







 本文介绍了思通数科大模型如何运用自然语言处理和文本分类技术,实现消费者投诉的自动化处理,提升效率和准确性,减少人工错误,优化资源分配,并展望了未来的发展挑战与潜力。
本文介绍了思通数科大模型如何运用自然语言处理和文本分类技术,实现消费者投诉的自动化处理,提升效率和准确性,减少人工错误,优化资源分配,并展望了未来的发展挑战与潜力。
在消费者权益保护领域,处理投诉和举报是一项重要但繁琐的工作。传统的人工处理方式不仅耗时耗力,而且容易出错。随着自然语言处理(NLP)和文本分类技术的发展,自动化的投诉处理成为可能。本文将探讨思通数科大模型在智能文本提取与分类中的应用,以及其如何助力实现投诉处理流程的自动化和高效化。
一、自动化投诉处理的需求背景
消费者投诉和举报内容包含大量关键信息,如消费者诉求、经营者未履行义务的原因等,这些信息对于后续的处理至关重要。然而,人工提取这些信息不仅效率低下,而且容易出错。
二、思通数科大模型在智能文本提取中的应用
思通数科的大模型结合了自然语言处理和文本分类技术,能够自动识别并提取文本中的关键信息。该模型能够:
- 自动识别:识别文本中的消费者诉求和经营者未履行义务的原因。
- 关键信息提取:提取文本中的生产厂家、品牌、销售方式等细节。
- 智能分类:将提取的信息自动分类并填写到相应的字段中。
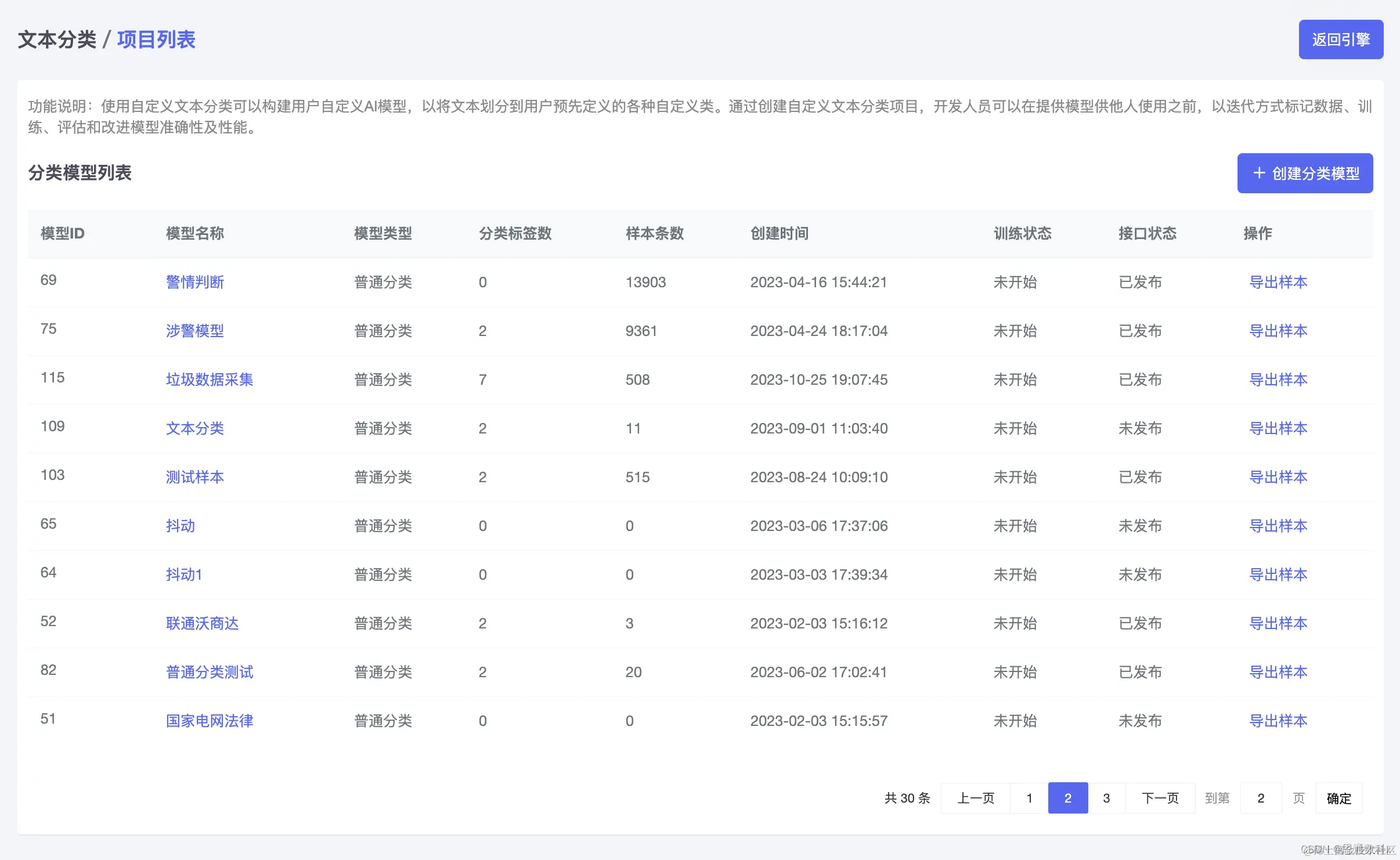
三、技术实现与工作流程
- 文本信息采集:收集消费者提交的投诉和举报文本。
- 预处理:对文本进行清洗、分词等预处理操作。
- 信息提取:利用思通数科大模型提取文本中的关键信息。
- 自动填写:将提取的信息自动填写到系统中的相应字段。
- 标记疑似情况:标记疑似职业打假的情况,供进一步分析。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 475
475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









