






关注并星标
从此不迷路
计算机视觉研究院


公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
代码地址:https://github.com/jameelhassan/PoseEstimation
计算机视觉研究院专栏
作者:Edison_G
在 AI 绘画领域,很多研究者都在致力于提升 AI 绘画模型的可控性,即让模型生成的图像更加符合人类要求。前段时间,一个名为 ControlNet 的模型将这种可控性推上了新的高峰。大约在同一时间,来自阿里巴巴和蚂蚁集团的研究者也在同一领域做出了成果,本文是这一成果的详细介绍。
人体姿态估计(HPE)是计算机视觉中的一项经典任务,其重点是通过识别人的关节位置来表示人的方位。HPE可以用来理解和分析人类的几何和运动相关信息。Newell等人在[Stacked hourglass networks for human pose estimation. In European conference on computer vision, pages 483–499]中提出的堆叠沙漏结构是第一种引人注目的基于深度学习的HPE方法之一,因为在此之前,经典方法主导了HPE文献。在这项工作中,利用重复的自下而上和自上而下的处理来捕获来自不同尺度的信息,并引入中间监督来迭代地细化每个阶段的预测。与当时最先进的方法相比,这大大提高了准确性。
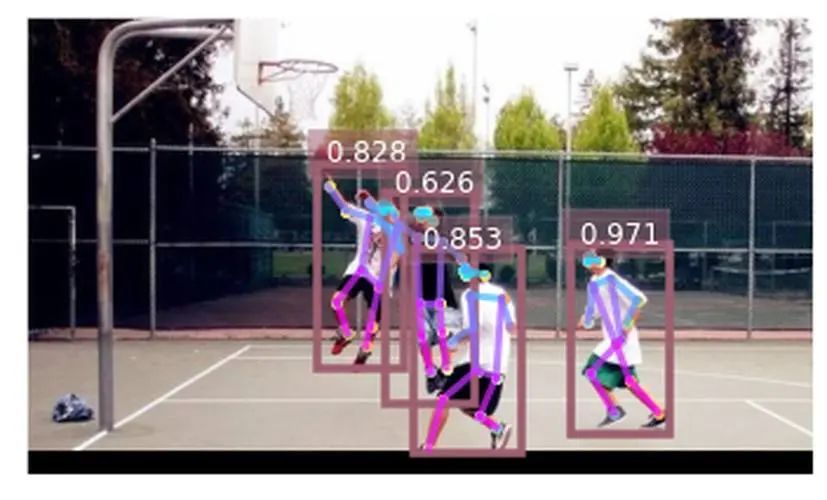
然而,HPE是一个实时应用程序,因为它经常被用作另一个模块的前身。因此,在这种情况下,关注计算效率是至关重要的。在这项研究中,研究者对堆叠沙漏网络进行了架构和非架构修改,以获得一个既准确又计算高效的模型。在下面的内容中,研究者提供了对基线模型的简要描述。
原始架构由多个堆叠的沙漏单元组成,每个沙漏单元由四个下采样和上采样级别组成。在每个级别上,下采样是通过残差块和最大池化操作来实现的,而上采样是通过残留块和最近邻插值来实现的。这个过程确保了模型捕捉到局部和全局信息,这对于连贯地理解全身以获得准确的最终姿态估计非常重要。在每次最大池化操作之后,网络分支,以预池化分辨率通过另一个残差块应用更多卷积,其结果作为跳跃连接添加到沙漏的后半部分中的相应上采样特征图。模型的输出是每个关节的热图,该热图对每个像素处存在关节的概率进行建模。预测每个沙漏之后的中间热图,并在其上应用损失。此外,这些预测被投影到更多的通道,并作为后续沙漏的输入,以及当前沙漏的输入及其特征图输出。
设计选择
Depthwise Separable Convolutions
深度可分离卷积取代了传统的卷积,以减少卷积运算的参数数量。这是通过使用卷积在空间上单独在信道上分割卷积来执行的,然后通过逐点卷积聚合信道信息,如下图所示:

Dilated Convolution
下面方程中描述的扩张卷积是规则卷积运算的一种变体,其具有在不损失分辨率或覆盖率的情况下指数增加感受野的能力,就像池化运算的情况一样。

Ghost Bottleneck
[Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition]提出的Ghost瓶颈还通过不同地分割卷积来降低卷积运算的计算复杂度。为了产生固定数量的信道,Ghost瓶颈使用规则卷积输出一小部分信道,其余信道通过更便宜的线性运算产生,如下图所示。这些被级联和卷积以输出所需数量的信道。

DiCE Bottleneck
高效网络的维度卷积(DiCE)单元是Mehta等人提出的一种卷积单元,它折衷了维度卷积和维度融合。卷积运算应用于三个输入维度(宽度、高度和深度)中的每一个。为了沿着这些维度中的每个维度组合编码信息,使用有效的融合单元来组合这些表示。因此,DiCE单元可以有效地捕获沿着空间维度和信道维度的信息。
Shuffle Bottleneck
[Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE conference on computer vision and pattern recognition]中首次提出的混洗单元使用逐点群卷积和信道混洗来提高计算效率并保持准确性。

Perceptual Loss
感知损失用于比较具有微小差异的相似图像。在这里,我们将其用作两个图像之间的特征水平均方误差(MSE)损失,该损失在高级特征图而不是原始图像空间处计算损失。这里的假设是,如果让第一个沙漏“感知”第二个沙漏在高特征水平上“感知”的东西,网络的整体性能就会提高。下方程中所示的总损失由感知损失和原始预测损失组成,其中预测损失具有更高的权重。
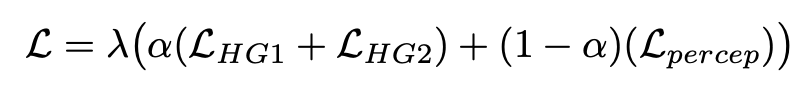
Residual connection
研究者还将现有的残差连接添加替换为级联的残差连接,然后进行逐点卷积,以获得所需数量的信道,称为ResConcat。还包括从沙漏(颈部)的最窄特征图到下一个沙漏颈部的残差连接,称为NarrowRes。
实验
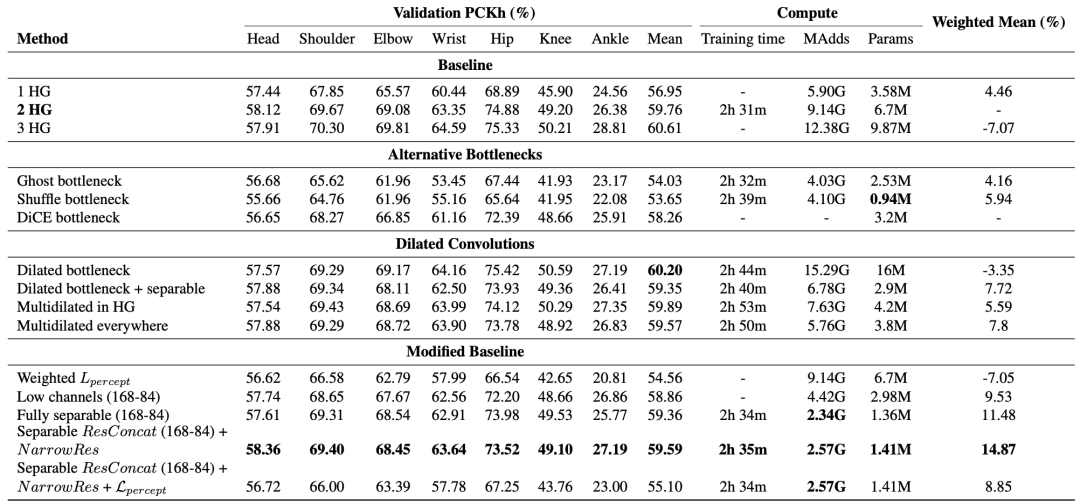
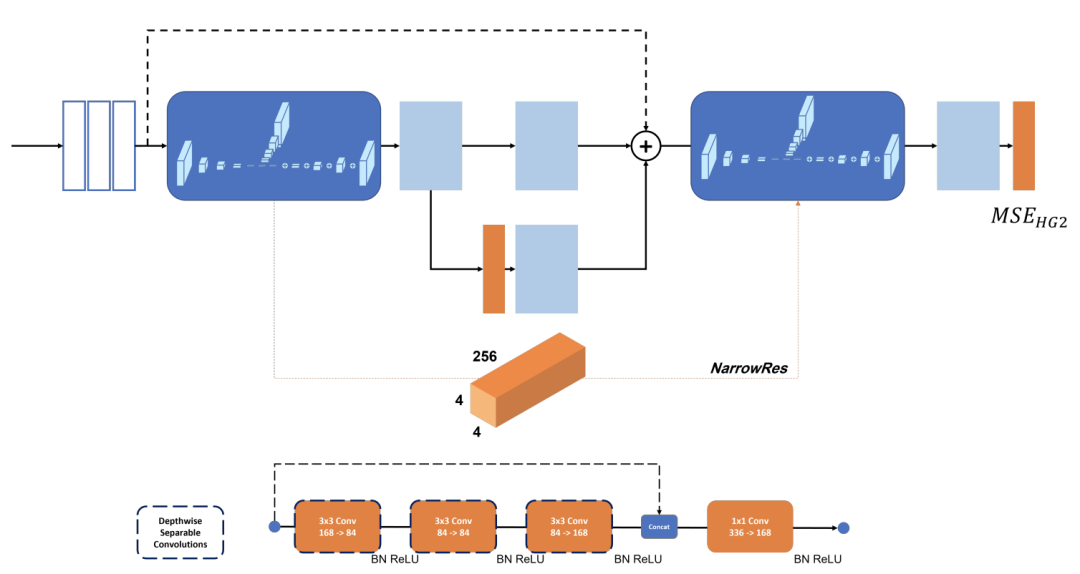
Architecture of the best model
© The Ending
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
往期推荐
🔗
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











