







 本文回顾了统计机器翻译(SMT)的发展历程,从1980年代末IBM的研究起步,介绍了重要里程碑事件,如IBM提出的信源信道模型、五种统计翻译模型、BLEU评测方法等,以及Pharaoh系统的出现和Google翻译的成功。
本文回顾了统计机器翻译(SMT)的发展历程,从1980年代末IBM的研究起步,介绍了重要里程碑事件,如IBM提出的信源信道模型、五种统计翻译模型、BLEU评测方法等,以及Pharaoh系统的出现和Google翻译的成功。
做统计翻译系统(SMT,statistical machine translation)也有一段时间了,接触了大大小小好几个翻译系统,使用它们的同时也对其原理进行了一定的了解,阅读了一些中英文资料文献,对统计机器翻译的过程有了一个比较完整的认识,自己也做了一些笔记。比较详细的一本介绍统计机器翻译的书是Philipp Koehn写的《Statistical Machine Translation》,现在已有其中文译著《统计机器翻译》,我这里就这这本书的思路,加上一些其他的资料文献,对统计机器翻译做一个细致一些的讲解,希望能对大家有一些帮助。
下面是一些SMT发展过程中的大事记:
1980年代末IBM首次开展统计机器翻译研究, 1992年IBM首次提出统计机器翻译的信源信道模型, 1993年IBM提出五种基于词的统计翻译模型IBM Model 1-5, 1999年JHU夏季研讨班重复了IBM的工作并推出了开放源代码的工具, 2001年IBM提出了机器翻译自动评测方法BLEU, 2002年NIST开始举行每年一度的机器翻译评测,2002年Franz Josef Och提出统计机器翻译的对数线性模型, 2003年Franz Josef Och提出对数线性模型的最小错误率训练方法, 2004年Philipp Koehn推出Pharaoh(法老)标志着基于短语的统计翻译方法趋于成熟, 2005年David Chiang提出层次短语模型并代表UMD在NIST评测中取得好成绩,2005年Google在NIST评测中大获全胜,随后Google推出基于统计方法的在线翻译工具,其阿拉伯语-英语的翻译达到了用户完全可接受的水平,目前已经可以支持40多种语言的互译, 2006年NIST评测中USC-ISI的串到树句法模型第一次超过Google(仅在汉英受限翻译项目中)。
下面是对《统计机器翻译》一书第二章的总结和笔记:


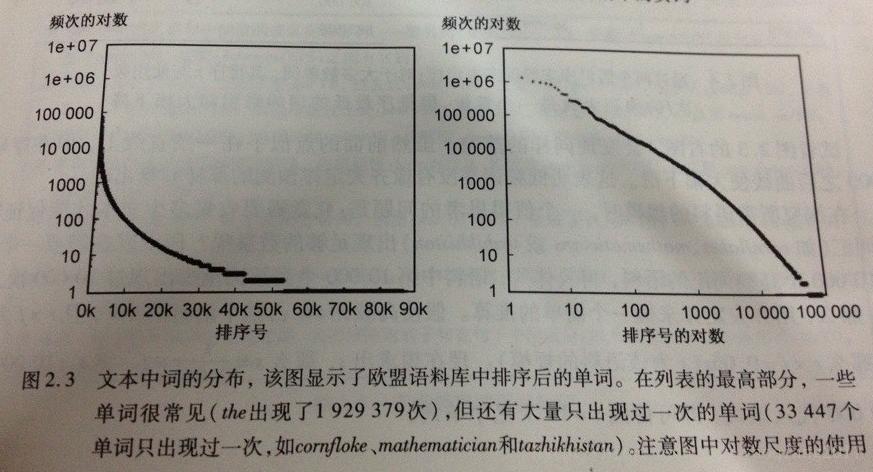
频次最高的词分布如下图所示:

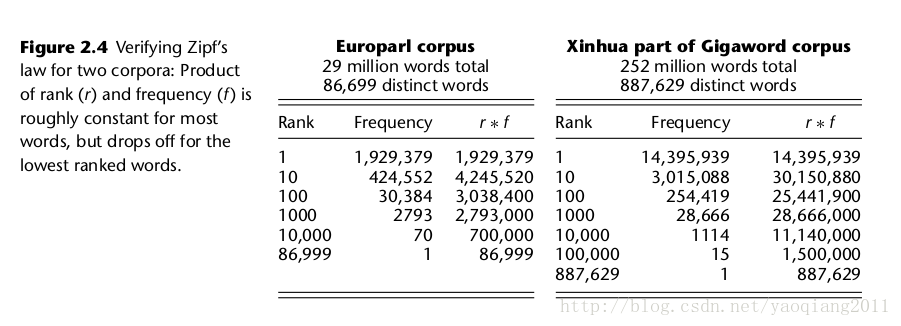
在欧盟语料库中,齐夫定律体现的很明确,具体数值分布和数值图示如下两图所示:

















 7311
7311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









