






关注并星标
从此不迷路
计算机视觉研究院


公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
计算机视觉研究院专栏
作者:Edison_G
本文主要讲解几个部分,(适合一些在读的研究生啥也不会然后接到一些项目无从下手,如果是大佬的话就可以跳过了)先看看网络摄像头的效果吧(在2060的电脑上运行 )
转自《知乎——kaka》

实践时间Pipeline
2021年9月18日,在github上发布了一套使用ONNXRuntime部署anchor-free系列的YOLOR,依然是包含C++和Python两种版本的程序。起初我是想使用OpenCV部署的,但是opencv读取onnx文件总是出错,于是我换用ONNXRuntime部署。
YOLOR是一个anchor-free系列的YOLO目标检测,不需要anchor作为先验。本套程序参考了YOLOR的官方程序(https://github.com/WongKinYiu/yolor), 官方代码里是使用pytorch作为深度学习框架的。根据官方提供的.pth文件,生成onnx文件后,我本想使用OpenCV作为部署的推理引擎的,但是在加载onnx 文件这一步始终出错,于是我决定使用ONNXRuntime作为推理引擎。在编写完Python版本的程序后, 在本机win10-cpu环境里,在visual stdio里新建一个c++空项目,按照csdn博客里的文章讲解来配置onnxruntime, 配置的步骤跟配置Opencv的步骤几乎一样。在编写完c++程序后,编译运行,感觉onnxruntime的推理速度要比 opencv的推理速度快,看来以后要多多使用onnxruntime作为推理引擎了,毕竟onnxruntime是微软推出的专门针对 onnx模型做推理的框架,对onnx文件有着最原生的支持。本套程序里的onnx文件链接:https://pan.baidu.com/s/1Mja0LErNE4dwyj_oYsOs2g,提取码:qx2j
Github地址是:https://github.com/hpc203/yolor-onnxruntime

9月19日,在github上发布了一套使用深度学习算法实现虚拟试衣镜,结合了人体姿态估计、人体分割、几何匹配和GAN,四种模型。仅仅只依赖opencv库就能运行,除此之外不再依赖任何库。源码地址是:https://github.com/hpc203/virtual_try_on_use_deep_learning
这套程序只有Python版本的,我在本地编写了C++程序,但是输出结果跟Python版本的输出结果始终不一致, 对于这个bug我还没有找到原因,因此我在github只发布python程序的。程序启动运行之后,要等几秒种后才能弹窗显示结果, 程序运行速度慢的问题还有待优化。

10月17日,在github上发布了使用OpenCV部署SCRFD人脸检测,依然是包含C++和Python两种版本的程序实现。SCRFD是一个FCOS式的人脸检测器,2021年5月在insightface仓库里发布的,它也是检测人脸矩形框和5个关键点。我发布在github上的源码地址是:https://github.com/hpc203/scrfd-opencv

11月6日,在github发布了使用OpenCV部署libface人脸检测和SFace人脸识别,包含C++和Python两种版本的程序,仅仅只依赖OpenCV库就能运行。源码地址是:https://github.com/hpc203/libface-sface_detect-recognition-opencv

人脸检测和人脸识别模块是由人脸识别领域的两位大牛设计的, 其中人脸检测是南科大的于仕琪老师设计的,人脸识别模块是北邮的邓伟洪教授设计,其研究成果SFace发表在图像处理顶级期刊IEEE Transactions on Image Processing。人脸检测示例程序在opencv-master/samples/dnn/face_detect.cpp里,起初我在win10系统里,在visual stdio 2019 里新建一个空项目,然后把opencv-master/samples/dnn/face_detect.cpp拷贝进来作为主程序,尝试编译,发现编译不通过。仔细看代码可以发现face_detect.cpp里使用了类的继承和虚函数重写,这说明依赖包含了其他的.cpp和.hpp头文件的。因此我就编写一套程序, 人脸检测和人脸识别程序从opencv源码里剥离出来,只需编写一个main.cpp文件,就能运行人脸检测和人脸识别程序。于仕琪老师设计的libface人脸检测,有一个特点就是输入图像的尺寸是动态的,也就是说对输入图像不需要做resize到固定尺寸,就能输入到神经网络做推理的,此前我发布的一些人脸检测程序都没有做到这一点,而且模型文件.onnx只有336KB。因此,这套人脸检测模型是 非常有应用价值的。在下载完代码之后,在visual stdio 2019里新建一个空项目,配置opencv,然后把main.cpp和weights文件拷贝进去,接下来编译运行就可以了。

12月12日,我在github发布了使用OpenCV部署faster-rcnn检测证件照,包含C++和Python两种版本的程序,仅仅只依赖opencv库就能运行。源码地址是:https://github.com/hpc203/faster-rcnn-card-opencv

12月18日,我在github发布了使用ONNXRuntime部署PicoDet目标检测,包含C++和Python两个版本的程序,源码地址是:https://github.com/hpc203/picodet-onnxruntime
起初,我是想使用opencv部署PicoDet目标检测的,但是opencv的dnn模块读取.onnx文件失败了。于是只能使用onnxruntime部署了。12月28日,我在github发布了使用OpenCV部署NanoDet-Plus,包含C++和Python两个版本的程序;使用ONNXRuntime部署NanoDet-Plus,包含C++和Python两个版本的程序。源码地址是:https://github.com/hpc203/nanodet-plus-opencv

2022年1月16日,我在github发布了使用ONNXRuntime部署人脸动漫化——AnimeGAN,包含C++和Python两个版本的代码实现,源码地址是https://github.com/hpc203/AnimeGAN-onnxruntime
1月21日,我在github发布了使用OpenCV部署ByteTrack目标跟踪,包含C++和Python两个版本的程序。使用ONNXRuntime部署ByteTrack目标跟踪,包含C++和Python两个版本的程序。源码地址是:https://github.com/hpc203/bytetrack-opencv-onnxruntime
1月28日,我在github发布了使用OpenCV部署yolov5检测车牌和4个角点,包含C++和Python两个版本的程序。使用ONNXRuntime部署yolov5检测车牌和4个角点,包含C++和Python两个版本的程序。程序会输出车牌的水平矩形框的左上和右下顶点的坐标(x,y),车牌的4个角点的坐标(x,y)。源码地址是https://github.com/hpc203/yolov5-detect-car_plate_corner

2月7日,在github发布了使用ONNXRuntime部署yolov5-lite目标检测,包含C++和Python两个版本的程序,源码地址是https://github.com/hpc203/yolov5-lite-onnxruntime
2月17日,在github发布了使用OpenCV部署多任务的yolov5目标检测+语义分割,包含C++和Python两个版本的程序。使用ONNXRuntime部署多任务的yolov5目标检测+语义分割,包含C++和Python两个版本的程序。源码地址是https://github.com/hpc203/multiyolov5-opencv-onnxrun
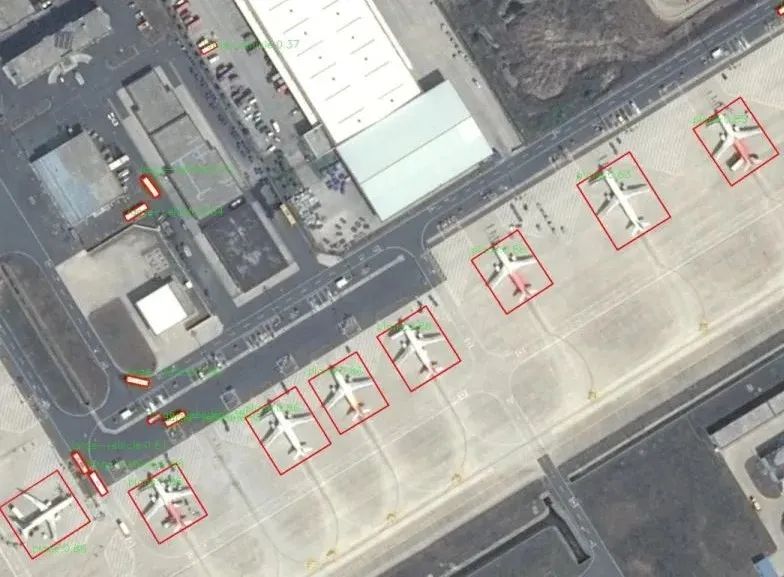
2月19日,在github发布了使用OpenCV部署yolov5旋转目标检测,包含C++和Python两个版本的程序。使用ONNXRuntime部署yolov5旋转目标检测,包含C++和Python两个版本的程序。源码地址是https://github.com/hpc203/rotate-yolov5-opencv-onnxrun
在编写这套程序的过程中,发现在python程序里,opencv的dnn模块提供了现成的计算旋转矩形框的NMS函数cv2.dnn.NMSBoxesRotated。但是在C++程序里,opencv的dnn模块提供现成的计算旋转矩形框的NMS函数NMSBoxesRotated。因此在C++程序里,需要自己编写实现计算旋转矩形框的NMS函数。经调研发现opencv库里有表示旋转矩形框的结构体RotatedRect,也有计算两个旋转矩形框的交叠区域和交叠面积的函数rotatedRectangleIntersection和contourArea,最终编写完成了计算旋转矩形框的NMS函数。附上一张C++程序的运行结果图:
© THE END
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
往期推荐
🔗
















 1258
1258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











