







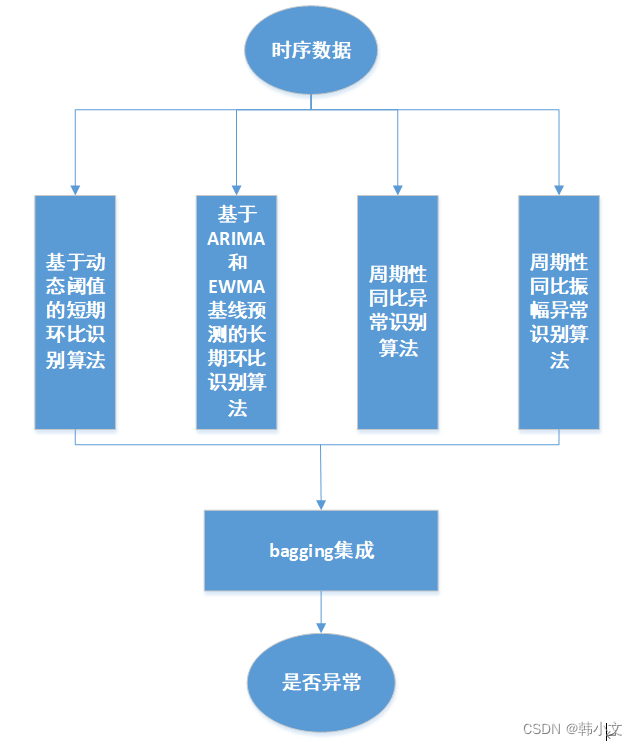
引言
异常检测的场景很多,例如:硬件的故障检测、流量的异常点的检测等场景。针对时间序列类数据的异常检测算法也有很多,业界比较流行的比如普通的统计学习方法–3σ原则和箱线图识别数据离群点,它利用检测点偏移量来检测出异常。比如普通的回归方法,用曲线拟合方法来检测新的节点和拟合曲线的偏离程度,还有人将CNN 和 RNN 技术应用到异常点的检测,但笔者通过大量的实践经验发现以上做法要么识别效果较差【比如:统计学习方法、回归方法】,要么部署难度较大【比如:RNN、CNN等】。
在综合考虑部署成本、实施可行性以及识别效果等方面,本方案提出了一种新的检测算法,此类方法在 LVS 流量异常检测中得到了很好的应用,本文将此类算法应用于污水处理领域的水质指标检测。
异常检测算法原理
1、短期环比(SS)
对于时间序列(是指将同一统计指标的数值按其发生的时间先后顺序排列而成的数列)来说,T时刻的数值对于T-1时刻有很强的依赖性。比如氨氮含量在8:00很大,在8:01时刻的概率是很大的,但是00:01时刻对于8:01时刻影响不是很大。
首先,我们可以使用最近时间窗口(T)内的数据遵循某种趋势的现象来做文章。比如我们将T设置为60,则我们取检测值(now_value)和过去60个(记为i)点进行比较,如果大于阈值我们将count加1,如果count超过我们设置的count_num,则认为该点是异常点。
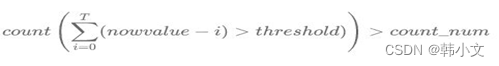
上面的公式涉及到threshold和count_num两个参数,threshold如何获取我们将在下节进行介绍,而count_num可以根据的需求进行设置,比如对异常敏感,可以设置count_num小一些,而如果对异常不敏感,可以将count_num设置的大一些,AI检测算法中的count_num设置为57,通过参数counter_thld(百分比)来控制。
动态阈值
业界关于动态阈值设置的方法有很多,今天介绍一种针对时间序列类异常检测的阈值设置方法。通常阈值设置方法会参考过去一段时间内的均值、最大值以及最小值,我们也同样应用此方法。取过去一段时间(比如T窗口算法设置为60min)的平均值、最大值以及最小值,然后取max-avg和avg-min的最小值。之所以取最小值的原因是让筛选条件设置的宽松一些,让更多的值通过此条件,减少一些漏报的事件。AI检测算法中为了降低误报率选择是max方法。
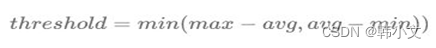
2、 长期环比(LS)
上面短期环比参考的是短期内的数据,而仅仅有短期内的数据是不够的,我们还需要参考更长时间内数据的总体走势。
通常使用一条曲线对该趋势进行拟合来反应曲线的走势,如果新的数据打破了这种趋势,使曲线变得不平滑,则该点就出现了异常。曲线拟合的方法有很多,比如回归、moving average 等等。在本文中,我们使用 EWMA,即指数权重移动平均方法来拟合曲线。在 EWMA 中,下一点的平均值是由上一点的平均值,加上当前点的实际值修正而来。对于每一个 EWMA 值,每个数据的权重是不一样的,最近的数据将拥有越高的权重。
有了平均值之后,我们就可以使用 3-sigma 理论来判断新的 input 是否超过了容忍范围。比较实际值是否超出了这个范围就可以知道是否可以告警了。
3、同比(chain)
很多监控项都具有一定的周期性,其中以一天为周期的情况比较常见,比如进水量在早上0点最低,而在晚上7点最高。为了将监控项的周期性考虑进去,我们选取了某个监控项过去7天的数据。对于某个时刻,将得到7个点可以作为参考值,我们记为xi,其中i=1,…,7。
我们先考虑静态阈值的方法来判断input是否异常(突增和突减)。如果input比过去7天同一时刻的最小值乘以一个阈值还小,就会认为该输入为异常点(突减);而如果input比过去7天同一时刻的最大值乘以一个阈值还大,就会认为该输入为异常点(突增)。
注:本方案针对污水处理变量指标的异常分析,指标变量的周期性明显为一周,此外,因为数据传输过程以及传感器收集数据都需要时间,会存在一定的时间延迟,因此,具体实施时取7天内每天同一小时内的最值代替这一时刻的值。
4、同比振幅(CA)
同比的方法遇到这样的现象就不能检测出异常。比如今天是10月1日【节假日】,假设过去14天的历史曲线比今天的曲线低很多。那么今天设备出了一个小故障,曲线下跌了,相对于过去14天的曲线仍然是高很多的。这样的故障使用以上方法就检测不出来,那么我们将如何改进我们的方法呢?一个直觉的说法是,两个曲线虽然不一样高,但是“长得差不多”。那么怎么利用这种“长得差不多”呢?那就是振幅了。
怎么计算t时刻的振幅呢? 我们使用x(t) – x(t-1) 再除以 x(t-1)来表示振幅。举个例子,例如t时刻的进水量为900,t-1时刻的是1000,那么可以计算出进水量下降了10%。如果参考过去14天的数据,我们会得到14个振幅值。使用14个振幅的绝对值作为标准,如果m时刻的振幅([m(t) – m(t-1)]/m(t-1))大于amplitudethreshold并且m时刻的振幅大于0,则我们认为该时刻发生突增,而如果m时刻的振幅大于amplitudethreshold并且m时刻的振幅小于0,则认为该时刻发生突减。
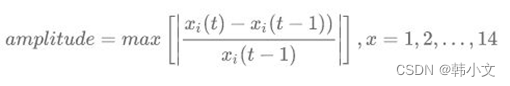
算法接口说明
算法封装为类AIDetector(),通过创建对象,调用方法run()进行异常诊断,具体参数如下:
timeseries:输入数据,格式为pandas的Series格式,数据长度必须大于一周数据。
short_term:用于短期环比的时间窗口,默认为60min
counter_thld:短期环比识别阈值,古玩论坛百分比格式,即当前值大于(小于)短期时间窗口内数值的百分比,默认为95%
threshold_method:动态阈值的取值方式,默认为max
long_time:长期环比的时间窗口,默认为一周
max_thld:同比突增的判断阈值,默认为2
min_thld:同比突降的判断阈值,默认为0.1
score:集成算法的投票阈值,默认为2.

















 1017
1017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









