







Direct I/O 操作(二)
【上回书说到,LSU的CC位能够表示正在进行的传输的状态。】
中断和LSU释放
LSU的CC位能够表示正在进行的传输的状态,自然也能显示出执行过程中的错误,而且一点出错,与这些错误有关的中断将迅速被上报给CPU。在上报处理阶段不会提交新的任务。
错误上报给CPU后,LSU只有在以下几种情况下才会被释放:
- CPU对restart或者flush位进行写入
- 如果对于未提交给CPU的transaction的所有响应都已经被接收,或者在接收响应时发生了超时。一旦发送响应超时,就不会有额外的中断或者CC位置位,来处理这次响应超时。如果接收到了所有响应,LSU就会只清除当前运行的transaction,并载入正在等待的一套寄存器。如果CPU写入了flush位,并且收到了所有响应,CPU将会清除掉影存器中的所有transaction,这里的影存器是特定LSU的影存器,这里的transaction是有特定SRCID_MAP 的transaction。如果restart和flush的命令都没有收到,但是收到了所有响应,外设将会一直等待直到收到CPU的restart或者flush超时信号。LSU将会抛弃所有transaction,包括当前拥有同一SRCID_MAP 的transaction导致的错误。在这之后,LSU会自动装载下一组数据。如果这部分看不懂的话,后面还会有对错误处理的进一步解释。
有8个寄存器集,这允许对所有需要响应的transaction类型提供8个突出请求。对于多核设备来说,软件对这些寄存器进行管理,通过共享配置总线VBUSP来管理这些寄存器。单核设备能利用全部8个LSU块。
Figure2-11显示了一个NWRITE_R类型的transaction,图中包括该transaction的数据流和域映射。
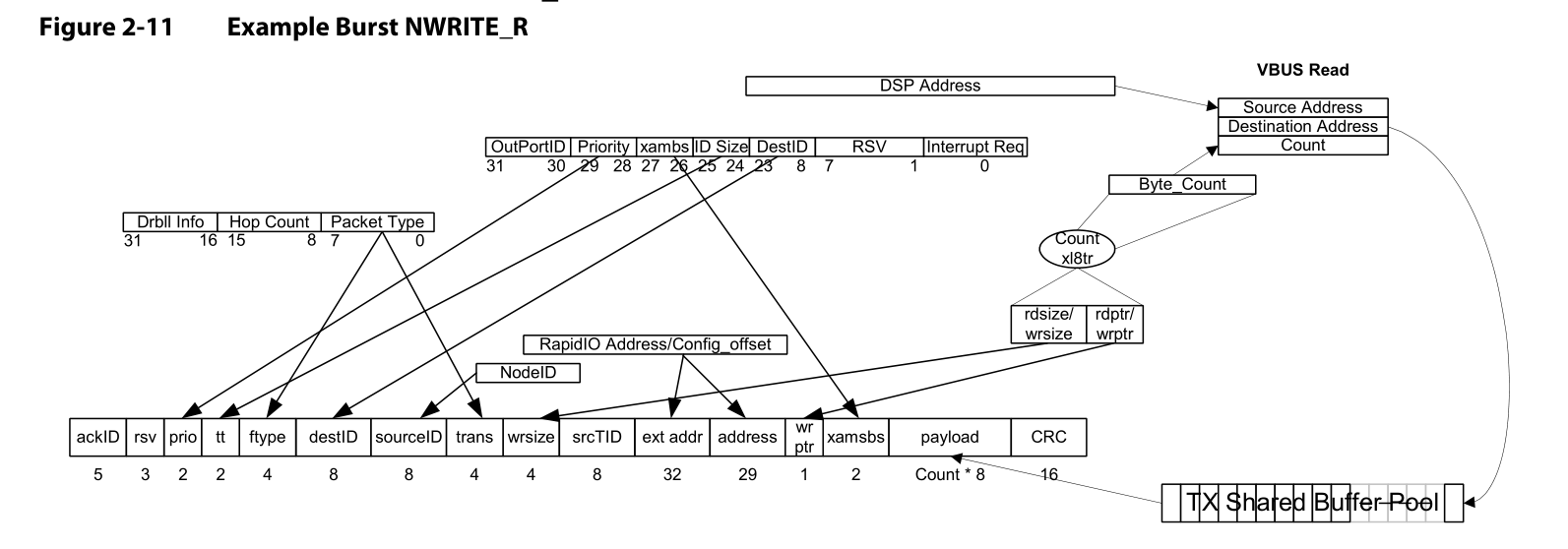
“写”类型的命令,它的payload(负载消息内容的一个指针)与来自控制/命令寄存器的header信息相结合,然后导入到TX SharedBuffer-Pool,即图中右下角所示。最终payload被传递到TX的FIFO队列中进行传输。
“读”类型的命令没有payload,所以就只有控制/命令寄存器的域被缓存,然后使用它来创建一个RapidIO NREAD 包,进而传递到TX FIFO队列进行传输。从接收接口传递相应的响应包时,READ响应包的payload在RX资源池中被缓存。提交和未提交给CPU的操作都基于OutPortID命令寄存器,这样设计是为了确定合适的输出口或者确定合适的输出队列。
数据以DMA时钟频率,向Load/Store模块发送。
具体数据路径描述
上面说的高大上的一堆话,总结一下Load/Store模块的作用就是产生directIO包。
这种接口不支持消息传递接口。插一句嘴,外向传送的DOORBELL(门铃)包也是通过这个接口产生的。每个LSU最多能支持16个SRCIDs,所以LSU0能够用SRCID0-15产生传输,LSU1能用SRCID16-31产生传输等等。每次LSU发出一个新的命令,就重新计算SRCID的数量,所以每次发出新的命令的时候,LSU1的SRCID总是从16开始的。
该模块的数据路径是以VBUSM总线作为DMA接口的。SRIO的payload最大值是256B,每个LSU都有可能产生多于一个VBUSM传输,为的是并行得到超过256B的payload。这些payload之后可以用UDI接口发送,当然为了区分这些传输,就要利用不同的SRCID,即使是发送给同一个LSU的,当响应包从UDI接口返回的时候还是能够分辨不同的transaction。
Figure2-12显示了发送数据的端口操作流程图。
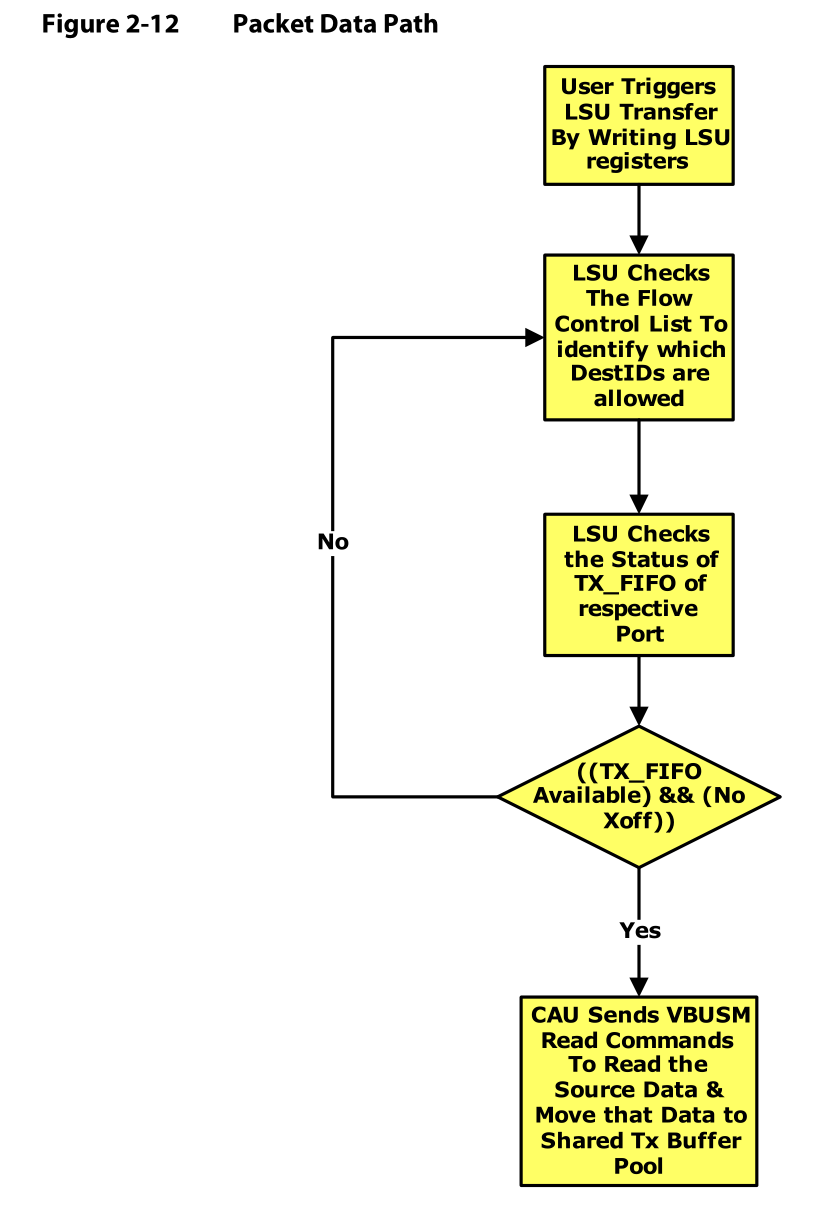
- 用户通过配置LSU寄存器出发LSU传输
- LSU检查流控列表来确定哪个DestID是可以用的
- LSU检查每一个port的TX_FIFO状态
- 如果TX_FIFO可用并且没有正在进行的传输,CAU就发送VBUSM Read Commands来读取来源信息,并且将来源信息移动到共享TX Buffer池;如果TX_FIFO可用和没有正在进行的传输,这两个条件有一个不存在,就回到检查流控列表确定DestID可用那一步。
CPU利用VBUSP配置总线和控制/命令寄存器。这些寄存器包含传输描述符,这些传输描述符需要初始化读/写包的产生。在传输描述符被初始化写好之后,就要确认流控状态。确认流控状态的模块检测命令寄存器的DESTID和PRIORITY域来确定流通道是否已经被占用,还有,TX FIFO的空闲状态也要被检查,该操作是通过检查命令寄存器的OutPortID实现的。只有在流控通道被打开,TX FIFO被分配缓存之后,才会产生一个VBUSM读命令,该读命令作用于将被移入到TXbuffer池的payload数据。数据以简单的顺序从共享buffer池移动到合适的输出TX FIFO,这种顺序基于VBUSM传输的completion情况。只要数据被传输到FIFO中,数据就一定能通过管脚发送。
Figure2-13显示了支持Load/store模块所需的数据路径和缓存。
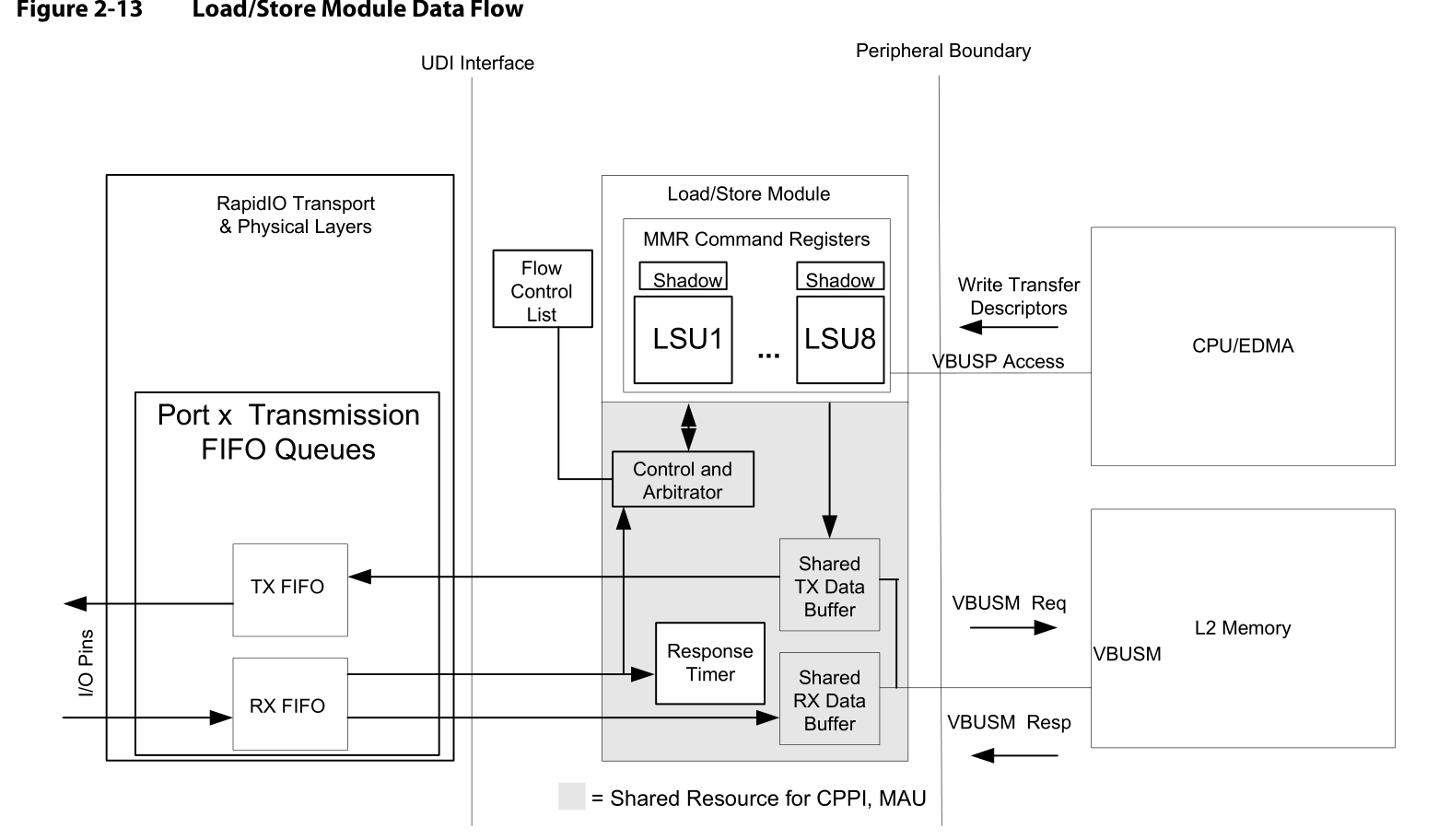
TX操作
写传输
Figure2-14显示了SRIO内部的缓存机制。
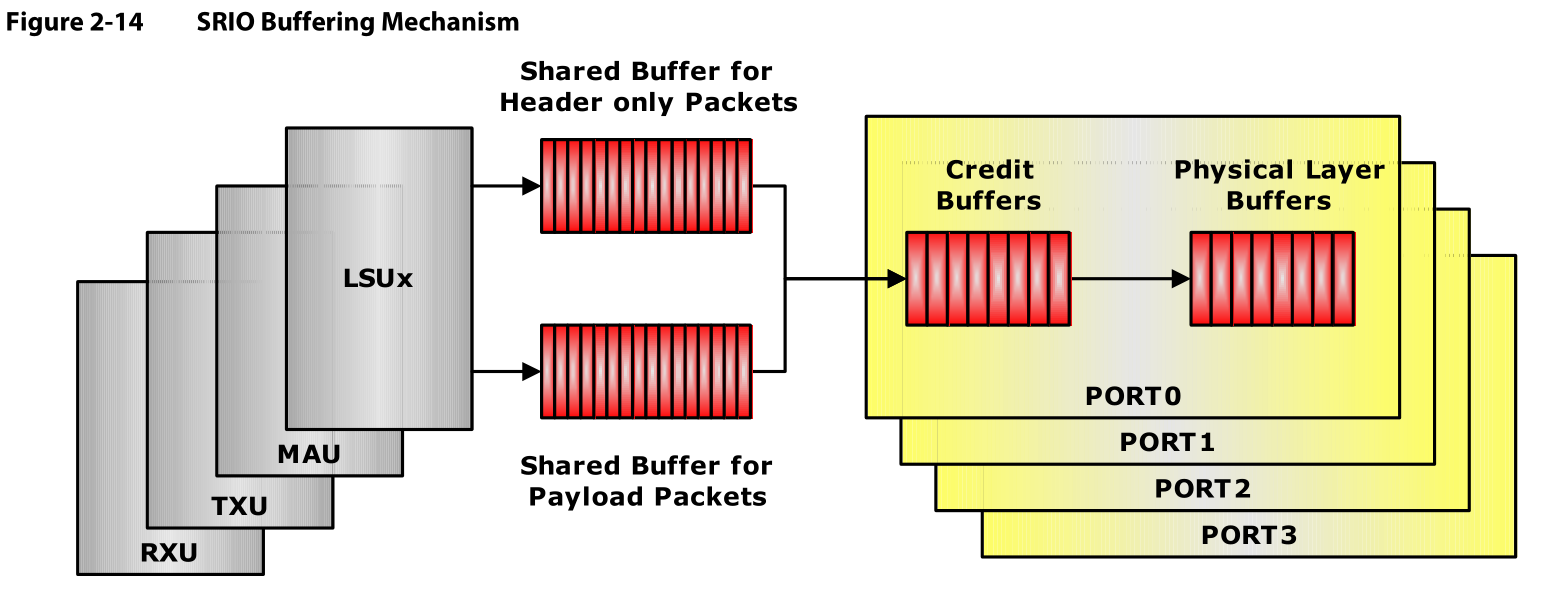
多核之间共用Shared TX Data Buffer。一个状态机在LSU和其他协议单元之间进行仲裁和分配可用的buffer。只有在来自VBUSM的payload的最后一个字节被写入Shared TX Data buffer之后,Load/Store模块才会把包送到TX FIFO,一旦包被送到TX FIFO,共享缓存就可以释放,并且用于其他transaction了。
TX缓冲区在所有输出源之间动态共享,这些输出源包括LSU,TX CPPI,来自RX CPPI和MAU的响应包。所以缓存空间存储需要分段对带payload的包和不带payload的包进行处理。
一条消息最多有16个包,每个包的最大尺寸是256B,同时还可以有不带payload只含header的包。数据以接收的顺序离开共享缓存,离开时不需要确认包的优先级,但是数据离开TX FIFO时需要考虑到优先级。
对于提交的WRITE操作不需要RapidIO响应包,一个核有可能提交各种各样的输出请求。例如,一个单一的核可能在任何给定的时间内让流写数据包进行缓存,并且提供了输出源。在这个例子中,一旦数据包写入共享TX缓存池,LSU就会释放给影存器。如果请求被流控,外设将设置completion code status register并且使用中断位ICSR。当中断路由完成的时候,控制/命令寄存器就会被释放。
对于未提交的WRITE操作需要RapidIO响应包,任何给定的时间里每个核只能有一个向外的请求。消息包会写入TX缓存池,当然,一直到响应包路由到原来的模块,并且状态寄存器中恰当的completion code被设置之后,LSU才可以释放。在原子输出测试和交换包中有一种特殊情况,这种包是唯一 一种需要有带有payload的响应的Write类型的包,这种响应的payload被路由到LSU,然后payload被检查以确认信号是否被收到,随后对completion code进行适当的设置。payload并没有通过VBUSM传出外设。
所以一般的流程是:
- 通过VBUSP(配置总线)配置控制寄存器
- 流控确认
- TX FIFO(TX共享缓存池)可用确认
- VBUSM读取对数据payload的请求
- VBSUM在共享TX缓存区域响应给特定模块缓存的写数据
- VBSUM读响应被监控,等待payload的最后一位
- 命令寄存器的header数据写入共享TX缓存空间
- 将payload和header传递给TX FIFO
- 如果不需要RapidIO响应,载入下一个影存器
- 基于优先级从TX FIFO传递数据给外部
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3886
3886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









