







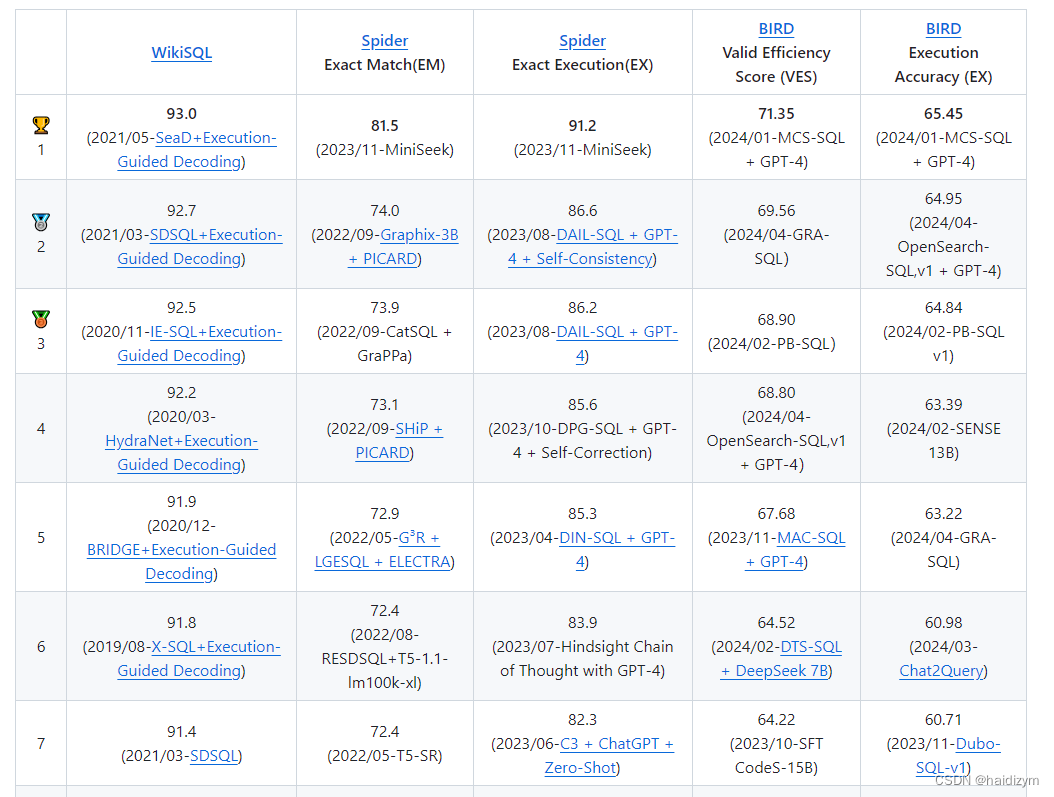
排行榜
网址:https://github.com/eosphoros-ai/Awesome-Text2SQL/blob/main/README.zh.md
综述类文章
A survey on deep learning approaches for text-to-SQL 2023
通过自然语言与数据库交互可以扩大数据中台的使用范围,从以往的基于规则方法,机器学习方法,到现在的神经机器翻译。本文对神经机器翻译方法作细粒度的分类,并进行比较。
text-to-SQL问题
定义
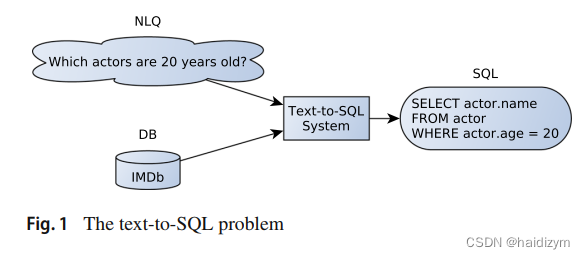
Given a natural language query (NLQ) on a Relational Database (RDB) with a specific schema, produce a SQL query equivalent in meaning, which is valid for the said RDB and that when executed will return results that match the user’s intent.
给定具有特定模式的关系数据库(RDB)上的自然语言查询(NLQ),生成意义等效的SQL查询,该查询对所述RDB有效,并且在执行时将返回与用户意图匹配的结果。
自然语言挑战:歧义(Ambiguity)
–类型:词汇歧义Lexical ambiguity、句法歧义Syntactic ambiguity 、语义歧义Semantic ambiguity、上下文依赖歧义Context-dependent ambiguity;
转述Paraphrasing 、推断Inference 、Elliptical queries、Follow-up questions、User mistakes
SQL语言挑战
严格的语法–语法和语义正确,
数据库结构Database structure挑战:vocabulary gap、Schema ambiguity、Implicit join operations 、Entity modelling
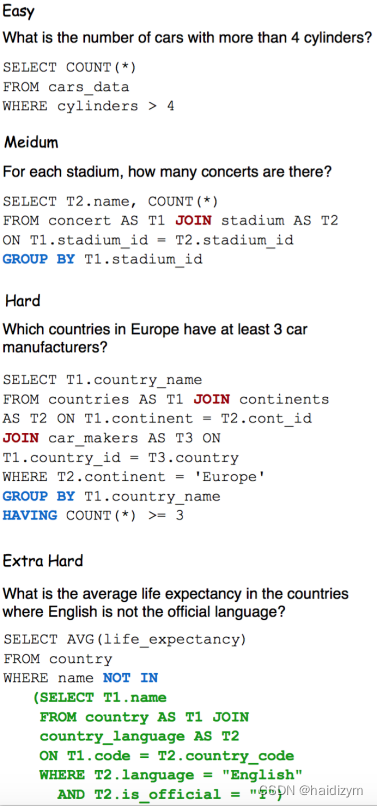
数据集和评估

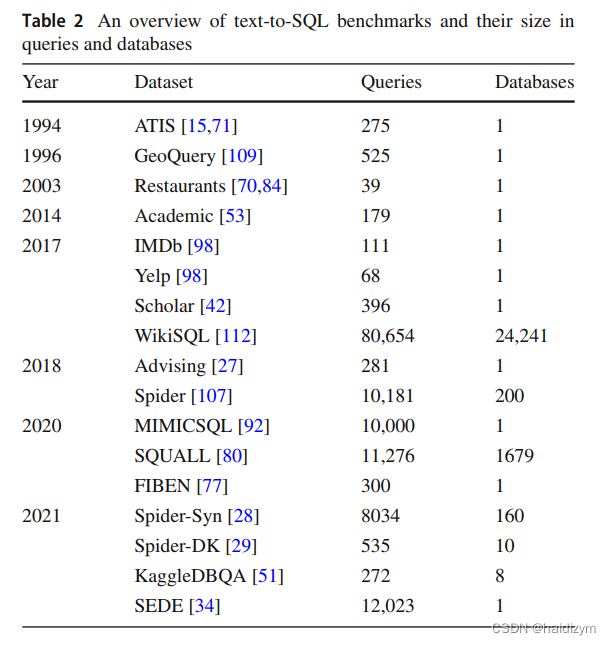
spider数据集
Spider consists of 10,181 questions and 5,693 unique complex SQL queries across 200 databases, covering 138 domains, each containing multiple tables.
BIRD comprises an extensive dataset with 12,751 unique question-SQL pairs, encompassing 95 large databases totaling 33.4 GB in size. It spans a wide array of more than 37 professional domains, including blockchain, hockey, healthcare, and education.
引入四类知识, 数字推理知识, 领域知识、同义词知识,以及价值说明。值得注意的是,中的SQL查询BIRD数据集往往比Spider数据集中的数据集更复杂
评估标准:String matching、Execution accuracy、Component matching、Exact set matching、Exact set match without values、Sub-tree elements matching、
分类
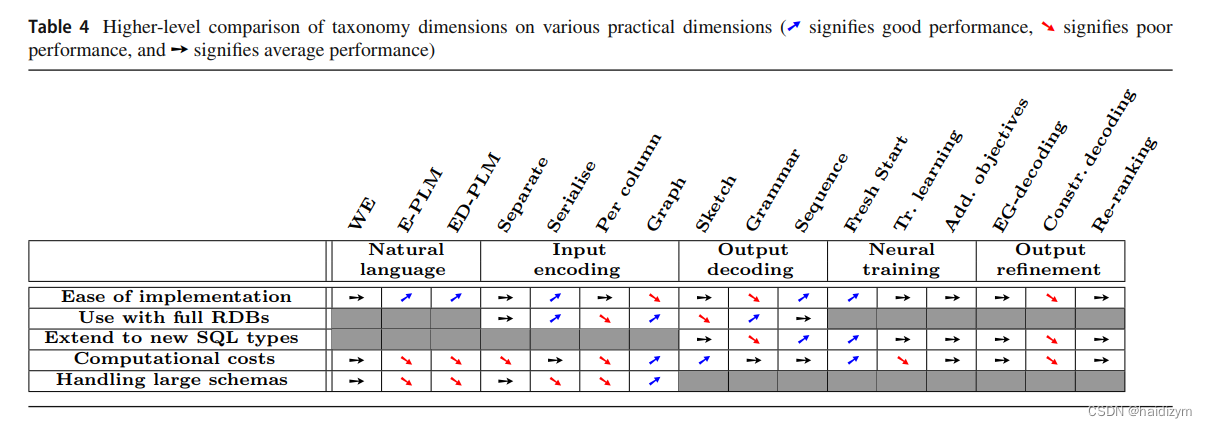
环节: schema linking——》the encoder and the decoder(natural language representation、Input encoding 、output decoding、neural training)–》output refinement
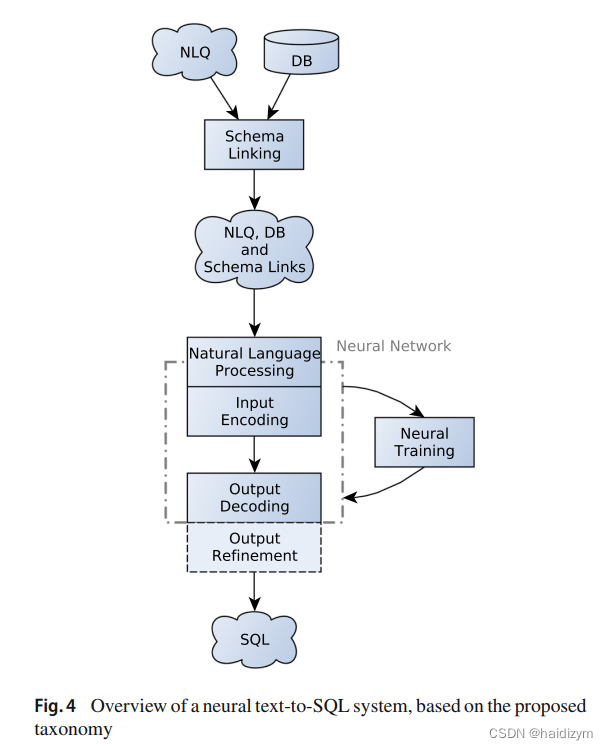
模式链接,旨在在发现可能提及数据库元素(表、列和值)。query candidates,database candidates,Candidate discovery、Candidate matching,
query Candidate discovery:Single tokens 、Multi-word candidates、Named Entity
Recognition、Additional candidates 、validated candidates ,
Database candidate discovery:Table and column names 、Values via lookup(Indexes、ValueNet [10] )、Values via knowledge graphs (IRNet [33] )、
Candidate matching:Exact and partial matching 、Fuzzy/approximate string matching 、Learned embeddings、Classifiers(训练一个模型执行模式链接)–CRF、Schema Dependency(select-column (SCol), select-aggregation (S-Agg), where-column (W-Col), where-operator (W-Op) and where-value (W-Val)),Neural attention
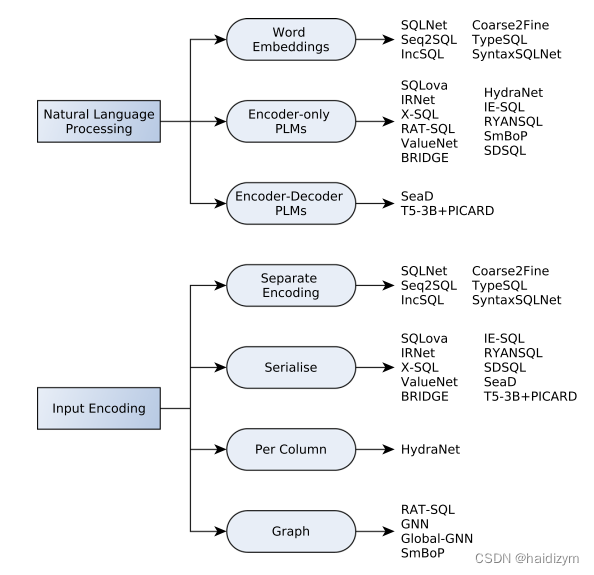
自然语言表征
Word embeddings、 Pre-trained language models、Input encoding 、output decoding、neural training
输入编码
Input encoding :We distinguish four encoding schemes: (a) separate NLQ and column encodings (b) input serialisation © encoding NLQ with each column separately, and (d) schema graph encoding.
schema graph encoding.:a handful of systems[8,9,89]. Each node in the graph represents a database tableor a column, while their relationships can be represented by edges that connect the respective nodes。(表格、列、NLO查询词是图的结点,关系–主外键、属于、模式链接则是图的边),
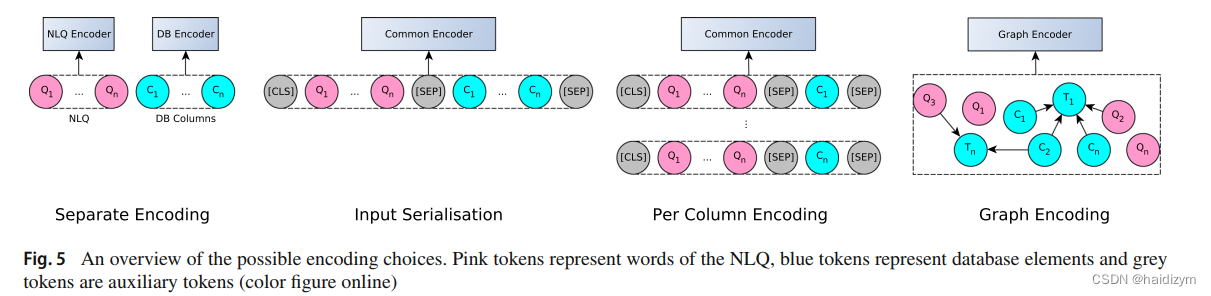
BRIDGE [57] ,HydraNet [62],RAT-SQL [89] and [78]
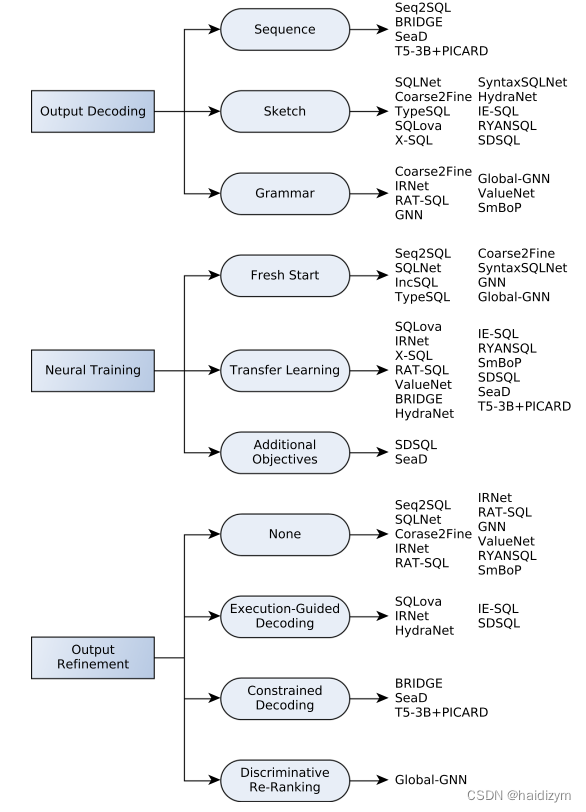
输出解码 (a) sequence-based, (b)grammar-based, and © sketch-based slot-filling approaches。
Abstract Syntax Tree (AST) [99,100]
神经训练
Fresh start、Transfer learning、Additional objectives、Pre-training specific components
神经结构
线性神经网络,循环神经网络,Transformers,条件随机场,卷积神经网络
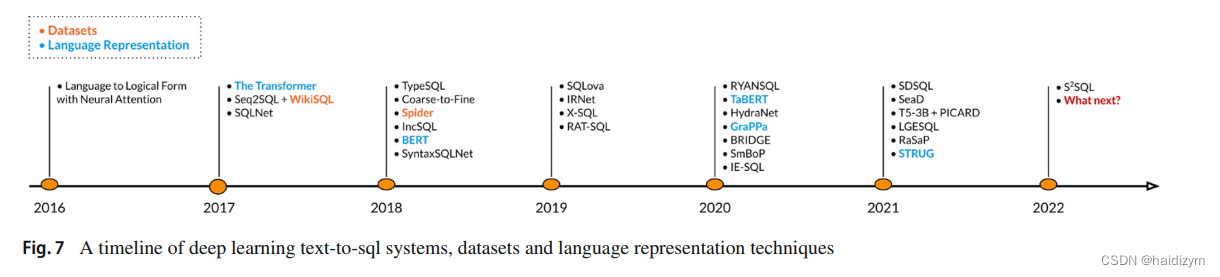
Systems
系统的进化从(1)开始使用神经网络结构,(2)到输出用骨架插槽填充,到生成骨架和插槽,(3)到图表示输入和图神经网络解析,到bert和transformer解析,(4)到生成中间语言,(5)到bert编码输入,(6)到聚焦模式链接,(7)到回归序列
Seq2SQL [112],was one of the first neural networks for the text-to-SQL task and was based on previous work focusing on generating logical forms using neural networks.
SQLNet [96] proposed using a query sketch with fixed slots that, when filled, form a SQL query. Using a sketch allowed the problem to be formulated almost entirely as a classification problem, since the network has to predict: (a) the aggregation function between a fixed number of choices, (b) the SELECT column among a number of columns present in the table, © the number of conditions (between 0 and 4 in the WikiSQL dataset), (d) the columns present in the WHERE clause (as multi-label classification, since they can be more than one), (e) the operation of each condition among a fixed number of operations (≤, =, ≥) and (f ) the value of each condition. introduced a column attention neural architecture to the network. Column attention is an attention mechanism that infuses the NLQ representation with information about the table columns, so as to emphasise the words that might be more related to the table.
不仅插槽填充,还生成骨架(generate the appropriate sketch):
Coarse2Fine [22]: it decomposes the decoding process into two steps: first, it generates a rough (coarse) sketch of the target program without low-level details, and then it fills this sketch with the missing (fine) details. the sketches it generates only differ between them in the number of conditions that appear in the WHERE clause and the operations in each condition.
RYANSQL [13] :breaks down each SQL query into a non-nested form that consists of multiple, simpler, sub-queries. The authors propose 7 types of sub-queries, each with its own sketch, that can be combined to produce more complex queries.
SyntaxSQLNet [105]:it follows a predefined SQL grammar that determines which of its 9 slotfilling modules needs to be called to make a prediction. At each prediction step, the grammar and the prediction history from the previous steps are used to determine the module (e.g. COLUMN module, AGGREGATOR module, OPERATOR module, HAVING module, etc.) that needs to make a prediction in order to build the SQL query.
Graph representations图表示
GNN parser [8] and its successor Global-GNN parser[9]:the database schema is represented as a graph, where tables and columns are represented as nodes, and different types of edges represent the relationships between them (e.g. which columns appear in which table and which columns and tables are connected with a primary-foreign key relationship)。For NLQ encoding, both systems use word embeddings and LSTM networks, while node encodings calculated by the GNNs are concatenated to each word embedding, based on the discovered schema links. For decoding, both systems use a grammar-based decoder [99] that generates a SQL query as an Abstract Syntax Tree (AST), which is often used by grammar-based systems [10,33,89].
RATSQL [89] uses a graph representation of the input, but instead of using GNNs, it proposes a modified Transformer architecture named Relation Aware Transformer (RAT). Firstly, it creates a question-contextualised schema graph, i.e. a graph representing the database tables and columns as well as the words of the NLQ as nodes and the relationships between them as edges. An edge can appear either between two database nodes, similarly to the previous systems, or between
a database node and a word node. In this graph, schema linking is performed to discover connections between a database
node and a word node that might refer to it. The names of all the nodes in the graph are first encoded using BERT [19] and then processed by the RAT network, along with the edge information of each node. The RAT neural block performs relation aware self-attention on its inputs, which essentially biases the network towards the given relations (edges). This allows the system to use Transformers and even pre-trained language models to process the graph as a series while also utilising the information present in the graph edges. Finally, it generates a SQL query as an AST using the method mentioned above [99]。
用图表示输入,表、列和NLQ的单词作为结点,它们的关系作为边,schema linking是发现数据库节点和单词节点的关系,图结点都用bert编码,然后和其关系送入RAT network,实现Transformers和预训练的功能,最后生成抽象语法树的sql查询语句。
Using intermediate languages使用中间语言
IRNet [33] It uses the same AST decoding method [99] for code generation,and it predicts an AST of a SemQL program,
which is an Intermediate Language created specifically for this system.
SmBoP [75] is a grammar-based system,use of relational algebra as an Intermediate Language。in order to decode
ASTs of queries in relational algebra, SmBoP uses a bottomup parser,
The age of BERT使用预训练语言模型如bert代替传统的编码器,
SQLova [39]基于骨架,使用bert编码NLQ和表头,
HydraNet [62],预训练好bert,当从bert接收到背景表征后仅使用一个简单的线性网络,并且单独编码每个表头,预测列是否出现在select和where中,比SQLova有更好的表现。
X-SQL [35] 是一个使用MTDNN pre-trained language model的基于骨架的系统,使用type embeddings编码输入的不同元素,如the user’s question, categorical columns and numerical columns,Furthermore, it uses an attention layer to create a
single token representation for columns that have more than one token (i.e. more than one word in their name),表现也好于SQLova,略低于X-SQL。
Schema linking focus聚焦模式链接
TypeSQL [103] 第一个把模式链接引入工作流,使用Type Recognition的方法,给NLQ的每个token分配一个类型,It considers all n-grams in the NLQ of length from 2 to 6 and tries to assign them one of the following “types”: (a) Column, if it matches the name of a column or a value that appears under a column, (b) Integer, Float, Date or Year, if it a numerical n-gram, © Person, Place, Country, Organization or Sport by performing NER using the Freebase knowledge graph.
ValueNet [10] ValueNet decodes a SQL query in a SemQL 2.0 AST。使用5个步骤:
• value extraction to recognise possible value mentions in the NLQ, it uses NER and heuristics;
• value candidate generation to create additional candidate values, it uses string similarity, hand-crafted heuristics and n-grams;
• value candidate validation to reduce the number of candidate values, it keeps only the candidates that appear in the DB;
• value candidate encoding it appends each candidate to the input along with the table and the column it was found under, and
• neural processing the encoded representations are processed by the neural network, which eventually decides if and where they will be used.
SDSQL [38] 基于骨架的系统,完成两个任务的两个网络,一个预测sql查询语句,一个预测NLQ的词汇和表头的依赖关系----the select-column和the where-value,使用损失和的方式训练两个网络。
IE-SQL [63]。It uses two instances of BERT to perform two different tasks: a mention extractor and a linker.The mention extractor recognises which query candidates are mentions of columns that will be used in the SELECT and WHERE clauses of the SQL query, mentions of aggregation functions, condition operators and condition values. Additionally, the mention extractor recognises mentions that should be grouped together. Having extracted the mentions, the linker maps the mentions of column names to the actual columns of the table they are referring to. The linker also maps value mentions without a grouped column to the appropriate table column.
The return of the sequence回归序列
使用一些技术改进序列到序列的语法错误[57,76,97] ,使得text2sql回归序列时代,使得高表现的预训练编码解码器变得可用。
SeaD [97],使用BART encoder– decoder pre-trained language model,Its main contribution is the use of the two additional training tasks named erosion and shuffle , which are designed specifically to help the model better understand the nature of the text-to-SQL problem and the tables used by the WikiSQL dataset.
BRIDGE [57] ,it uses BERT and LSTM networks for input encoding and enriches the input representation using linear networks that use metadata such as foreign and primary key relationships, as well as column type information. BRIDGE is trained (and makes predictions) on SQL queries written in execution order, i.e. all queries start with the FROM clause, followed by the WHERE, GROUP BY, HAVING, SELECT, ORDER BY and LIMIT clauses, strictly in that order.
PICARD [76],is a constraining technique for autoregressive decoders of language models,used with the T5 pre-trained language model (the 3B parameters version),
• it rejects misspelled attributes and keywords, as well as tables and columns that are invalid for the given schema,
• it parses the output as an AST to reject grammatical errors, such as an incorrect order of keywords and clauses or an incorrect query structure,
• it checks that all used tables have been brought into scope by being included in the FROM clause and that all used columns belong to exactly one table that has been brought into scope.it ranked first on the Spider leaderboard for execution with values
小结:
输出:序列模式
NL representation:预训练语言模型,
输入编码: use serialised or graph encoding,
Schema linking:回归序列
Neural training:
Output refinement:
A Survey on Text-to-SQL Parsing Concepts,methos, and future directions 2022
语料有单论和多轮,预训练语言模型的综述和用以text2sql的方法,可能的挑战和未来方向,
A typical neural generation method is the sequence-tosequence (Seq2Seq) model, which automatically learns a mapping function from the input NL question to the output SQL under encoder-decoder schemes.一种典型的神经生成方法是序列到序列(Seq2Seq)模型,该模型在编码器-解码器方案下自动学习从输入NL问题到输出SQL的映射函数。The key idea is to construct an encoder to understand the input NL questions together with related table schema and leverage a grammarbased neural decoder to predict the target SQL. 关键思想是构建一个编码器来理解输入的NL问题以及相关的表模式,并利用基于语法的神经解码器来预测目标SQL。
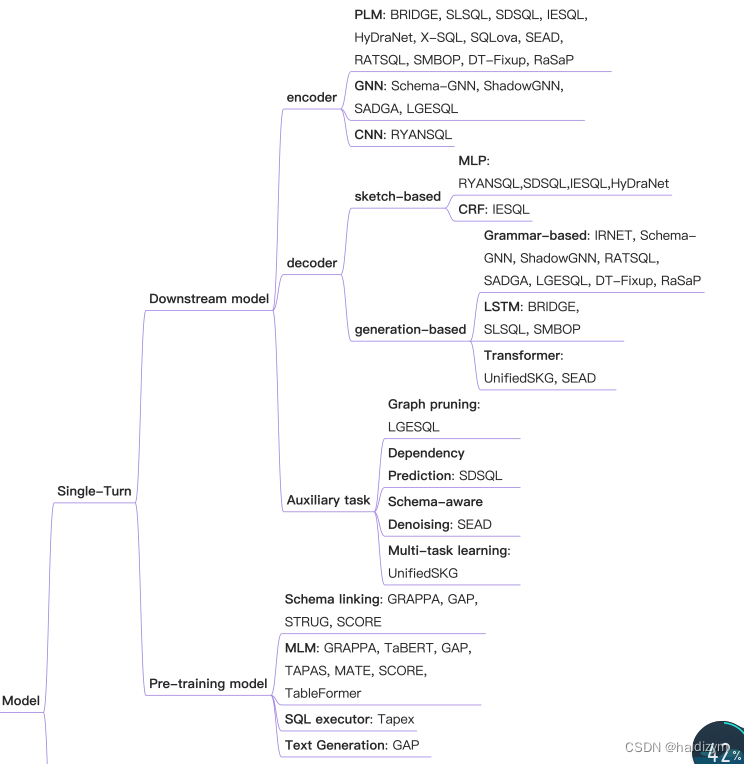
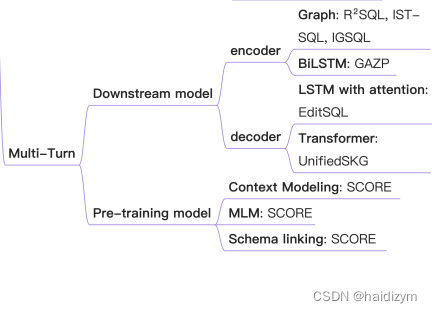
编码器端:bi-lstm,cnn,plms,gnn,
解码器端:the sketch-based methods 和the generationbased methods,the generation-based methods [4, 12, 14, 17] usually decoded the SQL query as an abstract syntax tree in the depth-first traversal order by employing an LSTM decoder.
预训练语言模型:TaBERT,TaPas,Grappa
TaBERT [18] jointly encoded texts and tables with masked language modeling (MLM) and masked column prediction (MCP) respectively, which was trained on a large corpus of tables and their corresponding English contexts. TaPas [19] extended BERT by using additional positional embeddings to encode tables. In addition, two classification layers are applied to choose table cells and aggregation operators which operate on the table cells. Grappa [20] introduced a grammaraugmented pre-training framework for table semantic parsing, which explores the schema linking in table semantic parsing by encouraging the model to capture table schema items which can be grounded to logical form constituents. Grappa achieved the state-of-the-art performances for textto-SQL parsing.TaBERT[18]分别使用掩蔽语言建模(MLM)和掩蔽列预测(MCP)对文本和表格进行联合编码,并在大型表格语料库及其相应的英语上下文上进行训练。TaPas[19]通过使用额外的位置嵌入对表进行编码来扩展BERT。此外,还应用了两个分类层来选择表单元格和对表单元格进行操作的聚合运算符。Grappa[20]介绍了一种用于表语义解析的语法增强预训练框架,该框架通过鼓励模型捕获可以基于逻辑形式成分的表模式项来探索表语义解析中的模式链接。Grappa实现了最先进的文本到SQL解析性能。
SINGLE-TURN T2S PARSING APPROACHES
编码:
Input Representation:nl问题和表模式表征,LSTM-based [5, 49] and Transformer-based [6] methods.
structure modelling:linking structure、schema structure、question structure。graph methods consider the NL question tokens and schema items as multityped nodes, and the structural relations (edges) among the nodes can be pre-defined to express diverse intra-schema relations, question-schema relations and intra-question relations.
解码:
Sketch-based Methods:
generation-based methods:
模型
MAC-SQL 2023
(A Multi-Agent Collaborative Framework for Text-to-SQL)
https://github.com/wbbeyourself/MAC-SQL

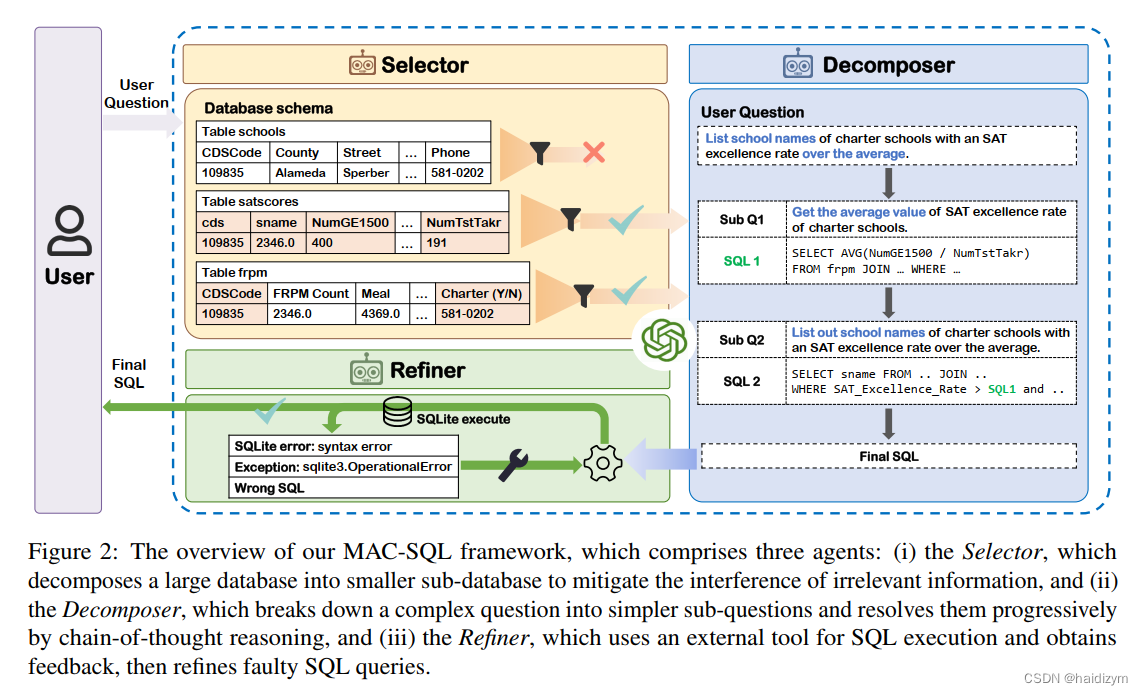
Our framework comprises a core decomposer agent for Text-to-SQL generation with few-shot chain-of-thought reasoning, accompanied by two auxiliary agents that utilize external tools or models to acquire smaller subdatabases and refine erroneous SQL queries. The decomposer agent collaborates with auxiliary agents, which are activated as needed and can be expanded to accommodate new features or tools for effective Text-to-SQL parsing. Furthermore, we have fine-tuned an instructionfollowed model, SQL-Llama, by leveraging Code Llama 7B, using agent instruction data from MACSQL, thus enabling capabilities in database simplification, question decomposition, SQL generation, and SQL correction.
我们的框架包含一个核心的分解智能体Decomposer,使用少样本学习和思维链推理辅助Text-to-SQL,与另外两个辅助智能体Selector and Refiner一起协作,这两个辅助智能体通过使用外部工具和模型来获得更小的子数据库,并精炼错误的sql查询。分解智能体与两个辅助智能体,当需要的时候就被激活,能够扩展有效的文本到SQL解析的特征和工具。此外,我们还通过利用Code Llama 7B,使用来自MACSQL的代理指令数据,对指令遵循模型SQL Llama进行了微调,从而实现了数据库简化、问题分解、SQL生成和SQL更正的功能。
定义:The problem of Text-to-SQL parsing involves generating an SQL query Y that corresponds to a given natural language question Q and is based on a database schema S and optional external
knowledge evidence K. The database schema S is defined as {T , C, R}, where T represents multiple tables {T1, T2, . . . , Tm}, C represents columns {C1, C2, . . . , Cn}, and R represents foreign key relations. Here, m and n denote the number of tables and column names, respectively. Finally, the Textto-SQL task could be formulated as:
Y = f(Q, S, K | θ), (1)
where the function f (· | θ) can represent a model or neural network with the parameter θ。

selector:four components: task description, instruction, demonstrations, and a test
example.
decomposer:动态判断用户问题的难度,如果可以回答通过一个简单的SQL查询,然后生成SQL直接地如果问题更复杂,则从最简单的子问题开始生成相应的SQL,然后逐渐分解以获得渐进的子问题,直到最终获得与该问题对应的SQL。
refiner:在接收到SQL时查询时,Refiner首先诊断SQL语句,以评估其语法正确性、执行情况可行性,以及非空结果的检索来自数据库。如果检查通过,结果作为最终答案输出;否则,将启动校正操作,如图5所示。然后对校正后的结果进行重新评估,如果问题持续存在,则重复该过程,直到结果是正确的或最大数量达到修改。具体修正这个过程涉及到基于原作的推理SQL和错误反馈信息或修改指导信号来生成修改后的结果。一般来说,Refiner的核心功能是为了实现的自检和自校正增强整体框架故障的模型。
Instruction-tuned SQL-Llama:指令微调 Code Llama 7B
DBCᴏᴘɪʟᴏᴛ 2024
https://github.com/tshu-w/DBCopilot
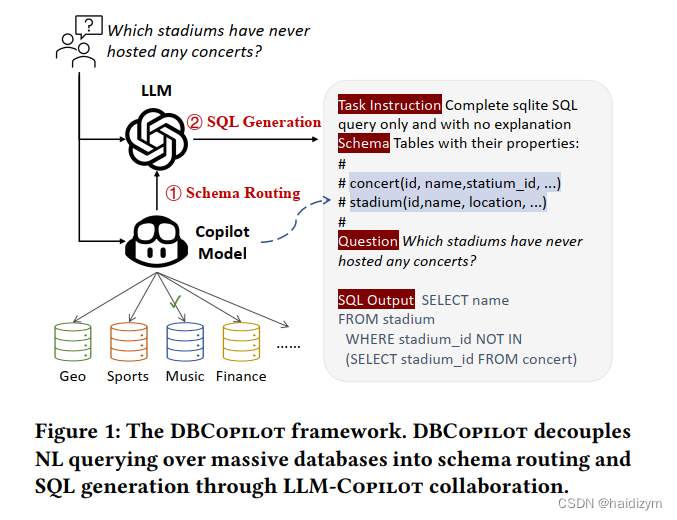
自然语言到SQL(NL2SQL)旨在转换自然语言(NL)问题转换为结构化查询语言(SQL)查询,方便非专家查询和分析数据库。这项任务在数据分析、商业智能等方面发挥着关键作用,以及其他数据库交互应用程序,因此引起了极大的关注[1,2,13,16,22,39]。最近出现的大型语言模型(LLM)带来了一种新的零/少样本学习NL2SQL范式,它通过LLM和schemaaware提示直接转换SQL查询,显示出巨大的前景[15,17,29,37,41]。然而,这方面的现有工作通常只集中在使用少数表查询单个数据库,忽略对海量数据库和数据进行查询的现实需求仓库[24,38,45]。在这种情况下,数据消费者需要进行投资手动识别和选择合适的数据库和相关表格。因此,当务之急是开发一种机制,将非专家用户从数据表示的复杂性,并使它们能够查询具有模式不可知NL问题的大规模数据库,即没有对大规模模式的理解。这个过程的核心是构造从不同NL问题到海量问题的语义映射数据库模型元素,从而自动识别目标数据库和过滤最少量的相关表。
本文引入一种紧凑而灵活的copilot模型作为跨大型数据库的路由器,以及利用LLM的高效NL2SQL功能生成最终SQL查询。具体而言,DBCopilot利用轻量级可微搜索索differentiable search index (DSI)[48]进行导航一个NL语言问题到其相应的数据库和表。然后,将路由的模式和问题输入LLM,以利用它们强大的语言理解能力生成SQL查询以及SQL生成功能。通过提出模式图构建、DFS序列化和受限解码,我们可以联合检索目标数据库表的端到端方式,同时考虑到结构关系。
生成检索[48,51](又称DSI)是一种新兴的范式,它训练Seq2Seq预训练语言模型(PLM),用于直接映射查询到相关文档标识符。它背后的主要思想是在单一神经模型,通过建模索引和检索操作转换为模型参数。在实践中,模式空间S=D×P(T)是巨大的,因为它是数据库集合D的笛卡尔乘积与幂所有表T的集合。为了缩小搜索空间,我们建议一种关系感知的模式端到端联合检索方法路由。培训过程如图2所示。明确地我们首先构造一个模式图来表示关系数据库和表之间(§3.2)。基于此图,我们设计用于序列化SQL查询模式的模式序列化算法转换为令牌序列,以便它可以由Seq2Seq DSI生成(§ 3.3). 为了解决DSI不能推广到看不见的模式的挑战,我们进一步提出了一种反向生成范式用于训练数据合成(§3.4)。这些措施使我们能够使用序列化的伪实例有效地训练模式路由器<𝑁 , 𝑆> 并将推理应用于基于图的约束解码(§ 3.5). 最后,我们探讨了各种提示策略来选择和将多个候选模式与LLM结合起来(§3.6)。
DIN-SQL 2023
https://github.com/mohammadrezapourreza/few-shot-nl2sql-with-prompting
(Decomposed In-Context Learning of Text-to-SQL with Self-Correction)
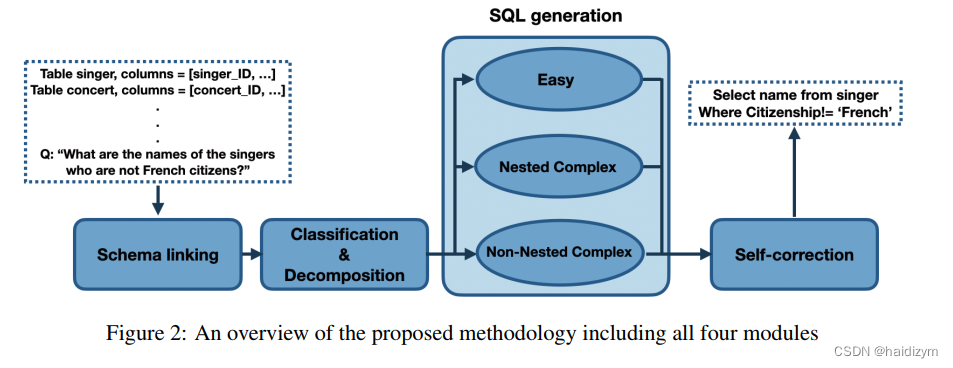
DIN-SQL方法的四个主要模块:模式链接(Schema Linking)、查询分类与分解(Classification & Decomposition)、SQL生成(SQL Generation)和自我修正(Self-Correction)。




Our contributions can be summarized as follows: (1) improving the performance of LLM-based textto-SQL models through task decomposition, (2) introducing adaptive prompting strategies tailored to
task complexity, (3) addressing schema linking challenges in the context of prompting, and (4) using
LLMs for self correction.
(1)通过任务分解提高基于大模型的text2sql模型的表现,(2)引入自适应的提示词策略来裁剪任务复杂度,(3)在提示词情境学习中处理模式链接挑战,(4)大模型自我纠正,
the thought process for writing SQL queries may be broken down to (1) detecting database tables and columns that are relevant to the query, (2) identifying the general query structure for more complex queries (e.g., group by, nesting, multiple joins, set operations, etc.), (3) formulating any procedural sub-components if they can be identified, and (4) writing the final query based on the solutions of the sub-problems.
写出sql查询语句的思维可以分解为(1)检测出与查询相关的数据表和列,(2)为更复杂的查询确认一般的查询结构 (e.g., group by, nesting, multiple joins, set operations, etc.),(3)如果能被识别,形成任何过程子组件,(4)基于子问题的解决写出最终的查询语句。
(1) schema linking, (2) query classification and decomposition,(3) SQL generation, and (4) self-correction
四个模块:(1)模式链接,(思维链)(2)查询分类和分解,(easy, non-nested complex and nested complex),(3)sql生成,(4)自我纠正
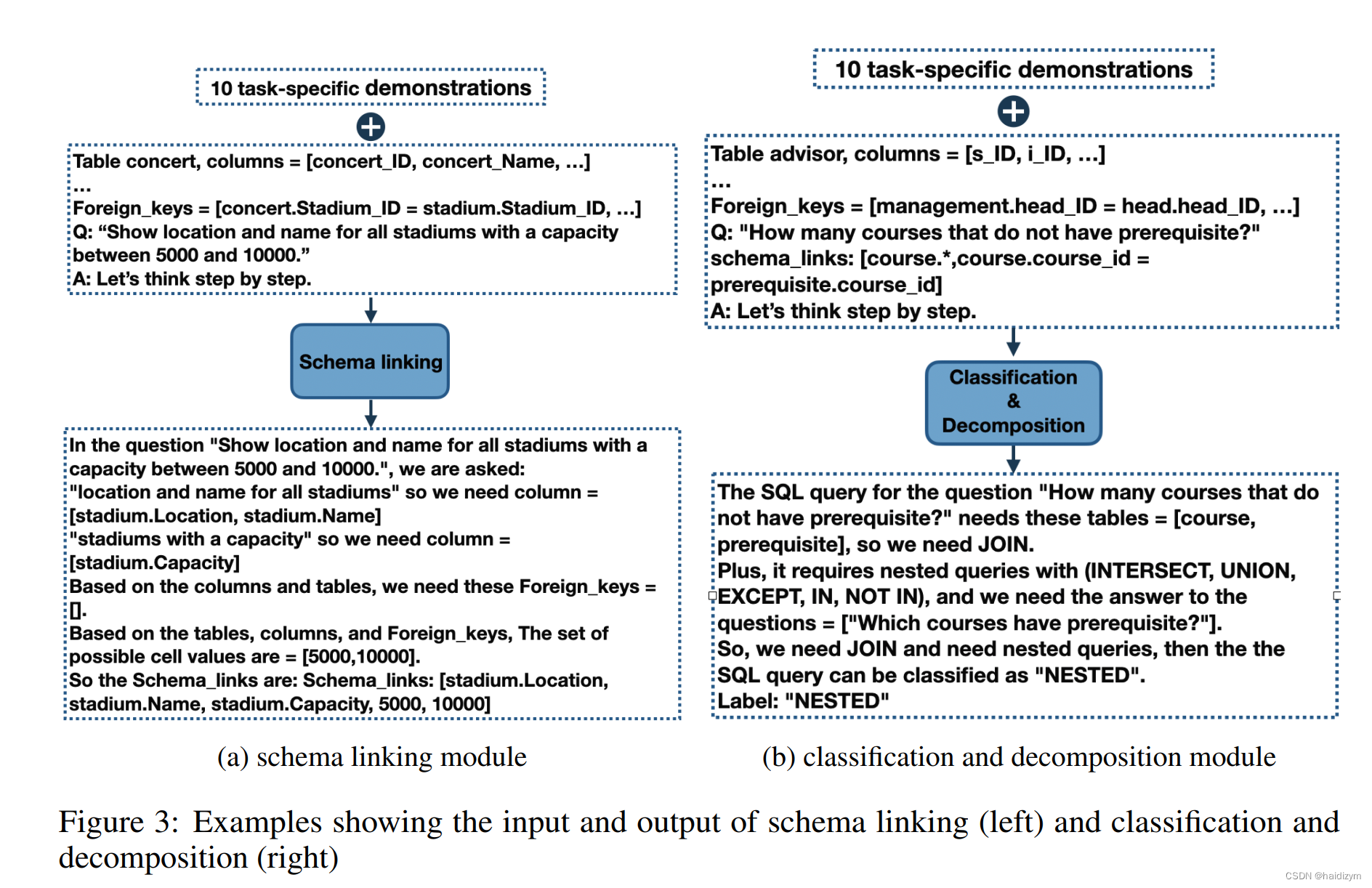
(2)查询分类和分解:
The easy class includes single-table queries that can be answered without join or nesting(无join和嵌套的单表查询). The non-nested class includes queries that require join but no sub-queries(要求join但无子查询), and the queries in the nested class can contain joins, sub-queries and set operations(包含join,子查询和集合操作的嵌套查询).
(3)sql生成:
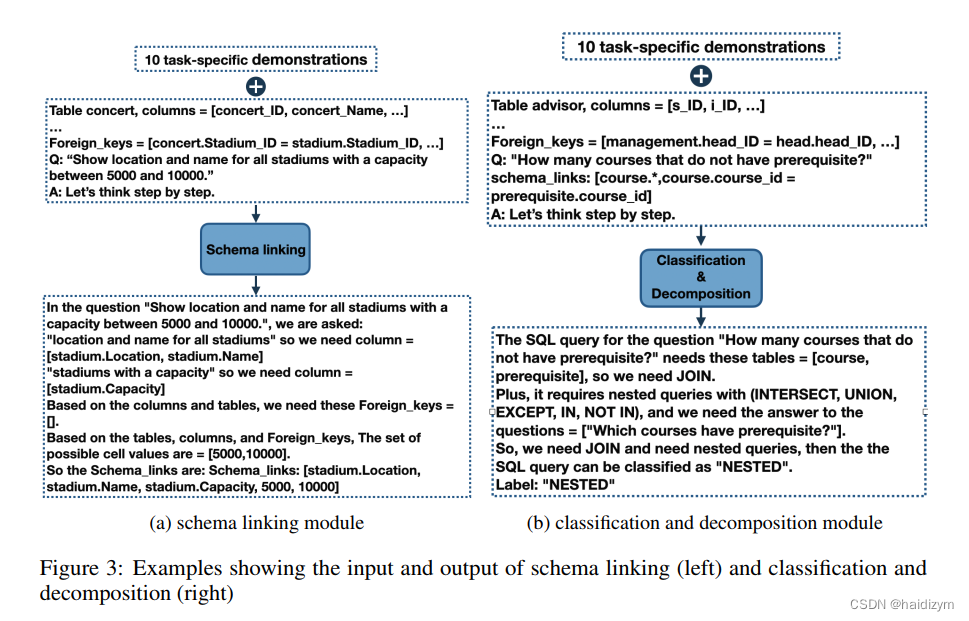
For questions in our easy class, a simple few-shot prompting with no intermediate steps is adequate.The demonstration for an example Ej of this class follows the format <Qj, Sj, Aj>, where Qj andAj give the query text in English and SQL respectively and Sj indicates the schema links.
非嵌套复杂:The demonstration for an example Ej of the non-nested complex class follows the format <Qj, Sj, Ij, Aj>, where Sj and Ij respectively denote the schema links and the intermediate representation for the jth example.(JOIN ON, FROM, and GROUP BY,WHERE,EXCEPT, UNION, and INTERSECT,DESC,DISTINCT and aggregation function )
嵌套复杂:The prompt for this class follows the format <Qj, Sj , <Qj1, Aj1, …, Qjk, Ajk> , Ij, Aj>, where k denotes the number of sub-questions, and Qji and Aji respectively denote the i-th sub-question and the i-th sub-query. As before, Qj and Aj denote the query in English and SQL respectively, Sj gives the schema links and Ij is a NatSQL intermediate representation.
(4)自我修正:generic and gentle















 1942
1942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









