的度量指标即密度归一化平均精度,来提供一个更全面且更精准的性能评价方案。
此外,作为该框架一个直观解法,研究者给出了一个示例模型,叫做点对点网络(P2PNet)。P2PNet忽略了所有冗余步骤,直接预测一系列人头点的集合来定位图像中的人群个体,这完全与真实人工标注保持一致。通过深入分析,研究者发现实现该方法的一个核心策略是为预测候选点分配最优的学习目标,并通过基于匈牙利算法的一对一匹配策略来完成了这一关键步骤。实验证明,P2PNet不光在人群计数基准上显著超越了已有SOTA方法,还实现了非常高的定位精度。
今天我们“计算机视觉研究院”分享另一篇《计算机协会》收录的一篇人群计数论文《Coarse to Fine: Domain Adaptive Crowd Counting via Adversarial Scoring Network》。
3
框架分析
目标域(下图顶部)和源域(下图底部)之间存在的域相似性的图示。左:一些拥挤区域在像素级别跨域相似。右图:部分源样本可能与目标样本共享相似的图像分布。

最近的深度网络令人信服地展示了人群计数的高能力,这是一项因其各种工业应用而引起广泛关注的关键任务。尽管取得了这样的进展,但由于固有的领域转移,训练有素的依赖于数据的模型通常不能很好地推广到看不见的场景。
为了解决这个问题,有研究者提出了一种新颖的对抗性评分网络 (ASNet),以逐步弥合域之间从粗粒度到细粒度的差距。具体来说,在粗粒度阶段,设计了一种双鉴别器策略,通过对抗性学习,从全局和局部特征空间的角度使源域接近目标。两个域之间的分布因此可以大致对齐。在细粒度阶段,通过基于粗阶段得出的生成概率对源样本与来自多个级别的目标样本的相似程度进行评分来探索源特征的可转移性。由这些分层分数引导,正确选择可转移的源特征,以增强适应过程中的知识传输。通过从粗到细的设计,可以有效缓解由域差异引起的泛化瓶颈。
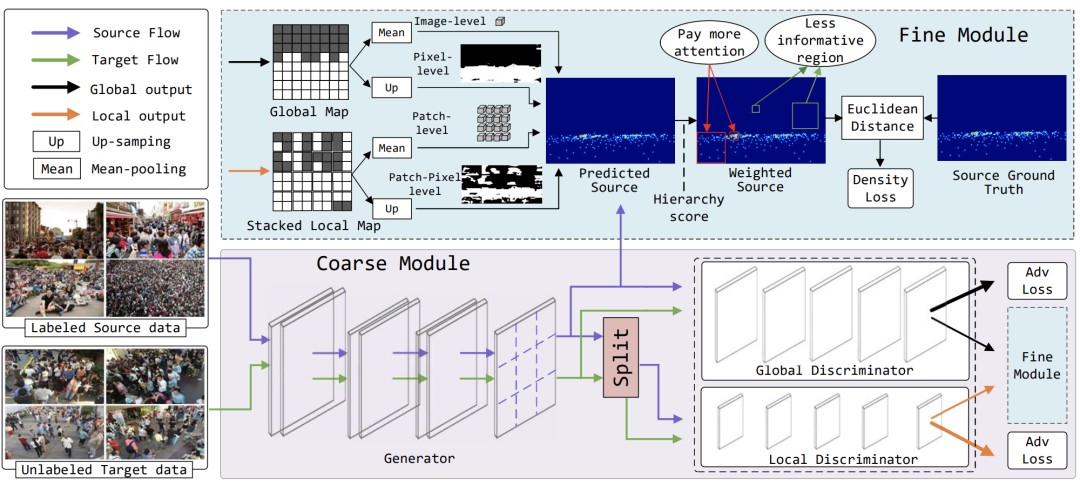
生成器将输入图像编码为密度图。然后双鉴别器将密度图分类为源域或目标域。通过生成器和双鉴别器之间的对抗训练,域分布接近。同时,双鉴别器进一步产生四种类型的分数作为信号来指导源数据的密度优化,从而在适应过程中实现细粒度转移。
4
实验及可视化

研究者考虑了从ShanghaiTech Part A到Trancos的实验,如上表所示。显然,所提出的方法比现有的适应方法提高了2.9%。


由双重鉴别器生成的不同级别(分别为像素、补丁像素、补丁、图像)级别分数的可视化。图中的正方形代表一个标量。注意白色方块代表1,黑色方块代表0。
© THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
往期推荐
????
















 3517
3517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











