






点击蓝字 关注我们
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式
计算机视觉研究院专栏
Column of Computer Vision Institute
识别交通标志是智能驾驶系统环境感知技术的重要组成部分。在现实应用中,交通标志识别很容易受到光照强度、极端天气和距离等变量的影响,这增加了智能车辆的安全风险。

01
前景概要
为了克服这些挑战,我们提出了一种基于YOLOv4-MINI的中国交通标志检测算法。在主干特征提取网络中添加了一个改进的轻量级BECA注意机制模块,在增强的特征提取网络上添加了一种改进的密集SPP网络。在检测层中添加了yolo检测层,并使用k-means+聚类来获得更适合交通标志检测的先验框。改进后的算法在CCTSDB 2021数据集上进行了测试和评估,其检测准确率为96.62%,召回率为79.73%,F-1评分为87.37%,mAP值为92.77%,优于原始YOLOv4微小网络,FPS值保持在81 F/s左右。因此,该方法可以提高复杂场景下交通标志识别的准确性,满足智能车辆对交通标志识别任务的实时性要求。

02
背景&动机
交通标志识别是智能汽车驾驶系统的重要组成部分,也是计算机视觉中最重要的研究领域之一。交通标志识别任务通常在自然场景中执行;然而,极端天气条件(如雨、雪或雾)会使交通标志信息模糊不清,过度暴露和光线昏暗通常会降低交通标志的能见度。此外,交通标志全年暴露在外,导致一些标志的表面褪色、不清晰或损坏。复杂多变的环境往往会影响智能交通中交通标志识别的速度和准确性。因此,研究复杂环境下快速准确的交通标志检测问题显得尤为重要。
为了加快基于深度卷积神经网络的交通标志检测方法的检测时间,现在使用基于轻量级卷积神经网络目标检测架构来识别交通标志。关于检测速度,YOLOv4 tiny是一种优越的目标检测模型,其性能优于目前绝大多数复杂的深度卷积神经网络模型。然而,YOLOv4微小算法的检测精度相对较低。我们就提出了一种基于增强型YOLOv4-MINI的中国交通标志检测算法,该算法可以更有效地促进不同级别信息的传输和共享,通过优化网络来提高算法的检测精度并确保其检测速度。

03
新框架简介
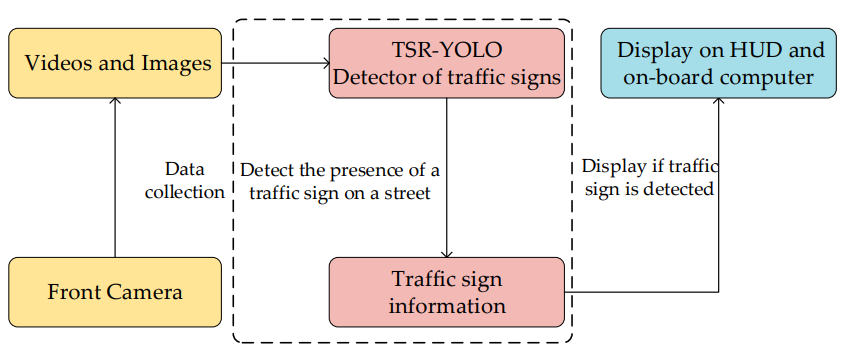
我们的研究展示了一个智能车辆交通标志视觉感知系统,该系统包括三个主要部分:视觉系统、交通标志检测系统和智能汽车显示系统。更具体地说,基于单目摄像机的视觉系统以视频或图像的形式捕捉车辆行驶道路环境中的信息,然后将信息传递给交通标志检测器,交通标志检测器通过视觉系统给出的视频序列检测行驶环境中是否存在交通标志。如果交通标志信息是在道路环境中捕获的,则会显示在HUD平板显示器上。交通标志检测系统的职责是检测驾驶环境中是否存在交通标志。它是识别交通标志系统的一个关键组成部分。因此,需要努力开发一种能够在复杂的道路环境中快速准确地检测交通标志的系统。下图说明了交通标志识别系统的工作流程。
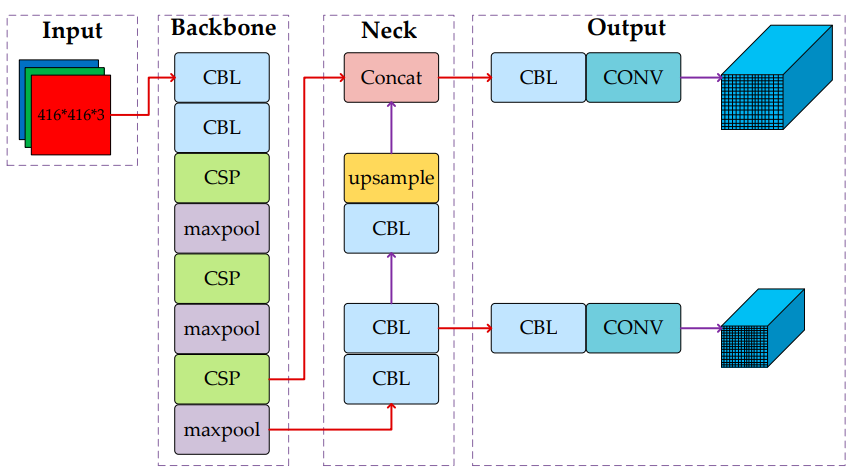
YOLOv4 tiny是YOLOv4的缩小版。其主要思想是将目标检测任务视为一个回归问题,通过网络模型回归直接获得检测到的目标位置和分类结果。下图描述了YOLOv4 tiny的网络结构。YOLOv4微型网络分为三个部分:主干(CSP-Marknet53-tiny)、颈部(特征金字塔网络,FPN)和Yolo检测头。
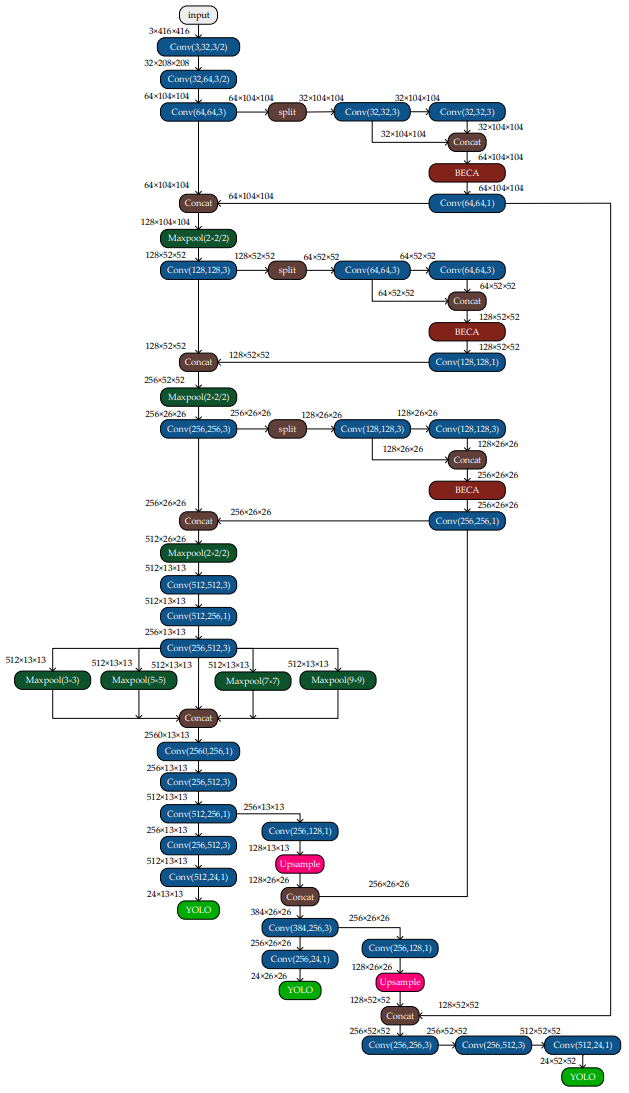
以下是最终的网络可视化:

04
实验及项目效果
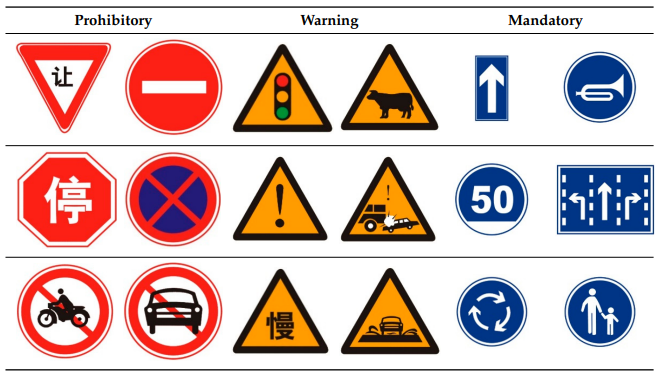
下表,CCTDB2021数据集中的交通标志根据其各自的含义分为三类:禁止标志、警告标志和强制标志。禁止标志有白色背景、红色圆圈、红色条和黑色图案,它们的形状是圆形、八边形或等边三角形,顶角向下。警告标志有黄色背景、黑色边框和黑色图案,其形状为等边三角形,顶角向上。强制性标志有蓝色背景和白色图案,它们的主体由圆形、矩形或正方形组成。该数据集的训练集有16356张图像,包括13876个禁止标志、4598个警告标志和8363个强制性标志。该数据集的测试集由1500张图像组成,整个测试集有3228个交通标志。按照9:1的比例,将训练集分为训练集和验证集。







© THE END

转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

往期推荐
🔗

















 407
407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









