







摘要
得益于在通道或空间位置之间建立相互依赖性的能力,注意力机制最近被广泛研究并广泛应用于各种计算机视觉任务中。这篇文章中,我们研究了重量轻但有效的注意力机制,并提出了三重注意,一种新的方法来计算注意权重,通过捕捉交叉维度的相互作用使用三分支结构。对于一个输入张量,三重注意力通过旋转操作和剩余变换建立了维度间的依赖关系,并以可以忽略的计算开销对通道间和空间信息进行编码。我们的方法即简单有高效,可以作为附加模块轻松插入经典骨干网络,我们证明了我们的方法在各种具有挑战性的任务上的有效性,包括ImageNet-1k上的图像分类和在MSCOCO和PASCAL VOC数据集上的目标检测。此外,我们通过直观的检查GradCAM和GradCAM++结果,对三重注意的表现提供了广泛的见解。对我们方法的经验评估,支持了我们的想法,也就是计算注意力权重的时候捕捉跨维度依赖关系的重要性。
介绍
经过多年的计算机视觉研究,深度不断增加的卷积神经网络体系结构已经在很多计算机视觉任务中取得了重大成功。许多最新的工作提出了使用通道注意力或空间注意力,或两者都使用来改善这些神经网络的性能。这些注意力机制具有通过明确地建立信道之间的依赖性或用于空间注意力的加权空间掩码来改善由标准卷积层生成的特征表示的能力。学习注意力权重背后的直觉是让网络有能力学习在哪里参加,并进一步关注目标对象。
最突出的方法之一是Squeeze-and-Extraction Network,挤压和激励模块计算通道关注度,并以相当低的成本提供增量性能增益。再然后就是CBAM和BAM模块,都尝试将空间注意力和通道注意力结合在一起来提供鲁棒的代表性注意。它们以较小的计算开销提供相对于SENet显著的性能提升。
与上述需要大量而外可学习参数的关注方法不同,本文的基础主旨是研究在保持相似或提供更好性能的同时构建廉价但有效的关注的方法。特别是,我们旨在强调在计算注意力权重以丰富的特征表示时捕捉跨维度交互的重要性。我们从CBAM的计算注意力的方法中得到启发,该方法成功的证明了捕捉空间注意力和通道注意力的重要性。在CBAM除了使用全局平均池化(GAP)和全局最大池化(GMP)之外,信道关注度的计算方式与SENet类似,而空间关注度是通过简单地将输入减少到单个信道输出以获得关注度权重来产生的。我们观察到CBAM中的通道关注方法虽然提供了显著的绩效改进,但没有考虑到我们展示的对绩效产生有利影响的跨维度互动。此外CBAM在计算信道关注度时引入了降维,这对于捕获信道之间的非线性局部相关性是多余的。
基于以上的观察,在本文中,我们提出了三重注意,它有效的解释了跨维度的相互作用。三元注意由三个分支组成,每个分支负责捕捉输入的空间维度和通道维度之间的交叉维度。给定一个具有形状(C x H x W)的输入张量,每个分支负责聚集空间维度H或W与通道C之间的交叉维度交互特征。我们通过简单地置换每个分支中的输入张量,然后将张量通过一个Z池,随后是核心大小为kxk的卷积层来实现这一点。然后,注意力权重由sigmod激活层生成,然后在将其置换回原始输入形状之前,应用于置换后的输入张量。
与以前的通道注意力机制相比,我们的方法有两个优点。首先,我们的方法有助于以可忽略的计算开销捕获丰富的区分特征表示,我们通过Grad-CAM和Grad-CAM++的结果进一步根据经验验证了这一点。第二,与我们的前辈不同,我们的方法强调不降维的跨维度交互的重要性,从而消除了通道和权重的间接对应。
我们展示了这种跨分支并行计算注意力的方法,同时考虑跨维度依赖在计算方面非常有效和便宜。例如,对于参数为25.557兆和4.122千兆位的ResNet-50 [12],我们提出的插件三重注意分别导致参数增加4.8K和4.7e-2千兆位,同时提供了2.28%的前1名准确性提高。我们在ImageNet-1k [7]上评估了我们的方法,在PASCAL VOC [8]和MS COCO [22]上评估了我们的分类和对象检测方法,同时通过分别可视化Grad-CAM [28]和GradCAM++ [3]输出,对我们的方法的有效性提供了广泛的见解。
相关工作
人类感知中的注意力涉及选择性地集中与给定信息的一部分而忽略其余部分的过程。这种机制有助于提炼感知信息,同时保留其上下文。再过去的几年里,一些研究方法已经在CNN中有效的结合这种注意力机制,以提高大规模视觉任务的性能。在这一小节中我们将对注意力机制进行回顾。
残差注意力网络(Residual Attention Network)提出了一种trunk-and-mask(主干和掩码)以及 encoder-decoder(编码器解码器)风格的模块,用来生成鲁棒的三维注意力图。随后引入了挤压和激励网络(SENet)。正如许多人争论的那样,这是第一个成功实现有效channle注意力的方法,同时提供性能的提高。SE之后是CBAM然后是双注意力网络A2-Nets,包括NL块非局部块引入一种新的关系函数。
NL块的引入是为了通过非本地操作捕获远程依赖性,并且被设计为轻量级的,易于在任何体系结构中使用。全局二阶池化网络(GSoP-Net)使用了二阶池化来实现丰富的功能聚合。其关键思想是使用二阶池化从整个输入空间中收集重要特征,并随后对它们进行分布,以使更多层更容易识别和传播。Global-Context Network(GC-Net)提出了一种新的None local块整合到SEblock中,可以更有效的将上下文表示与通道权重结合的更好。与SENet中简单的下采样不同,GC-Net使用一组复杂的基于置换的操作来减少映射特征,然后将其传递给SE块。
注意力机制也被成功的用于图像分割。CCNet(Criss-Cross Networks)和SPNet提出了一种新的注意力模块用来捕捉更丰富的上下文语义使用交叉带。萧等人提出了一种集成一个自底向上和两个自顶向下注意的流水线,用于细粒度图像分类。曹等人介绍了"Look and Think Twice"机制,该机制基于一种受人类视觉皮层启发的计算范阔过程,有助于在扭曲背景条件下捕捉目标对象的视觉注意力。
上述大多数方法都有我们在方法中解决的显著缺点。我们的三重注意力模块旨在捕捉跨维度交互,并且与上述方法中,它们都没有考虑跨维度交互,同时允许某种形式的降维,对于捕捉跨通道交互式不必要的。
在本节中,我们首先重温CBAM,并分析诊断CBAM通道注意力模块中共享MLP结构的效率。在这里我们展示了跨维度依赖的重要性,并进一步将我们的方法的复杂性与其他标准的注意力进行比较。最后将我们的方法的复杂性与其他标准的进行了比较。最后,我们展示了如何将三重注意力调整到标准深度CNN框架中,以应对计算机视觉领域的不同挑战任务。
3.1 重新学习一下CBAM的通道注意力机制
在这一小节中,我们首先回顾一下CBAM中使用的channel attention模块,我们假设X ∈ R(CxHxW)是卷积层的输出以及CBAM通道注意力模块的后续输入,其中C、H和W分别代表Channel数,高度和宽度。CBAM的channel Attention可以表示为如下式子:
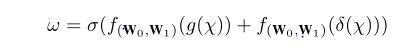
在这个公式里面 w(欧米伽) ∈ R(Cx1x1) 代表的是学习到的通道注意力权重,这就是接下来要被用做的X。g(x)是全局平均池化GAP 方程的写法是:
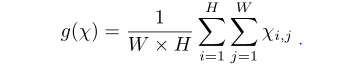
δ(χ)代表的是全局最大池化(GMP)方法,写法是如下:
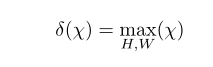
这两种池化功能构成了CBAM空间特征聚集的两种方法。符号σ代表的是sigmod激活函数。f(W0,W1)(g(χ)) 和f(W0,W1)(δ(χ))是两种变形。因此,在扩展f(W0,W1)(g(χ)) 和f(W0,W1)(δ(χ)),我们计算出了接下来的w(欧米伽):
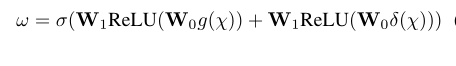
其中ReLU代表了矫正线性单位,其中W0和W1代表权重矩阵,其大小分别定义为Cx(C/r) 和 (C/r)xC。这里r代表的是MLP网络的bottleneck中负责维度减少的缩减率。当r越大,计算复杂度越低,反之亦然。需要注意的是,MLP的权重:W0和W1在CBAM中共享: g(χ) and δ(χ).将信道描述符投影到一个低维度哦空间,然后将他们映射回去,由于间接的权重-通道对应关系,导致信道间关系的损失。
3.2 Triplet Attention
就如第一节所示,本文的目标是研究如何在不涉及任何降维的情况下,对廉价但有效的渠道关注度进行建模。在这一小节中,不同于CBAM和SENet需要一定数量的可学习参数来建立通道间的相互依赖性,我们提出一种几乎无参数的注意力机制来模拟通道注意力和空间注意力,也就是三重注意力。
概述:提议的三重注意的图表可以在图3中找到,顾名思义,三重注意力由三个平行的分支组成,其中两个负责捕捉通道维度C和空间维度H或W之间的跨维度相互作用,剩余的最后一个分支类似于CBAM,用于建立空间注意,所有的三分之一的输出通过简单的平均进行汇总。在下文中,在具体描述所提出的三重注意力之前,我们首先介绍构建跨维度交互的直觉。
跨维度交互:计算通道注意力的传统方法包括计算singular权重,通常是输入张量中每个通道的标量,然后使用奇异权重统一缩放这些特征映射。虽然这个计算通道注意力的过程被证明是非常轻量级的和非常成功的,但是在考虑这种方法有一个重要的确实。为了计算这些通道的奇异权重,通过执行全局平均池化,输入张量被空间分解为每一个通道一个像素。这导致了空间信息的主要损失,因此当计算对这些单像素通道的关注时,通道尺寸和空间尺寸之间的相互依赖性不存在。CBAM引入了空间注意作为通道注意力的补充模块,简而言之,空间注意力告诉’通道的什么地方聚焦’,通道注意力告诉’聚焦在哪个通道’。然而,这个过程的缺点是通道注意力和空间注意力是分离的,并且彼此独立地计算。因此不考虑两者之间的任何关系。受到建立空间注意力方式的启发,我们提出了跨维度交互的概念,通过捕捉输入张量的空间维度和通道维度之间的交互来解决这个缺点。我们在三重注意力中引入了跨维度相互作用,通过三个分支分别获得张量(C,H)、(C,W)和(H,W)维之间的依赖关系。

图3 三重注意力的图解,它由三个分支。顶部分支负责计算跨通道维度C和空间W的注意力权重,中间捕捉的是C和H之间的权重,类似的底部分支获取的是H和W的空间相关性。在前两个分支中,我们采用旋转操作来建立通道维度与空间维度中的任一个之间的连接,最后通过简单的平均来合计权重。
Z-pool : 这里的Z池化层负责将第0个维度缩减为两个维度,方法是将该维度上的平均池化和最大池化要素串联起来。这使得该层能够保留实际张量的丰富表示,同时缩小其深度,以使进一步的计算变得轻量级。在数学上可以用如下公式:
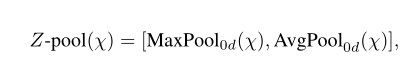
其中0d是发生最大和平均池化的操作的第0维度。例如,一个形状张量为(CxHxW)最后可以生成一个形状张量(2xHxW)的张量。
Triplet Attention:给定上述定义的操作,我们将三重注意定义为一个三分支模块,它接受一个输入张量并输出一个相同形状的细化张量。给定一个输入张量X ∈ R(CxHxW),我们首先把它传递给提出三重注意模块中的每一个。在第一个分支中,我们构建了高度维度和通道维度之间的交互。为此,输入X沿着H轴逆时针旋转90度。这个旋转张量表示为形状(WxHxC),X1然后通过一个Z-pool,随后被简化为形状为(2 x H x C) ,X1然后通过内核大小为7X7的标准卷积层,随后就是批量归一化层,其提供维度的中间输出(1 x H x C)。然后通过张量穿过sigmod激活层(σ)来生成最终的注意力权重。随后将生成的注意力权重应用于X1,然后沿H轴顺时针旋转90°,以保持x的原始形状输入。
同样的,在第二个分支中,我们沿着W轴逆时针旋转90°。旋转张量X2可以用(H x C x W)表示,并通过一个Z池化层。因此张量被简化为形状x2为(2xCxW)。X2 通过 由核大小为k x k 定义的标准卷积层,随后是批量归一化层,其输出形状的张量(1 x C x W)。然后通过使该张量通过sigmod激活层来获得注意力权重,然后简单地应用于X2,并且输出随后沿着W轴顺时针旋转90°,以保持与输入X相同的形状。
对于最后一个分支,输入张量X的通道被Z池化为两个。然后,该形状的简化张量X3(2 x H x W)通过由核大小k定义的标准卷积层,随后是批量归一化层。输出通过sigmod激活层(σ)生成形状注意力权重(1 x H x W),然后应用于输入X。然后,由三个分支中的每一个生成的形状的精细张量(C x H x W)通过简单平均来聚集。
总之输入张量X ∈ R(C x H x W)的三重注意力中获得的精细注意力应用张量y的过程可以由以下等式表示:

其中σ代表sigmod激活函数;ψ1、ψ2和ψ3代表三重注意的三个分支中由核大小k定义的标准二维卷积层。简单的来说y可以变为:
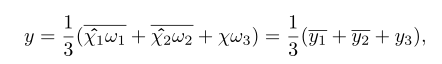
其中ω1、ω2和ω3是在三重注意中计算的三个交叉维度注意权重。等式中的y1和y2 在上述等式中,代表90°顺时针旋转以保持(C × H × W)的原始输入形状。
**复杂度分析:**在表格1中,与其他的标准注意力机制相比,我们从经验上验证了三重注意力的参数效率。C表示层的输入通道数,r表示在计算通道注意力的时候MLP瓶颈中使用的缩减率,用于2D卷积的核大小用k表示;我们表明,与我们的方法相比,不同的注意力层带来的参数开销要高得多。我们BAM的参数比较少的原因是因为在整个体系结构中用的次数比较少(只有三个)。
4.实验
这些就不需要翻译了。















 648
648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









