







论文链接:Receptive Field Block Net for Accurate and Fast
Object Detection
代码链接:https://github.com/ruinmessi/RFBNet
目前state-of-art的目标检测网络主要是两条路子:
- two-stage:先只区分前景、背景的region proposals,同时进行第一次bounding boxes位置修正,基于proposals的CNN特征,进行类别预测和第二次位置回归;可以看出来,提取proposals特征的CNN主干网络占据着重要角色,我们希望提取到的目标特征,不仅判别性强,而且具有鲁棒的位置平移不变性;
- one-stage:直接省略了region proposals生成的阶段,同时使用轻量级网络作为特征提取的主干网络,大幅度地提升了速度,但同时精度也损失了;再之后的one-stage检测算法,如DSSD、RetinaNet提升了检测精度,性能上完全不输two-stage检测算法,但依旧使用强大的主干网络(如ResNet-101),耗时又增大了;
因此作者提出了一个新思路——去构建一个强有力且速度快的轻量级网络,一个可行的方案就是通过添加一些认为人工设计的机制,使得轻量级网络提取的特征表征能力更强。同时,作者结合了神经学上的一些发现,这个也是作者这篇文章的灵感来源吧!群体感受野(Population Receptive Field,pRF)是视网膜图离心度的函数,如图1所示,我们可以观察到两点:
(A)pRF,即群体感受野大小随着视网膜离心率增加而增加;
(B)基于(A)中参数的pRFs空间阵列;(没搞明白)

再来谈谈感受野的问题,首先我们要区分的就是理论感受野和有效感受野,理论上来讲,如果第N层的感受野为N_RF,那么前一层第N-1层的感受野N-1_RF = (N_RF-1)*stride + k_size,具体的解释可见:论文阅读:Understanding the Effective Receptive Field
可实际上,感受野中的像素对神经节点输出的贡献是不一样的,更具体一些是:感受野中心的像素的贡献更大些。理由:Forward pass过程:中心像素有更多的路径将该像素的信息传递给神经节点,边缘的像素有较少的路径将其像素信息传递给神经节点。相似地, Backward pass过程:感受野中心像素从相应的神经节点获取的梯度也更多。
理论感受野区域中的像素的贡献符合Gaussian分布。由于Gaussian分布从中心高边快速衰减,有效感受野只是是理论感受野的一部分。这部分具体推导可见 Understanding the Effective Receptive Field in Deep Convolutional Neural Networks。
现在来看一张图,对比了Inception、ASPP、Deformable Conv和RFB四种结构的理论感受野和有效感受野(如a中左理论感受野,右有效感受野):
- Inception block:使用用具有不同卷积核大小的多个分支来捕获多尺度信息, 但是所有卷积核都在同一个中心进行采样,这需要更大的卷积核才能达到相同的采样覆盖率,因而会丢失一些关键细节;
- ASSP:Atrous Spatial Pyramid Pooling,利用到了多尺度信息,上、下层feature map间连接多个并行的dilated conv分支,每个分支上使用不同的atrous rate,最终得到了对center的不同距离;但空洞卷积在前一个feature map上,并且使用了基于相同尺度的conv kernel,提取到的特征判别性还是不够,可能会造成目标和上下文的混淆;
- Deformable Conv:根据目标的尺度、外形自适应地调整RFs的空间分布,尽管其sampling grid是可变的,但却未考虑到RFs离心率的影响,也即RFs内所有pixel对输出响应的贡献率相同,未使用到fig 1中的结论;
- RFB:利用了Figure1中结论,即离心率增加的同时要增加视野大小(在d图中rate从
1
→
3
→
5
1\rightarrow 3\rightarrow 5
1→3→5 ,卷积核大小也从
1
→
3
→
5
1\rightarrow 3\rightarrow 5
1→3→5 ),距离conv center中心比较近的权重要使用小卷积核赋予更大的权重;

一. Receptive Field Block

下面来具体介绍下RF模块,RFB模块是一个多分支的卷积模块,它的内部结构被划分为两部分:
- 不同卷积核尺度的多分支conv,于Inception结构等价,用于模拟多尺度的pRFs;
- 空洞卷积操作,用于模拟人类视觉感知中pRF尺度与离心率间的关系;
Multi-branch convolution layer:作者使用多分支结构里面的最新的版本——Inception V4和Inception-ResNet V2。首先,在每个分支中使用bottleneck结构,先使用 1x1 卷积层减少通道数之后再去做 nxn 的卷积;第二点,使用两个堆叠的 3x3 卷积层来替代 5x5 卷积层,减少参数的同时加深了非线性层。出于和上面的同样的考虑,使用一个 1xn 加 nx1 的卷积层替代原来的 nxn 卷积层。最后,借鉴了 ResNet 和 Inception-ResNet V2 中shortcut的设计在结构中添加了一个旁路连接。
Dilated pooling or convolution layer:这个概念来源于Deeplab,称为空洞卷积层。这个结构的原始直觉就是在维持参数数量不变的情况下,不用下采样就可以产生感受野更大的feature map,从而可以捕捉到更多的上下文信息。这个设计最开始是用在语义分割中,后面也用于目标检测器中来提升速度和精度。最后各个分支concate后再接1 x 1 conv,再与shortcut做element-wise sum,可视化结果就如Figure 2所示了;

二. RFB-Net 检测结构

RFBNet基于multi-scale + one-stage的SSD, 将RFB模块直接接到SSD的top conv层即可,速度快,效果好,还可以复用SSD的很多参数;
Lightweight backbone:我们使用和SSD中相同的backbone——VGG16。现在ILSVRCCLS-LOC数据集上对模型做预训练,它的fc6和fc7层被转换为具有下采样参数的卷积层,它的pool5层被从 2x2-s2 转化为 3x3-s1。空洞卷积被用来填充holes,所有的dropout层和fc8被移除。我们选用VGG-16而没用其他诸如MobileNet、DarkNet和ShuffleNet这样的轻量级网络结构的原因在于可以直接和原始的SSD做直接的比较。
RFB on multi-scale feature maps:在原始的SSD中,主干网由一系列卷积层组成,在各个网络深度中形成一系列特征图,这些特征图具有连续递减的空间分辨率和递增的感受野。在本文的实现中,作者保持了相同的SSD级联结构,将一些分辨率较大特征图所在的卷积层替换为RFB模块。 在RFB的一些主要版本中,作者使用单一的结构设置来模仿偏心率的影响。 根据特征图之间pRF大小和离心率的不同,我们相应地调整RFB的参数以形成RFB-s模块并将其置于conv4_3层之后, 如图5所示, 这个模块实际上是模拟了人类浅层视网膜图中较小的pRF。而网络中的最后几个卷积层被保留,原因是这些网络层的输出特征图分辨率太小所以无法应用像5*5这样大尺度的卷积核。
三. 训练设置
我们是基于SSD的PyTorch版本实现的RFB检测器,我们的训练策略也是遵循了SSD,包括数据增强、负难例挖掘、default boxes的尺寸和宽长比、损失函数(smooth L1的定位损失和softmax的分类损失),然而我们轻微地改变了我们的学习率方案获得了更好的精度。
四. 实验
4.1 Pascal VOC 2007

4.2 消融实验
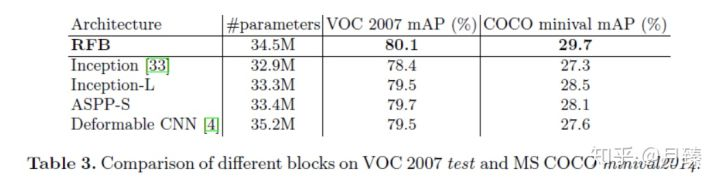
RFB模块:为了更好的理解RFB模块,我们调查了设计中每个元素的影响,并且和一些相似的结构做了对比。结果总结正如table 2和3所示。在table 2中,原始的SSD300实现了77.2%的mAP,通过简单的用RFB-max Pooling替代最后一个卷积层,我们将结果提升到了79.1%,获得了1.9%的提高,这表明了RFB模块的高效性。

Cortex map situlation:正如上一节提到的,我们调整RFB参数以模拟大脑皮层图中pRF的大小和偏心率之间的比率, 这种调整使RFB最大池化性能提高0.5%(从79.1%提高到79.6%),RFB膨胀卷积性能提高0.4%(从80.1%提高到80.5%),这同样证实了本文所依据的人类视觉系统的机制。
More prior anchors:原始SSD仅在conv4_3,conv10_2和conv11_2位置处的特征图关联4个默认框,并为所有其他层关联6个默认anchor。 但是最近的研究表明:浅层特征对于检测小物体起着至关重要的作用, 因此作者假设如果在浅层特征图(如conv4_3)中添加更多anchor,那么检测模型的性能(特别是小物体检测的性能)往往会由一定程度的增加。在实验中,作者在conv4_3处放置了6个默认框,实验表明这对于原始SSD模型的性能没有任何影响,但对于RFB模型却有0.2%的提升(从79.6%到79.8%)。
Dilated convolutional layer:table 2中对比了RFB-max pooling、RFB-avg pooling、RFB-dilated conv三种方案,发现RFB-dilated conv性能最好(79.8% -> 80.5%),原因:前两种方案(dilated pooling)虽然避免了新增额外的参数,却限制了多尺度RFs的特征融合;
4.3 Microsoft COCO

五. 讨论
Inference speed comparison:

Other lightweight backbone:

Training from scratch:作者还注意到RFB模块的另一个有趣的特性: 即可以从头开始有效地训练物体检测模型。最近的研究发现, 不使用预训练backbone的检测模型其训练将会是一项艰巨的任务,在two-stage的检测模型中, 所有的网络结构均无法在脱离预训练的条件下完成训练任务, 在one-stage的检测模型中, 虽然部分模型做到了收敛,但却只能取得低于使用预训练backbone的训练结果。 深度监督物体检测器(DSOD)提出了一种轻量级的结构,无需预先训练即可在VOC 2007测试集上实现77.7%的mAP,但其在使用预训练网络时不会提升性能。作者从零开始在VOC 2007 + 2012训练集上训练了RFB Net300,并在相同的测试集上达到了与DSOD类似的77.6%的mAP. 但值得注意的是,如果在RFB Net上使用预训练版本,性能将会提升至80.5%。
参考文献:
RFBNet(1)_论文_ECCV2018
https://blog.csdn.net/u014380165/article/details/81556769
https://zhuanlan.zhihu.com/p/58037657















 6094
6094











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









