







前文总结了P2PNet源码以及P2PNet-Soy源码实现方法,相关链接如下:
人群计数P2PNet论文:[2107.12746] Rethinking Counting and Localization in Crowds:A Purely Point-Based Framework (arxiv.org)
p2p人群计数源码复现过程:
crowdcountingp2p代码复现_追忆苔上雪的博客-CSDN博客
crowdcountingp2p代码复现(续)_追忆苔上雪的博客-CSDN博客
P2P大豆计数论文:https://spj.science.org/doi/10.34133/plantphenomics.0026
P2P大豆计数论文阅读:论文阅读--考虑特征水平的改进的基于田间的大豆种子计数和定位_追忆苔上雪的博客-CSDN博客
P2P大豆计数复现:p2p大豆计数模型_追忆苔上雪的博客-CSDN博客
现在梳理一下P2PNet-Soy原理
1.P2PNet-Soy流程图
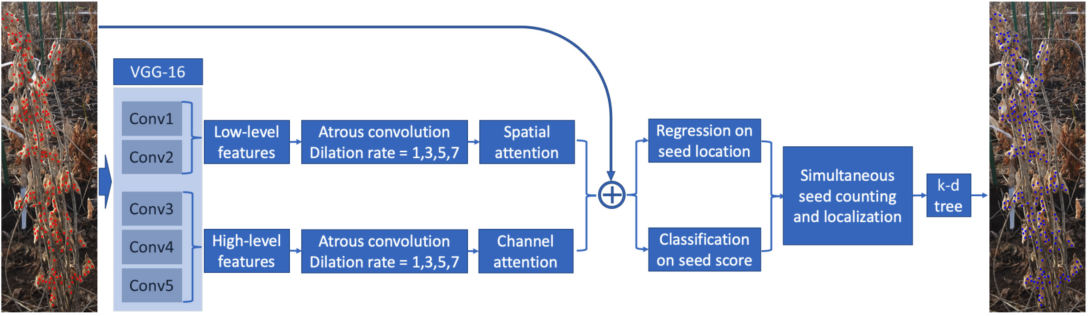
图3.VGG16是提取特征的基本框架,首先融合高层次和低层次特征,并将其添加到原始图像中,以进行后续定位和计数。
2.提高模型性能的几种策略
(1)使用k-d树这一无监督聚类算法,用于找到大豆种子位置相近的预测中心,提高最终预测的准确性; (Physically based rendering: From theory to implementation, Pharr M, et al.)
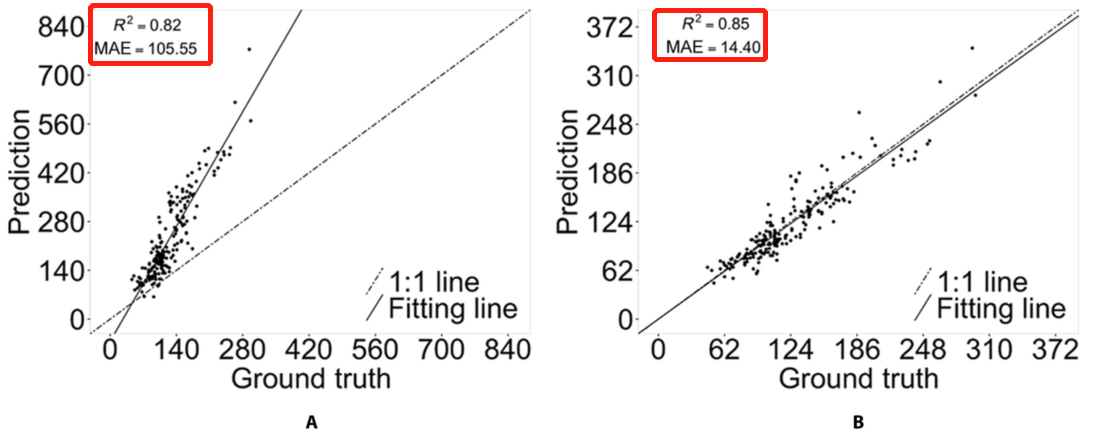
图4.原始P2PNet的性能。(A) 没有k-d树后处理。(B) 用k-d树对大豆种子进行后处理,对单株进行计数。
其中1:1line代表1:1对角线,Fitting line代表最小最小二乘拟合线;

,
≤1,且
越接近1越好!

原始P2PNet无法去除这些紧密定位的预测(图5A),导致这些种子的相应真实位置周围出现密集的“crowded”。通过直接应用k-d树作为后处理过程,MAE的值急剧下降至14.40,并与它们的人工标注具有0.85的改进相关性(图4B)。然而,在这些预测中遗漏了一些尺寸较大的种子(图4)。

图5.在从测试数据集中随机选择的单个植物上预测大豆种子数量时,原始P2PNet(A)未经后处理和(B)经后处理之间的比较。虚线框中的图像在实心框内的图像部分中进行缩放。
(2)利用高级特征和低级特征的组合充分探索大豆种子计数的模型潜力;
高级特征包含全局上下文感知信息( global-context-aware information)
低级特征可以捕捉到更详细的空间结构信息(spatial structural information)
(Pyramid feature attention network for saliency detection. Zhao T, et al.)
(3)使用膨胀率为1、3、5和7的空洞卷积(atrous convolution )来覆盖不同级别特征上的不同感受野,从而获得
尺度不变特征,以应对种子大小的变化。
(4)应用空间注意力(spatial attention)来降低低层次特征的噪声水平,并采用通道注意力(channel
attention)来突出大豆种子的语义信息。利用空间和通道注意力有效地对目标种子与其背景之间的边界信息进行优先级排序,从而获得更好的计数性能。
(5)直接将原始图像作为参考,将整个框架格式化为残差学习,以提高模型性能。
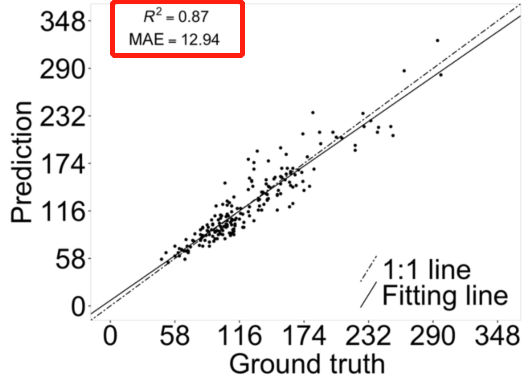
图6. P2PNet-Soy大豆在预测大豆单株种子数量方面的性能。

图7.通过所提出的P2PNet-Soy模型预测大豆种子的一个例子。右侧虚线框中的图像是左侧图像的实心框内的图像的放大部分。
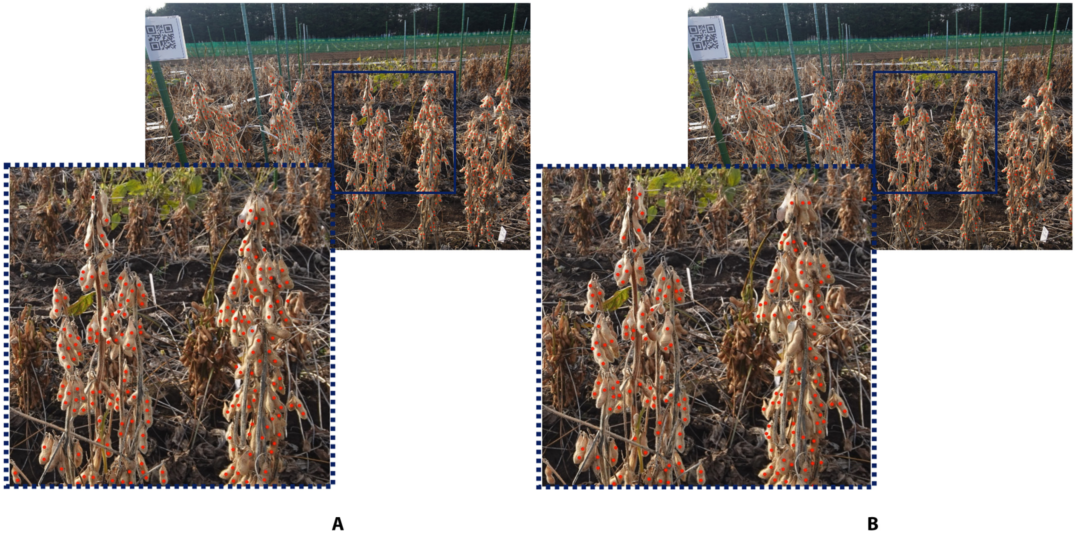
图8. 优化的P2PNet大豆模型(A)和原始P2PNet模型(B)与随机选择的现场图像的后处理的比较。虚线框中的图像在实心框内的图像部分中进行缩放。
3.P2PNet-Soy消融实验
尽管性能有所改善,但所提出的P2PNet-Soy模型仍然高度依赖于后处理,因此进行了消融研究,以进一步阐述每种策略的不同贡献,见下表
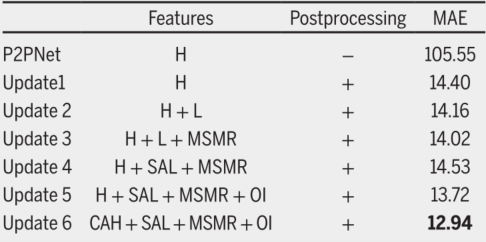
表中:
H代表高级特征high-level features: VGG16-conv3, VGG16-conv4, and VGG16-conv5;
L代表低级特征low-level features: VGG16-conv1 and VGG16-conv2;
SAL代表低级特征空间注意力spatial attention on low-level features;
CAH代表高级特征的通道注意力channel-wise attention on high-level features;
MSMR代表多尺度多感受野特征提取;
OI代表原始图original image;















 1434
1434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









