







一,Logistic回归
- 优点:计算代价不高,易于理解和实现。
- 缺点:容易欠拟合,分类精度可能不高。
- 适用数据类型:数值型和标称型。
主要就是利用sigmoid函数
σ(z)=11+exp−z
的特点,如下图所示:
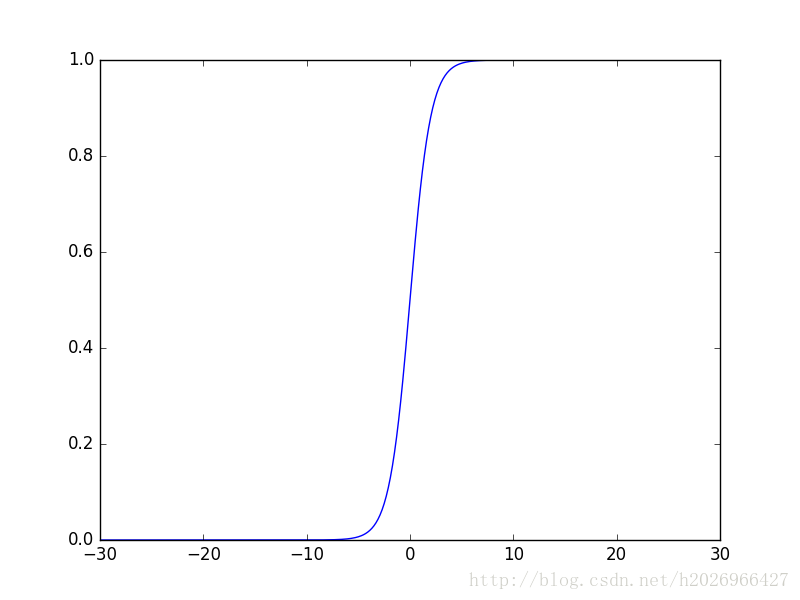
令
z=WTX
,如果
z>0
即
σ(z)>0.5
,就将该样本分为1类;如果
z<0
即
σ(z)<0.5
,就将该样本分为0类。
关键是如何利用训练数据找到最佳的模型参数 W 。
二,模型参数估计
利用极大似然估计法来估计模型参数。
过程如下:
- 首先假设
P(Y=1|x)=π(x),P(Y=0|x)=1−π(x) - 则似然函数为:
∏i=1n[π(xi)]yi[1−π(xi)]1−yi
-
- 为了加快求解,取对数,则对数似然函数为:
L(w)=∑i=1n[yilogπ(xi)+(1−yi)log(1−π(xi))]=∑i=1n[yi(wxi)−log(1+exp(wxi))]
- 对 L(w) 求极大值,得到w的估计值。常用方法有梯度下降法、随机梯度下降法和拟牛顿法等等。
三,梯度下降法和随机梯度下降法
核心公式如下:
w:=w−α∂L(w)∂w=w−α∗errorVec∗dataMatrix
其中w为向量。两者之间最主要的区别在于随机梯度下降法一次仅用一个样本点来更新回归系数。
而且为了减少在训练过程中回归系数的周期性波动,可以使用样本随机选择和 α 动态减少机制的随机梯度下降法,该方法也比采用固定 α 的方法收敛速度更快。具体代码如下所示:def stocGradDescent(dataMatrix,classLabels,numsIter): m,n = shape(dataMatrix) weights = ones(n) for k in range(numsIter): for i in range(m): alpha = 4.0/(i+k+1.0)+0.01 randIndex = int(random.uniform(0,m)) h = sigmoid(sum(dataMatrix[randIndex]*weights)) error = classLabels[randIndex]-h weights = weights + alpha*error*dataMatrix[randIndex] return weights其中第6行就是 α 动态减少机制,第7行就是样本的随机选择。
总之,随机梯度下降法与梯度下降法的效果相当,但占用资源更少。此外,随机梯度下降法是一个在线算法,它可以在新数据到来时就完成参数更新,而不需要重新读取整个数据集来进行批处理运算。
加速梯度下降法的技巧
1,特征缩放(feature scaling)
xi=xiSi
其中, Si是特征xi的取值范围的大小,即Si=max(xi)−min(xi)。2,均值归一化(mean normalization)
xi=xi−uiSi
其中, ui是特征xi的均值,Si同上(Si也可以取xi的标准差)。四,处理数据集中的缺失值
主要有以下几种方法:
- 使用可用特征的均值来填补缺失值。
- 使用特殊值来填补缺失值,如-1、0。
- 忽略缺失值的样本。
- 使用相似样本的均值来填补缺失值。
- 使用另外的机器学习算法来预测缺失值。
- 为了加快求解,取对数,则对数似然函数为:
- 则似然函数为:















 248
248

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









