




一. 生成模型
生成模型(Generative Model)这一概念属于概率统计与机器学习,是指一系列用于随机生成可观测预测数据得模型。简而言之,就是 “生成” 的样本和 “真实” 的样本尽可能地相似。生成模型的两个主要功能就是学习一个概率分布 P m o d e l ( X ) P_{model}(X) Pmodel(X)和生成数据,这是非常重要的,不仅可以用在无监督学习中,还可以用在监督学习中。
无监督学习的发展一直比较缓慢,生成模型希望能够让无监督学习取得比较大的进展。
二. 自动编码器——自监督学习
自动编码器(AutoEncoder)最开始作为一种数据的压缩方法,其特点有:
- 跟数据相关程度很高,这意味着自动编码器只能压缩与训练数据相似的数据,因为使用神经网络提取的特征一般是高度相关于原始的训练集,使用人脸训练出的自动编码器在压缩自然界动物的图片时就会表现的很差,因为它只学习到了人脸的特征,而没有学习到自然界图片的特征。
- 压缩后数据是有损的,这是因为降维的过程中不可避免地丢失信息,解压之后的输出和原始的输入相比是退化的。
到了2012年,人们发现在卷积神经网络中使用自动编码器做逐层预训练可以训练更深层的网络,但是人们很快发现,良好的初始化策略要比复杂的逐层预训练有效得多,2014年的Batch Normalization技术也使得更深的网络能够被有效训练,到了2015年年底,通过ResNet基本可以训练任意深度的神经网络了。
现在自动编码器主要应用在两个方面:第一是数据去噪,第二是进行可视化降维。自动编码器还有一个功能,即生成数据。
那么自动编码器是如何对深层网络做分层训练的呢?我们先来看看自动编码器的一般结构:
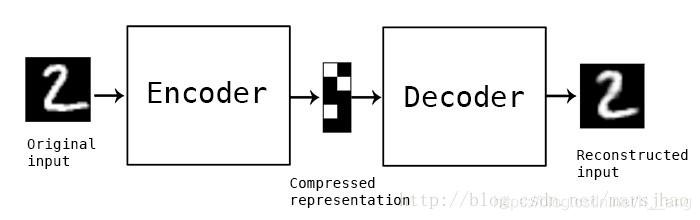
从上图可以看到两个部分:第一个部分是编码器(Encoder),第二个部分是解码器(Decoder),编码器和解码器都可以是任意的模型,通常使用神经网络作为编码器和解码器。输入的数据经过神经网络降维到一个编码(code),接着又通过另外一个神经网络去解码得到一个与输入原数据一模一样的生成数据,然后通过比较这两个数据,最小化它们之间的差异来训练这个网络中编码器和解码器的参数。
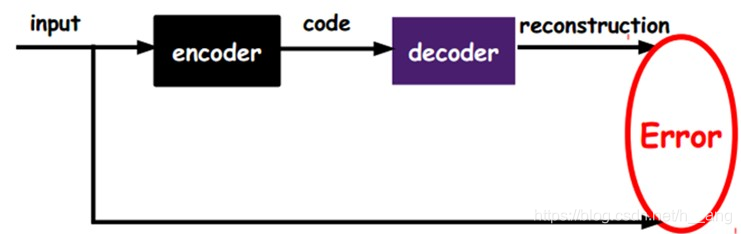
看完了网络结构,我们再来看看自动编码器是如何对深层网络做分层训练,如下图所示,我们将input输入一个encoder编码器,就会得到一个code,这个code也就是输入的一个表示,那么我们怎么知道这个code表示的就是input呢?我们加一个decoder解码器,这时候decoder就会输出一个信息,如果输出的这个信息和一开始的输入信号input是很像的(理想情况下就是一样的),那很明显,我们就有理由相信这个code是靠谱的。所以,我们就通过调整encoder和decoder的参数,使得重构误差最小,这时候我们就得到了输入input信号的第一个表示了,也就是编码code了。因为是无标签数据,所以误差的来源就是直接重构后与原输入相比得到。我们的重构误差最小让我们相信这个code就是原输入信号的良好表达了,或者牵强点说,它和原信号是一模一样的。接着,我们将第一层输出的code当成第二层的输入信号,同样最小化重构误差,就会得到第二层的参数,并且得到第二层输出的code,也就是原输入信息的第二个表达了。其他层就同样的方法炮制就行了(训练这一层,前面层的参数都是固定的,并且他们的decoder已经没用了,都不需要了)。
需要注意的是,整个网络的训练不是一蹴而就的,而是逐层进行。如果按n→m→k
结构,实际上我们是先训练网络n→m→n,得到n→m的变换,然后再训练m→k→m,得到m→k的变换。最终堆叠成SAE,即为n→m→k的结果,整个过程就像一层层往上盖房子,这便是大名鼎鼎的 layer-wise unsuperwised pre-training (逐层非监督预训练),正是导致深度学习(神经网络)在2006年第3次兴起的核心技术。
为了尽量学到有意义的表达,我们会给code加入一定的约束。从数据维度来看,常见以下两种情况:
- 如果input的维度大于code的维度,也就是说从 i n p u t → c o d e input\rightarrow code input→code的变换是一种降维的操作,网络试图以更小的维度来描述原始数据而尽量不损失数据信息。实际上,当两层之间的变换均为线性,且损失函数为平方差损失函数时,该网络等价于PCA;
- 如果input的维度小于等于code的维度。这又有什么用呢?其实不好说,但比如我们同时约束code的表达尽量稀疏(有大量维度为0,未被激活),此时的编码器便是大名鼎鼎的“稀疏自编码器”。可为什么稀疏的表达就是好的呢?这就说来话长了,有人试图从人脑机理对比,即人类神经系统在某刺激下,大部分神经元是被抑制的。个人觉得,从特征的角度来看直接些,稀疏的表达意味着系统在尝试去特征选择,找出大量维度中真正重要的若干维度。
三. 自编码器的一般形式
构建一个自动编码器并当对其完成训练完之后,拿出这个解码器,随机传入一个编码(code),通过解码器能够生成一个和原始数据差不多的数据,就是生成数据。
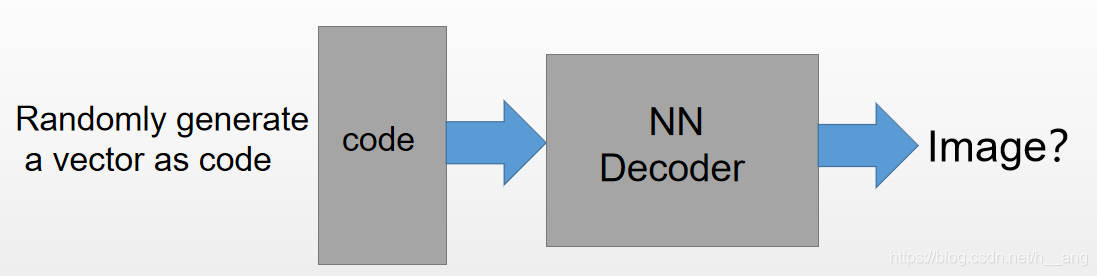
下面我们将用PyTorch简单地实现一个自动编码器实现“生成数据”:
import torch
from torch import nn, optim
from torch.autograd import Variable
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
from torchvision.utils import save_image
import os
import matplotlib.pyplot as plt
# 加载数据集
def get_data():
# 将像素点转换到[-1, 1]之间,使得输入变成一个比较对称的分布,训练容易收敛
data_tf = transforms.Compose([transforms.ToTensor(), transforms.Normalize([0.5], [0.5])])
train_dataset = datasets.MNIST(root='./data', train=True, transform=data_tf, download=True)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8402
8402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









