







TravelPlanner—使用语言代理进行真实世界旅行规划的基准
摘要
自人工智能诞生以来,规划一直是其核心追求的一部分,但更早
人工智能代理主要关注受限设置,因为人类层面的规划所必需的许多认知基础一直缺乏。最近,由大型语言模型(LLM)已经显示出有趣的功能,例如工具使用和推理。这些语言代理是否能够在遥不可及的更复杂的设置
之前的人工智能代理?为了推进这项研究,我们提出了TravelPlanner,这是一种新的规划基准,专注于旅行规划,是一种常见的真实世界的规划场景。它提供了丰富的沙箱环境,用于访问近400万条数据记录的各种工具,以及1225精心策划的规划意图和参考计划。综合评价显示当前的语言代理还不能处理如此复杂的规划任务——甚至GPT-4的成功率仅为0.6%。语言代理难以完成任务,使用正确的语言用于收集信息或跟踪多个约束的工具。然而,我们注意到语言代理处理此类问题的可能性复杂的问题本身就是一个不平凡的进步。TravelPlanner为未来的语言代理提供了一个富有挑战性但有意义的测试平台。
1.简介
计划是人类智慧的标志。这是一个建立在许多其他能力之上的进化壮举:使用迭代收集信息并进行de的各种工具-决策,记录中间计划(在工作记忆中或在物理设备上)进行审议,并通过运行模拟来探索替代计划,这反过来又取决于关于世界模型(Mattar&Lengyel,2022;Ho等人,2022)。几十年来,研究人员一直试图开发模拟人类规划能力的人工智能代理(Russell&Norvig,2010年;Georgievski和Aiello,2015;卡帕斯&
Magazzeni,2020),但通常在受限的环境中(Campbell等人,2002;Silver等人,2016;2017),因为许多人类层面规划所必需的认知基础一直缺乏。可以在人类操作的基本上不受约束的环境仍然是一个遥远的目标。
大型语言模型的出现(LLM;OpenAI(2022;2023); Touvron等人(2023a;b);江等(2023))这个经典问题的新亮点。新一代语言代理(Su,2023;Sumers等人,2023年;Xie等人。,2023)已经出现,其特征在于他们将语言作为思维工具的能力以及沟通。这些代理显示出有趣的能力,例如工具使用(Schick等人,2023;Patil等人,2023;秦等人,2024)和各种形式的推理(Wei et al.,2022;姚等人,2022;Lewkowycz等人。,2022),可能实现早期人工智能代理所缺乏的一些认知基础的作用。因此,研究人员调查了它们在一系列规划任务中的潜力,这些任务包括经典的规划环境如Blocksworld(Valmeckam等人,2023)
代理人(Huang等人,2022;Ichter等人,2022年;Song等人。,2023; 王等,2023)和网络代理(邓等,2022;周等,2024)。然而,现有工作中的规划设置仍在很大程度上遵循传统设置专注于固定地面的单目标优化真相。代理的任务是根据预定义的一组操作,刚才由LLM支持的代理进行。
语言代理是否能够在更复杂的情况下进行规划然而现实的环境,更接近人类的操作环境?
为了推进这项调查,我们提出了TravelPlanner,这是一种新的规划基准,专注于真实世界的规划场景——旅行规划。这是一个即使对人类来说也是一项具有挑战性、耗时的任务(但是大多数人都可以通过正确的工具和
足够的时间):1)规划一个多日的行程本身就很漫长,涉及到关于地点、住宿、交通、餐饮的大量相互依存的决策,等。2)旅行计划涉及许多约束,从预算和各种明确的约束用户需要隐含常识性约束,例如,如果不使用一些交通工具。3) 旅行计划要求使用主动获取必要信息的机构各种工具(例如,搜索航班和餐馆)部分可观察的环境和深思熟虑收集信息以推进规划注意所有明确和隐含的约束。规划如此复杂的任务是先前人工智能无法完成的代理人(Russell&Norvig,2010)。
TravelPlanner提供了一个丰富的沙箱环境大约有400万个数据条目从互联网上抓取可以通过六个工具访问。我们也一丝不苟策划1225个不同的用户查询(以及他们的参考资料计划),每个都施加不同的约束组合。一个有代表性的例子如图1所示。
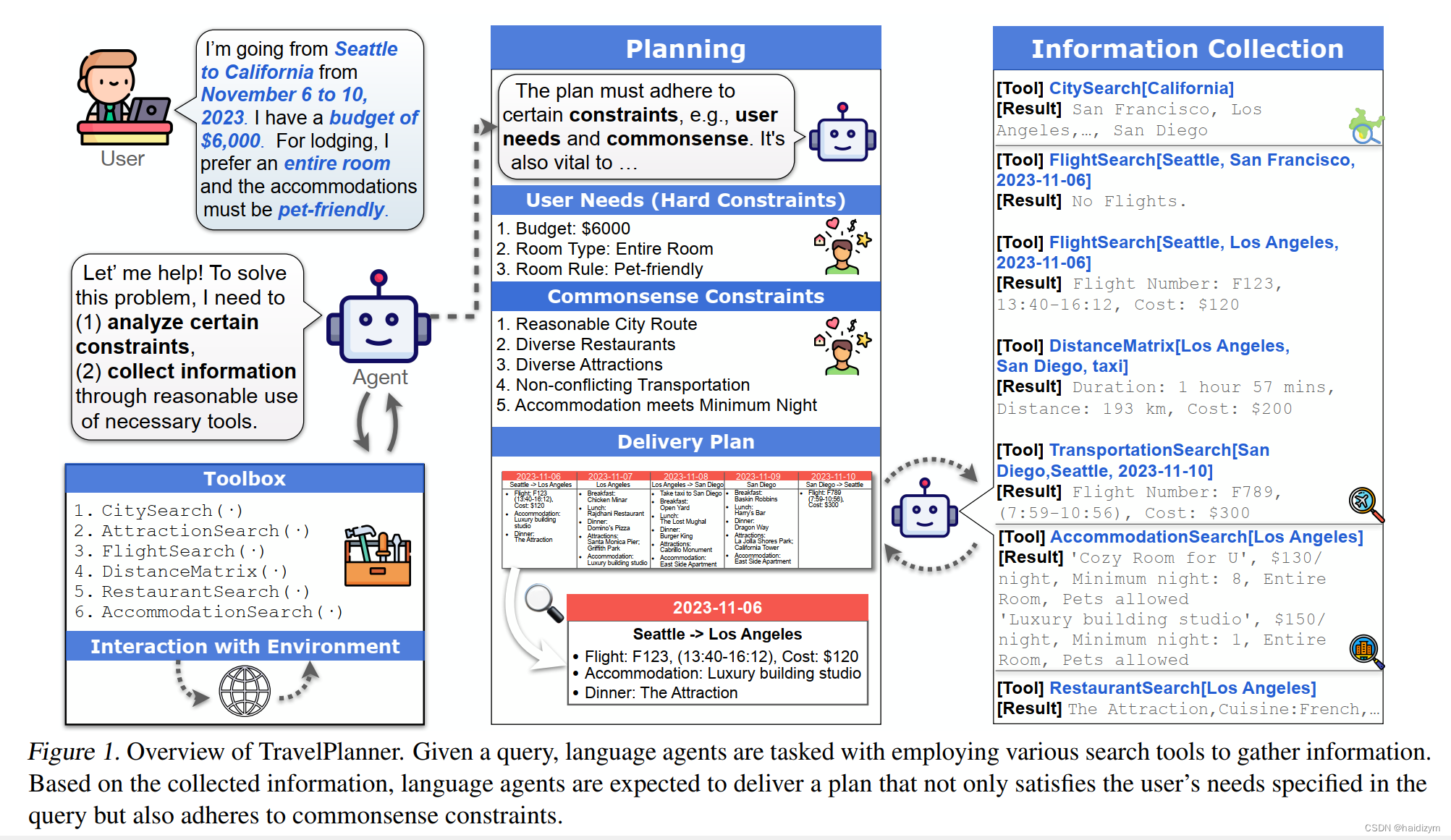
我们全面评估了五种LLM,如GPT-4(OpenAI,2023)、Gemini(G Team等人,2023年)和Mixtral(Jiang等人,2024年),以及四种规划策略,如如ReAct(Yao等人,2022)和Reflexion(Shinn等人。,
2023),关于其交付完整计划的能力,以及以下约束。主要发现如下:
•最先进的LLM无法处理复杂的规划类似TravelPlanner中的任务。GPT-4成功地生成了一个满足少数任务所有限制的计划(0.6%),而所有其他LLM都无法完成任何任务。
•现有的规划策略,如ReAct和Reflexion,可能对更简单的规划设置有效,不足以执行TravelPlanner中的多约束任务。他们往往无法将自己的推理转化为正确的推理正确操作并跟踪全局或多个约束。语言代理需要更复杂的计划接近人类层面规划的策略。
•进一步的分析揭示了许多常见的故障模式现有的语言代理,例如工具中的参数错误使用、陷入死循环和幻觉。
尽管我们的大多数发现都对在当前的语言代理中,我们应该注意到,人工代理处理如此复杂任务的可能性本身就是一个不平凡的进步。TravelPlanner提供具有挑战性但有意义的试验台,供未来的代理人在复杂环境中向人类水平的规划攀登。
最后,一线希望是:尽管我们训练有素的人工注释器平均需要12分钟来手动注释一个计划,一个语言代理可以在1-2分钟内生成一个计划分钟。也许有一天,语言代理人将变得足够有能力帮助自动化许多对我们来说,这是一项乏味的任务。
2.相关工作
2.1. 基于大型语言模型的Agent
借助大型语言模型(LLM),语言代理具有分解复杂任务的能力,并且通过一系列合理的行动得出解决方案。值得注意的例子例如AutoGPT(AutoGPT,2023),BabyAGI(Nakajima,2023)和HuggingGPT(Shen等。,2023)以其令人印象深刻的成就照亮了社区能力。当前LLM支持的语言代理,配备使用内存、工具使用和计划模块,已经看到
他们的综合能力有了显著的提高(翁,2023). 语言代理人的记忆指的是他们的能力以获取和处理信息。它分为两部分类型:长期记忆,即参数记忆
LLM固有的,以及短期记忆,也称为在上下文学习(Brown等人,2020)或工作记忆中。记忆概括等技术(Chen et al.,2023;周等,2023;Liang et al.,2023)和检索(Andreas,2022;Park et al.,2022;Zhong et al.,2021)是广泛的用来增强语言的记忆能力代理人。此外,通过与外部工具交互,语言代理显著扩展了其潜在能力。这种工具扩充范式在以前的工作中已经被验证为有效的(Nakano等人,2021;Lu等人。,2023; Ge等人,2023;谢等,2023)。我们进一步讨论第2.2节中的规划模块。
2.2. 规划
计划是人类智慧的标志,它需要一系列的行动,包括分解任务、搜索寻求解决方案,并做出最终决定(Hayes Roth&海斯·罗斯,1979年;Grafman等人,2004年;苏,2023)。这技能对于实现人类水平的智力和在机器人技术(McDermott,1992;Alterovitz等人,2016)和运输等领域进行了广泛研究日程安排(Cross和Estrada,1994年;Pinedo,2005年)。这个
LLM支持的语言代理的出现进一步加强了围绕其规划能力的讨论(Liu et al.,2023a;Valmickam et al.,2021)。先前的研究表明,语言代理可以有效地分解任务并进行逐步推理,从而带来显著的改进(Wei et al.2022;袁等人。,2023; 郑等,2024)。此外,为了优化解决方案以较少的步骤进行搜索,像树这样的经典数据结构并且在先前的研究中已经使用了图(Yao等人。,2023; Besta等人,2023),增强了语言代理的规划能力。此外,方法包括来自环境的反馈(Yao et al.,2022;Shinn等人2023)也被证明是有益的。然而,尽管这些规划能力在具体任务,这些规划策略的有效性在具有多个约束的场景中仍然不确定。
2.3. 语言代理的评价
先前的研究通常评估LLM语言聚焦域中的agent:算术推理定位正确的解决方案(Roy&Roth,2015;Cobbe等人,2021;Patel等人,2021);评估代理人熟练程度的工具使用在使用工具和报告结果方面(Li et al.,2023;Xu等人,2023;庄等,2023);以及网络导航、测试代理定位特定网站的能力(Deng et al。,2023; 周等,2024;刘等,2024)。然而现实世界的复杂性意味着以前的评估方法,侧重于单一目标和固定的地面真相,可能无法捕捉到的全部范围代理的能力。为了解决这一问题,我们引入TravelPlanner进行全面评估,评估语言代理可以针对各种目标生成可行的解决方案,本文称之为约束。
3.TravelPlanner
3.1. 概述
我们介绍TravelPlanner,这是一个专门为评估语言代理在工具使用和复杂规划中的表现而设计的基准在多个约束内。以旅行计划为基础,自然包括诸如用户需求和常识约束之类的各种约束的真实世界用例,
TravelPlanner评估代理商是否能够灵活发展通过各种工具收集信息制定旅行计划在满足约束条件的同时做出决策。
TravelPlanner共包含1225个查询。查询在TravelPlanner中,分为九组。这一分类基于两个标准:旅行持续时间和硬约束的数量。数据集分为培训、验证和测试集。该训练集包括5个每组带有人工注释计划的查询(45对总共),验证集包括每组20个查询(180个总共),并且测试集包括1000个查询。详细的分布如表A.1所示。
3.2. 约束简介
为了评估代理人是否能够感知、理解、,并满足各种约束来制定可行的计划,如表1所示,我们包括三种类型的约束:
•环境约束:现实世界
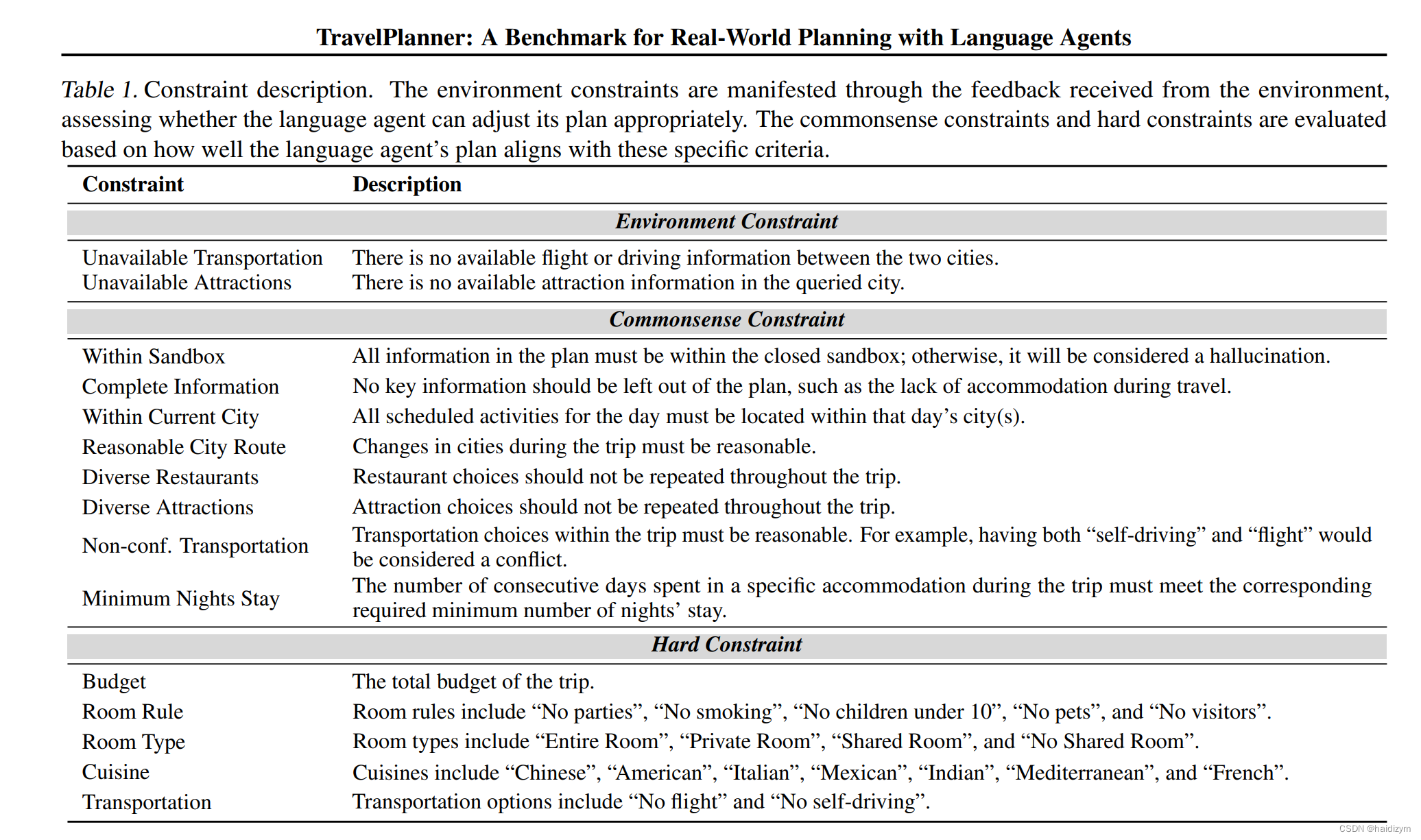
•常识约束:在现实世界中发挥作用并为人类服务的代理人应考虑常识设计计划时。例如,反复访问同样的吸引力并不典型。为了评估代理人在规划过程中对常识的理解和利用,我们在TravelPlanner中包含了常识性约束。
•硬约束:代理商的一个关键能力是有效满足个性化用户需求。为了评估这一点,TravelPlanner结合了各种用户需求,如预算约束。这些用户需求被称为硬约束。硬约束衡量了agent对不同用户需求的泛化能力。
3.3. 基准施工管线
本节概述了TravelPlanner的施工流程,包括以下步骤:1)环境和评估设置。2) 多样化的旅游查询设计。3) 参考平面注释。4) 质量检查。
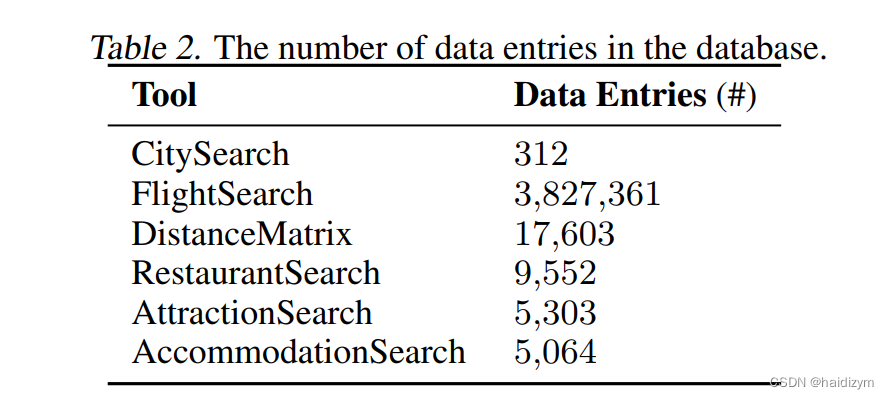
环境设置。在TravelPlanner中,我们创建一个静态和封闭的沙箱环境,实现一致性和公正性评估。此设置可确保所有代理访问来自我们静态数据库的相同不变信息,避免由动态数据。提供各种一致的旅行选择在现实世界中,我们确保每个工具的数据库TravelPlanner中包含丰富的信息。数据库
表2中列出了每个工具的尺寸。对于更多的工具细节,请参阅附录A.2和A.3。此外,代理被指示使用“NotebookWrite”工具进行记录规划所需的信息。此工具集成到评估代理的工作内存管理并防止上下文累积导致的最大令牌限制。
查询构造。为了为TravelPlanner创建各种查询,我们从几个基本元素开始,包括出发城市、目的地和特定日期范围,随机选择以形成每个查询的骨架。随后,我们调整了旅行的持续时间和数量硬约束以创建不同级别的复杂性。旅行的持续时间——3天、5天或7天——决定了纳入计划的城市数量。具体来说,3天计划集中在一个城市,而5天和7天包括访问一个随机选择的州,访问2个城市5天计划和3个城市的7天计划。A.更多的天数需要更频繁地使用工具语言代理,从而增加了管理的难度规划的长远方面。不确定的目的地使代理商难以决定多个城市,其中它们必须考虑诸如城市间连通性等因素。
此外,我们引入了不同的用户需求作为硬约束,以进一步增加复杂性和现实性。困难级别分类如下:
•简单:这一级别的查询主要是针对一个人的预算约束。每个的初始预算查询是使用一组精心编制的启发式规则来确定的。
•中等:除了预算限制外,中等查询随机引入了一个额外的硬约束从包括烹饪类型、房间在内的约束池中选择类型和房间规则。此外,人数在2到8之间变化,这会影响的计算交通和住宿费用。
•困难:硬查询包括约束池中的附加运输偏好以及所有约束在介质查询中。每个硬查询包含三个硬查询从约束池中随机选择的约束。这种方法确保了查询的多样性。微小的变化在这些元素中可能导致明显不同的计划。最后,基于元素,我们使用GPT-4(OpenAI,2023)以生成自然语言查询。
人类注释。确保每个查询至少有一个可行的方案是,我们邀请20名研究生为综合查询精心注释方案。一个计划只有满足我们的评估脚本中列出的所有约束条件时,才被视为合格,详细信息请参见第节3.4. 这一严格的过程导致了1225已验证的查询计划对。我们平均向注释者支付他们注释的每个计划0.80美元。质量控制确保每一个自然的质量语言查询及其相应的注释计划作者对每个查询进行了详细的审查计划,纠正发现的任何错误。此外,为了确保挑战,我们使用重新校准每个查询的预算相应的人工注释计划的成本。这该方法取代了最初的启发式生成的预算,这可能太高,从而减少了可行计划的数量。通过人类验证的多个阶段,我们确保TravelPlanner中每个查询的高质量,并且至少有一个可行的解决方案。
3.4. 评价
确保对提供的计划进行全面评估代理人,我们从多个维度对他们进行评估。具体而言,我们首先提取关键组成部分1,包括交通、餐厅、景点和住宿最初以自然语言的形式出现。然后将这些组成部分组织成正式结构化的计划,将通过预定义的脚本。评估标准包括以下内容:
•交付率:该指标评估代理商是否能够在有限的数量内成功交付最终计划
步骤。陷入死循环,经历无数尝试失败,或达到最大步数(在我们的实验设置中为30个步骤)将导致失败。
•常识性约束通过率:包括八个常识维度,该度量评估语言代理可以将常识融入他们的没有明确指示的计划。
•硬约束通过率:该指标衡量一个计划是否满足所有明确给定的硬约束在查询中,该查询旨在测试代理的适应能力他们针对不同用户需求的计划。
•最终通过率:该指标表示比例满足所有上述限制的可行计划在所有经过测试的计划中。它是代理商的一个指标熟练制定符合实际标准的计划。我们不单独评估环境限制,因为它们的影响内在地反映在“沙盒内”和“完整信息”指标中。例如,当城市缺乏交通或吸引力时,代理人通常会产生幻觉或选择不提供答案,反映了环境约束的影响。对于常识约束通过率和硬约束通过率,我们使用了两种评估策略:微观和宏。微观策略计算通过率
约束的总数。The Micro通过率定义为:
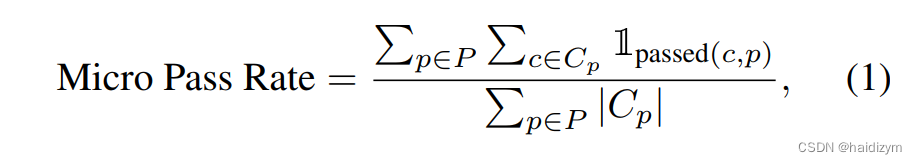
其中P表示正在评估的所有计划的集合,Cp
表示适用于特定计划p的约束集
在P中,并且passed(X,Y)是确定是否
Y满足约束X。
宏观战略计算通过计划的比率
所有测试计划中的所有常识或硬约束。
我们将宏通过率定义为:
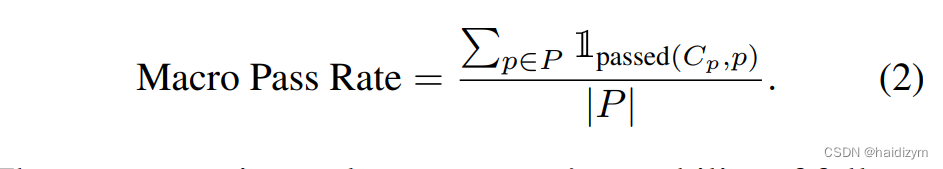
这两个度量从整体上评估代理遵循单个约束与所有约束的能力。
3.5. 鞋底规划设置
TravelPlanner旨在评估整体能力我们还设置了一个简化的模式,只评估代理的计划技能(唯一的计划模式)。在这种情况下,我们利用人工标注的计划预先确定目的地城市,并提供详细和必要的信息直接提供给代理商,如所提供城市的餐馆。这消除了对工具调用的需要,因为代理不需要不再通过工具从头开始收集信息。
4.实验
我们评估各种LLM的性能和规划TravelPlanner上的策略。在两阶段模式中,我们使用ReAct(Yao et al.,2022)信息收集框架,因其与工具(Zhuang et al.,2023),同时改变基础LLM。这种方法使我们能够评估不同之处LLM在统一的工具使用框架下执行代理人需要直接根据自行收集的信息,无需雇佣任何其他规划策略。在唯一规划模式中,我们的评估超越了不同的LLM,包括了不同的规划策略。这旨在评估战略在其他规划基准中证明有效他们在TravelPlanner中的功效。所有实验均在零样本环境下进行。
4.1. 基线
贪婪搜索。为了评估TravelPlanner中基于规则的传统策略的有效性,我们包括以贪婪搜索为基准,以设定成本为优化客观的有关更多详细信息,请参阅附录B.1。
LLM。由于的长上下文窗口要求ReAct和文本形式的大量信息,我们将考虑范围限制在能够处理超过8K输入的LLM长度。因此,我们的选择包括三个封闭源LLM:GPT-3.5-Turbo(OpenAI,2022)、GPT-4-Turbo(OpenAI,2023)和Gemini Pro(G Team等人。,2023),以及两个开源LLM:Mistral-7B-32K(Jiang et al.,2023)和Mixtral-8x7B-MoE(Jiang等人,2024)。对于所有这些型号,我们采用官方指令格式(只要可用)。
规划策略。为了探索当前规划策略的有效性,我们评估了四个具有代表性的其中:Direct、ZS-CoT(Wei et al.,2022)、ReAct(Yao et al。,2022)和反射(Shinn等人,2023)。有关实施细节,请参阅附录B.1。我们没有包括ToT(Yao et al.,2023)和GoT(Besta et al.,2021)因为它们需要对搜索进行广泛的探索空间,对于像TravelPlanner这样复杂的问题来说,成本高得令人望而却步。此外,考虑到他们在年的表现接近ReAct复杂任务(Zhuang et al.,2024),潜在效益这些方法中的一种可能是有限的。
4.2. 主要结果
在本节中,我们将讨论各种LLM的性能以及TravelPlanner上的规划策略(表3)。我们有以下观察结果:TravelPlanner提出了一个重大挑战。在两阶段模式下,带有ReAct的GPT-4-Turbo在最终通过率,并且其他LLM都不能通过任何
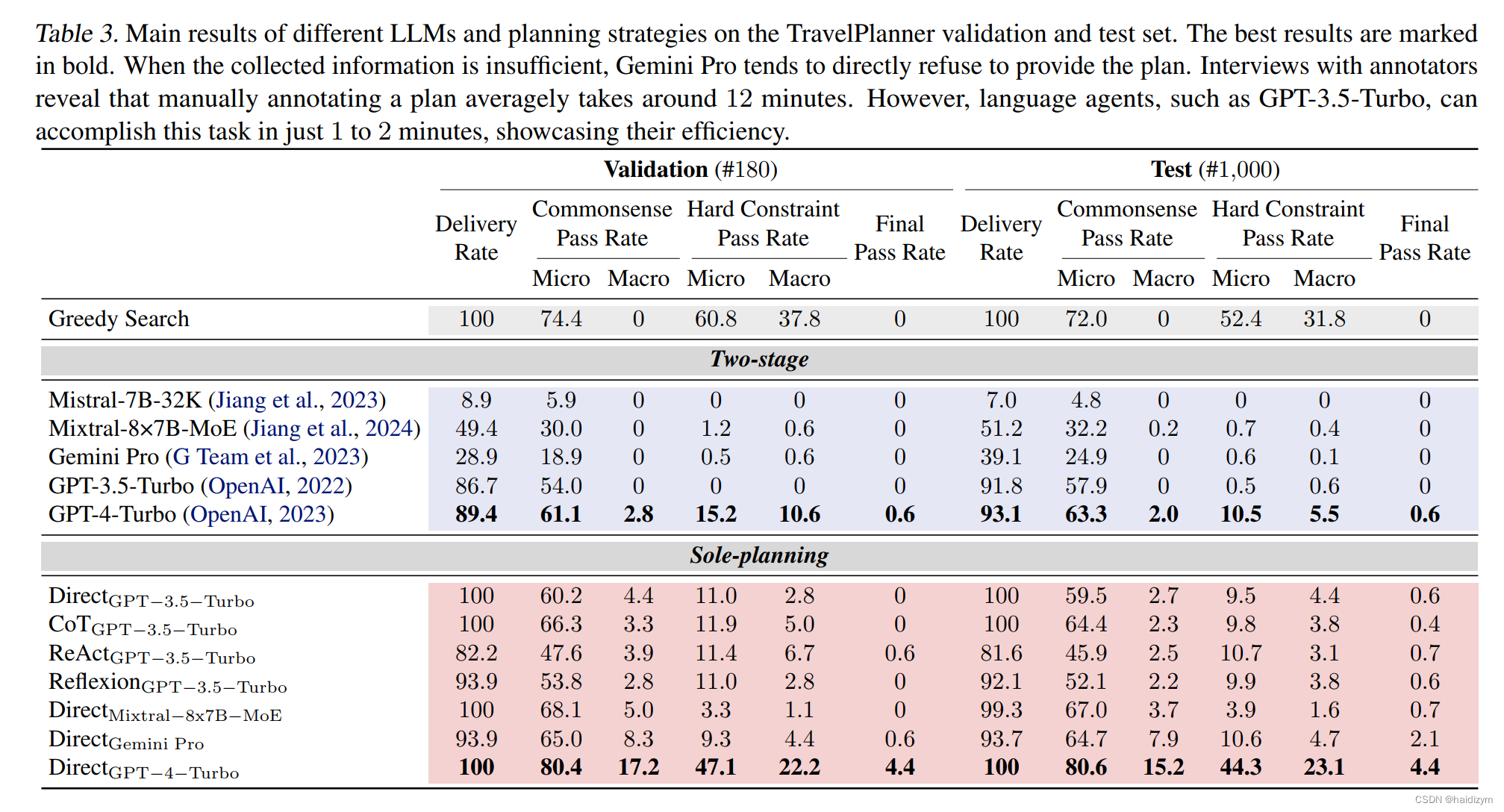
表3。TravelPlanner验证和测试集上不同LLM和规划策略的主要结果。最佳结果已标记粗体。当收集到的信息不足时,Gemini Pro倾向于直接拒绝提供计划。注释者访谈显示手动注释计划平均需要12分钟左右。但是,语言代理(如GPT-3.5-Turbo)可以在1到2分钟内完成这项任务,展示了他们的效率。


的任务。即使在中提供了所有必要的信息唯一的规划模式,现有的规划策略,如ReAct和Reflexion仍然难以在TravelPlanner中进行规划,尽管他们在更多方面表现出了有效性常规规划任务。值得注意的是,即使是表现最好的代理仍然没有达到硬性限制与贪婪搜索相比。这种糟糕的性能强调了TravelPlanner的困难,并表明目前的代理人仍在为复杂的计划而挣扎。
代理显示这两种模式之间存在很大差距。两种模式的比较揭示了代理人在信息收集和计划方面的挣扎。在所有指标中两阶段模式比单独规划模式低模式,最大差距达到30%以上。类似人类,语言代理人似乎也有有限的“认知能力”,当多任务处理。我们在第5.2节中提供了进一步的分析。
代理商很难获得高的宏观通过率。虽然一些代理商获得了很高的微观分数,但他们的宏观分数仍然很低。这种模式表明,尽管代理设法满足一些限制,他们经常忽略同时还有其他一些限制。因此指示当前代理未能全面考虑多个约束,这是导航的关键要求TravelPlanner中的复杂任务。
总之,TravelPlanner对现有代理商构成了巨大挑战。SoTA LLM和规划策略通常表现出与人类水平相当或优于人类水平的表现在许多传统任务上,仍然远远不够人类能够完成的复杂规划任务。TravelPlanner提供了一个具有挑战性但有意义的基准以开发更有能力的语言代理。
5.深入分析
5.1. 工具使用错误分析
如表3所示,即使基于GPT-4-Turbo,代理在信息收集过程中仍然会出错
从而无法交付计划。这个问题更严重在Gemini Pro和Mixtral中。深入探究
原因,我们在图2中对所有错误类型进行了分类。我们发现:
1) 代理商不正确地使用工具。除了GPT-4-Turbo之外,其他基于LLM的代理都存在参数错误问题在不同程度上。它揭示了简单工具的使用仍然对特工构成重大挑战。2) 特工陷阱在死循环中。即使使用GPT-4-Turbo,无效操作重复动作循环分别占37.3%和6.0%错误。尽管收到了行动的反馈
无效或产生空结果,代理持续重复这些行动。这表明代理无法动态运行根据环境反馈调整他们的计划。
5.2. 规划误差分析
我们在表4中详细介绍了每个约束通过率,其中我们有以下观察结果:
硬约束的数量会影响性能代理的数量。代理商的通过率始终低于10%在所有难度级别上,并且随着引入更多约束,这种性能进一步恶化。这一趋势强调了当前代理与多重约束作斗争任务,TravelPlanner的一个关键方面。
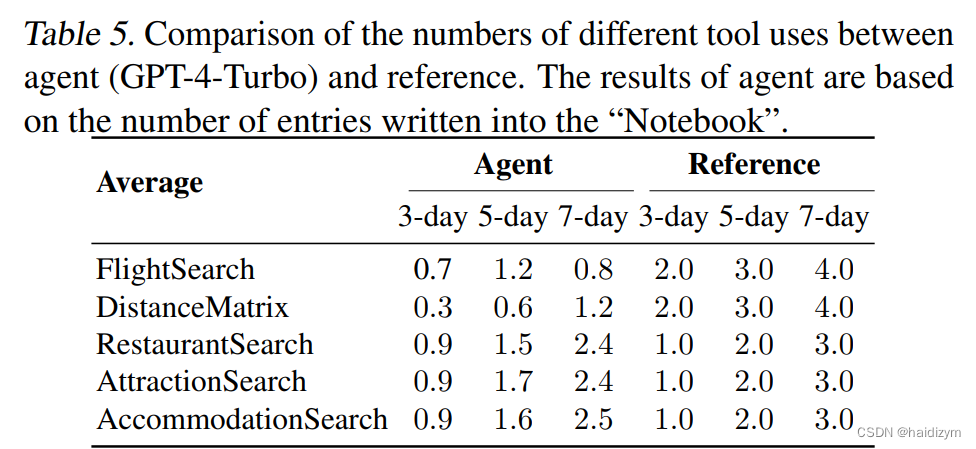
全面的信息收集对于代理人进行有效规划。在独家计划模式下,代理商性能比两阶段模式有所提高。调查-gate this,表5显示了处于两阶段模式的代理使用工具与参考计划相比效果较差。此比较表明代理经常无法完成已完成的任务信息收集。因此,它们要么生成编造信息或省略具体细节。这导致到“沙盒内”和“完成”的低通过率信息”约束。此外,随着持续时间的增加,这种差异变得更加明显长途行走这强调了代理商需要改进长期任务的能力。
代理商在全球规划场景中举步维艰。全球的限制“最低住宿天数”和“预算”需求一种全面的规划方法,需要代理人不仅评估他们当前的决策,而且预测未来影响。当前LLM的自回归性质限制他们从多个方面独立获得结果
未来的分支机构。这突出了必要性和紧迫性需要新的策略,如回溯以进行调整或采用启发式方法进行前瞻性规划。
5.3. 案例研究

为了深入调查当前代理的缺点,我们在图3中提供了几个失败案例。我们以结束具有以下功能:
由于无法纠正持续的错误,代理无法完成计划。在工具使用场景中,代理通常即使前面的所有步骤都正确执行,也无法交付计划。进一步调查显示,这个问题通常源于错误的日期输入。如左图所示图3的一部分,尽管执行正确,但代理会重复使用不正确的日期。这会导致空结果,因为数据TravelPlanner沙盒中的是基于2022。这种反复的失败最终导致代理停止计划。这表明了一个显著的限制:当前代理不能自我纠正他们最初和错误的假设。由于信息混乱,特工会产生幻觉般的答案。为了理解为什么特工即使在唯一的计划模式下提供了足够的信息,也会提供幻觉答案,我们进行了详细的分析我们观察到代理人有混淆的倾向一条信息与另一条信息。如中间所示在图3的一部分中,代理错误地将同一航班号用于出发和返回航班。这样的错误会导致在幻觉中,如计划中提供的信息与沙盒中的数据不对齐。这表明当面对大量信息时,代理可能会丢失,被称为“迷失在中间”(Liu et al.,2023b)。特工们努力使自己的行为与推理保持一致。了解交付量下降背后的原因反射率(Shinn等人,2023),我们检查例如。如图3的右侧部分所示,我们观察代理人的想法和想法之间的差异确实如此。尽管认识到有必要将成本,他们倾向于随机选择项目,其中一些可能更贵。这种差异表明代理人很难将他们的行动与他们的分析推理,严重阻碍了他们的交付率。
6.结论
我们介绍了TravelPlanner,这是一个基于现实世界场景的基准,旨在评估多重约束当前语言代理的规划和工具使用能力。
我们的基准提出了一个重大挑战:
大多数高级语言代理框架只能实现最终通过率仅为0.6%。进一步分析显示这些代理无法接受所有约束考虑提供可行的计划。
TravelPlanner复杂的逻辑和通用性是渐进发展的重要组成部分语言代理,从而为更广泛的探索做出贡献人工智能能力。我们将TravelPlanner视为催化剂用于未来的研究,旨在提高代理的性能在越来越复杂的场景中,向
人类层面的认知能力。
7.影响声明
TravelPlanner旨在为未来研究中的复杂规划。中的一些数据TravelPlanner环境来源于互联网上公开的数据,所涉及的内容并非代表作者的观点。我们意识到,每个人对常识的定义可能不同。我们的目前的评估标准是基于作者的共识,我们鼓励更多的讨论来丰富我们的常识维度,旨在更彻底评价我们将发布评估脚本以促进创新并帮助开发新方法。我们鼓励在训练集中使用评估反馈,例如实施强化学习技术加强学习。但是,我们严格禁止任何形式的在验证和测试集中作弊以维护公平以及基准评估过程的可靠性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









