







参考博客https://blog.csdn.net/Quincuntial/article/details/78564389
Abstract
只要有足够的标签数据,增加模型尺寸和计算时间对大多数任务有用。Here we are exploring ways toscale up networks in ways,目的式通过适当的分解卷积核积极的正则化来尽可能地有效利用增加地计算。
Introduction
一个有趣地发现是再分类性能上地收益趋向于转换成各种应用领域上地显著质量收益,这意味着CNN的改进可以用来改善很多视觉任务的性能。
通过应用针对内存使用的专门解决方案【2】【15】或通过计算技巧优化某些操作的执行【10】,可以减轻部分这些问题。
复杂的Inception架构使改变网络变得更困难,如果简单的增加网络层,大部分的计算收益可能会丢失。例如,如果认为有必要增加一些Inception模型的能力,将滤波器组大小的数量加倍的简单变换将导致计算成本和参数数量增加4倍。这在许多实际情况下可能会被证明是禁止或不合理的,尤其是在相关收益适中的情况下。在本文中,我们从描述一些一般原则和优化思想开始,对于以有效的方式扩展卷积网络来说,这被证实是有用的。虽然我们的原则不局限于Inception类型的网络,但是在这种情况下,它们更容易观察,因为Inception类型构建块的通用结构足够灵活,可以自然地合并这些约束。这通过大量使用降维和Inception模块的并行结构来实现,这允许减轻结构变化对邻近组件的影响。但是,对于这样做需要谨慎,因为应该遵守一些指导原则来保持模型的高质量。
General Design Principles
以下原则的效用是推测性的,另外将来的实验证据将对于评估其准确性和有效领域是必要的。grave deviations from these principles 恶化网络质量,修正检测到的这些偏差可以改进结构。
1、前馈网络可以由输入到分类器或者回归器的非循环图表示,为信息流定义了一个明确的方向。对于分离输入输出的任何切口,可以访问通过切口的信息量。表示大小输入到输出缓慢减小。维度只提供了一个信息内容估计。
2、高维表征处理局部,在卷积网络中增加每个图块的激活允许更多的解耦特征。
3、空间聚合可以在较低维度嵌入完成,不会再表示能力上造成损失,如果再空间聚合上下中使用输出,则相邻单元之间的强想关心会导致维度缩减期间的信息损失更少。
4,并行增加宽度和深度达到恒定计算量的最佳改进
Factorizing Convolutions with Large Filter Size
GoogLeNet网络[20]的大部分初始收益来源于大量地使用降维。这可以被视为以计算有效的方式分解卷积的特例。此外,我们可以使用计算和内存节省来增加我们网络的滤波器组的大小,同时保持我们在单个计算机上训练每个模型副本的能力。
分解到更小的卷积
当然,5×5滤波器在更前面的层可以捕获更远的单元激活之间、信号之间的依赖关系,因此滤波器几何尺寸的减小带来了很大的表现力。由于我们正在构建视觉网络,所以通过两层的卷积结构再次利用平移不变性来代替全连接的组件似乎是很自然的。两个3*3代替5*5,如图1。


该设定通过相邻块之间共享权重明显减少了参数数量。我们最终得到一个计算量减少到(9+9)/25网络,通过这种分解导致了28%的相对增益。
如果我们的主要目标是对计算的线性部分进行分解,是不是建议在第一层保持线性激活?我们已经进行了几个控制实验(例如参见图2),图2。两个Inception模型间几个控制实验中的一个,其中一个分解为线性层+ ReLU层,另一个使用两个ReLU层。在三亿八千六百万次运算后,在验证集上前者达到了76.2% top-1准确率,后者达到了77.2% top-1的准确率。
3.2空间分解为不对称卷积
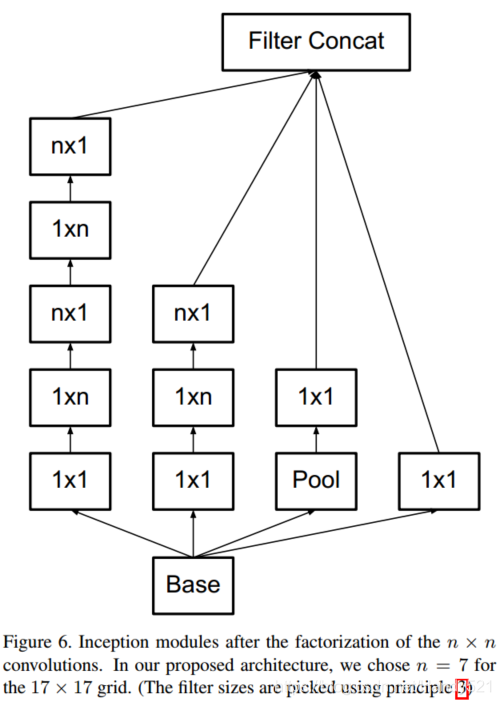
例如使用3×1卷积后接一个1×3卷积,相当于以与3×3卷积相同的感受野滑动两层网络(参见图3)。如果输入和输出滤波器的数量相等,那么对于相同数量的输出滤波器,两层解决方案节省33%。相比之下,将3×3卷积分解为两个2×2卷积表示仅节省了11%的计算量。(图6)实际上,我们发现,采用这种分解在前面的层次上不能很好地工作,但是对于中等网格尺寸(在m×m特征图上,其中m范围在12到20之间),其给出了非常好的结果。在这个水平上,通过使用1×7卷积,然后是7×1卷积可以获得非常好的结果。

4、辅助分类器的效用
5、有效的网络尺寸减少
6 inception v2
7 通过标签平滑进行模型正则化
8 训练方法
提出了一个42层测inception网络,然后是加上BN辅助网络,变成v3,这个网络比GoogLenet,和BN v2效果好














 696
696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









