






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
提示:这里可以添加本文要记录的大概内容:
函数是一种编程语言中的概念,用于封装可重复使用的代码块。
提示:以下是本篇文章正文内容,下面案例可供参考
一、函数是什么?
在Python中,函数是一组可重用的代码块,它接收输入参数,执行一系列操作,并返回一个结果。函数可以被多次调用,并且可以在程序中的不同位置使用。
在Python中定义一个函数使用关键字def后跟函数名和参数列表,参数列表用括号括起来。函数可以有零个或多个参数,并且可以有一个返回值。
目的:提高代码的复用,减少代码的重复编写
二、函数的定义及调用
-
def:define 定义一个函数
-
def 函数名(): pass
-
函数名的命名规则等同于变量名
-
冒号 开启一个语句块
-
语句块中编写函数功能的实现
-
调用:函数名()Eg:wake_up()
代码实例:
# 例子
# 封装一个函数:目的是为了叫醒守望tk
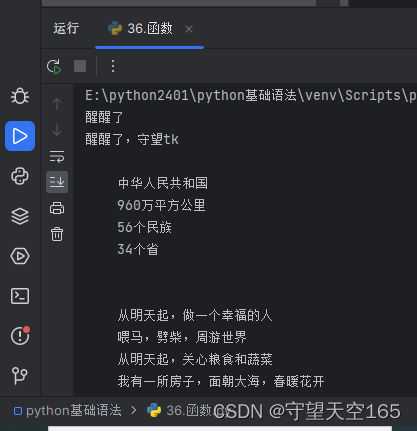
def wake_up():
print("醒醒了")
print("醒醒了,守望tk")
wake_up()
# 练习
def love():
print("""
中华人民共和国
960万平方公里
56个民族
34个省
""")
love()
def poem():
print("""
从明天起,做一个幸福的人
喂马,劈柴,周游世界
从明天起,关心粮食和蔬菜
我有一所房子,面朝大海,春暖花开
从明天起,和每一个亲人通信
告诉他们我的幸福
那幸福的闪电告诉我的
我将告诉每一个人
给每一条河每一座山取一个温暖的名字
陌生人,我也为你祝福
愿你有一个灿烂的前程
愿你有情人终成眷属
愿你在尘世获得幸福
我只愿面朝大海,春暖花开
""")
poem()
在Python中函数的定义和普通代码之间需要隔两行。

三、函数的形参、实参及返回值
1.形参、实参
-
形参:形式参数:出现在函数声明中的()中,没有固定值,调用函数时,将实参赋予形参。
-
实参:实际参数:出现在函数调用的()中
-
形参与实参:让函数功能更加灵活,函数功能更强大
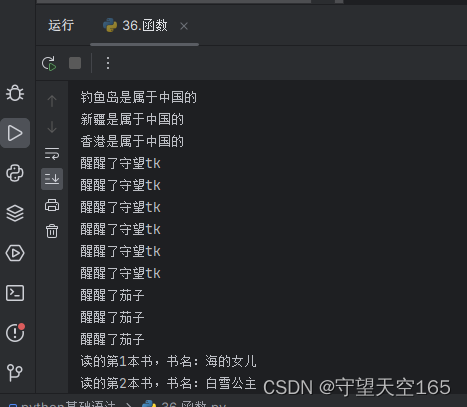
def ad(address):
print(f"{address}是属于中国的")
ad("台湾")
ad("钓鱼岛")
ad("新疆")
ad("香港")
# 答案:
# 台湾是属于中国的
# 钓鱼岛是属于中国的
# 新疆是属于中国的
# 香港是属于中国的
def wakeup(name, num):
for i in range(num):
print(f"醒醒了{name}")
wakeup("守望tk", 6)
wakeup("茄子", 3)
def read(name, num):
print(f"读的第{num}本书,书名:{name}")
read("海的女儿", 1)
read("白雪公主", 2)
习题
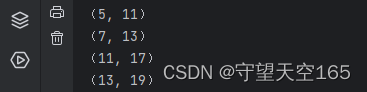
题目: 封装一个函数 求从start到stop之间相差为step的质数对
# stop + 1 - step ==> 防止最后一个质数对的最后一个质数不越界
# Eg:2,50,6:最后一个质数对为(47, 53)
def zhi_shu(start, stop, step):
for i in range(start, stop + 1 - step):
for j in range(2, i):
if i % j == 0:
break
else:
for k in range(2, i + step):
if (i + step) % k == 0:
break
else:
print(f"({i}, {i + step})")
zhi_shu(2, 20, 6)
2.函数的返回值
-
函数的运算结果:默认返回None,即没有返回值
-
使用return返回结果:return之后的代码不再执行,类似break;return 可以有多个返回值,最终将多个返回值放入一个元组
def my1():
pass
r = my1()
print(r) # None
# return之后的代码不再执行,类似break
def my1():
return 100
print("00")
r = my1()
print(r) # 100
# print("00")没有执行
def my_min(first, second):
"""
这是一个比较大小的函数(比较小的)
:param first: 第1个形参
:param second: 第2个形参
:return: 计算结果
"""
min_value = first if first < second else second
return min_value
r = my_min(1234, 56891)
print(r) # 1234
# 判断是否为质数
def is_prime(n):
"""
判断n是否为质数
:param n: 判定的数
:return: True为是质数 False为不是质数
"""
for i in range(2, n):
if n % i == 0:
return False
else:
return True
print(is_prime(97))
# 1000以内相差为6的质数对
for i in range(2, 1001 - 6):
if is_prime(i) and is_prime(i + 6):
print(i, i + 6)
def get_prime_pairs(start, stop, step):
"""
判定质数对
:param start:开始
:param stop: 结束
:param step: 步长
:return: 返回质数对列表
"""
result = []
for i in range(start, stop + 1 - step):
if is_prime(i) and is_prime(i + step):
result.append((i, i + step))
return result
r = get_prime_pairs(2, 30, 6)
print(r)
# 注意:return 可以有多个返回值,最后将返回值放入一个元组
def fun():
return 100, 200
r = fun()
print(r, type(r))
r1, r2 = fun()
print(r1, r2)
def fun():
for i in range(10):
if i == 5:
return i
print("i", i) # 0 ~ 4
r = fun()
print("r", r) # r 5
四、函数的调试
-
基础调试:步过:F8;恢复:直接执行下一个断点:F9
-
函数调试:进入:步入:进入自己定义的函数(F7),进入函数后就可以使用步过F8;退出:退出函数:将函数直接执行完(shift + F8)
五、函数变量的作用域
不推荐在循环外部使用循环内部定义的局部变量 ==> 函数内部定义的局部变量,函数外部不能使用
函数内部可以获取函数外部变量:变量已经被解释器解释,如果赋值,代表着函数内部声明了一个新的变量;新的变量和外部变量同名,函数执行结束内部变量销毁
在函数内部修改函数外部变量:使用关键字global,声明以后后续的变量都是函数外部的变量
# for中定义的临时变量i
# for循环结束i的值就是for中最后一次的值
# 不推荐在for外使用for内部定义的变量
for i in range(10):
print(i)
def f1(m):
# 是函数内部定义的局部变量(m, i),函数外部不能使用
i = 10
# m = 20
print(i, m)
f1(20)
# print(i, m) # 错误
a = 10
def f2():
# 第1种情况:认为a是外部变量,可以获取
# print(a)
# 第2种情况:因为后续有a的赋值,所以此处认为a尚未定义就直接使用
# print(a)
# a = 20
# a不是修改外部变量,而是在函数内部有一个新的变量a赋值为20,函数结束,此变量消失
# a = 20
# print(a)
# 第3种情况:使用关键字global声明使用的就是外部变量
global a
a = 20
print(a)
f2()
print(a)
六、参数的类型写法
1.位置参数
按照位置将实参依次赋予形参
# 位置参数
# 按照位置将实参依次赋予形参
def f1(a, b, c):
print(a, b, c)
f1(10, 20, 30) # 将10,20,30按照位置依次赋予a,b,c
# 10 20 30
2.默认参数
形参有默认值,调用时可以没有实参,位于所有形参的最后
def f2(a, b, c=100):
print(a, b, c)
f2(10, 20, 30) # 形参c被传递了实参,输出实参
f2(10, 20) # 形参c有默认值100,即使没有实参,输出默认值
# 10 20 30
# 10 20 100
3.关键字参数
- 通过指定将实参赋予那个形参,要求没有默认值的形参必须赋值
def f3(a, b, c=15, d=44):
print(a, b, c, d)
f3(100, 200, d=350)
# 想要将350赋予d,c就使用默认值,但如果不使用d=,那么会把350赋予c
4.可变列表(元组)参数
- 可以接受任意个数的参数,类型是元组,在默认值参数的前面
def f4(a, b, *args):
print(a, b, args, type(args))
f4(10, 20, 30, 40, 50) # 10 20 (30, 40, 50) <class 'tuple'>
5.可变字典参数
- 可以使用关键字赋值, 关键字不能是真实形参
# 可变字典
# 可变字典参数 可以使用关键字赋值,关键字不能是真实形参
# def f5(a, b, c, d,)
def f1(a, b, *args, **kwargs):
print(a, b, args, kwargs, type(kwargs))
f1(10, 20, 30, 40, 50, 70, d1=80)
def f1(x):
return x
print(type(f1), f1(100))
# 10 20 (30, 40, 50, 70) {'d1': 80} <class 'dict'>
# <class 'function'> 100
七、匿名函数
-
lambda 表达式
-
只支持最简单,最近的函数写法
-
冒号左边是形参列表,冒号右边是函数体,只支持基本格式
-
匿名函数:没有名字的函数,不用起名,但是相当于起了一个变量名
-
lambda不能独立存在 ,需要作为实参赋予函数的形参
def f6(x):
return x
print(type(f6), f6(100))
# 拉姆达
f7 = lambda: print("醒醒了")
print(type(f7)) # <class 'function'>
f7() # 醒醒了
f8 = lambda: 100 # def f8(): return 100
print(f8(), type(f8)) # 100 <class 'function'>
f9 = lambda x: x + 20
print(f9(65), type(f9)) # 85 <class 'function'>
f10 = lambda x, y: x + y
print(f10(29, 78), type(f10)) # 107 <class 'function'>
# lambda不能独立存在,需要作为实参赋予函数的形参
def f0():
print("守望tk")
def f11(i, f):
for i in range(i):
f()
f11(5, f0) # 结果:执行五次守望tk
# 将f0函数的实现结果作为一个整体,当做一个变量使用
f11(3, lambda: print("love")) # 执行3次love
# 相当于:
# f2 = lambda: print("love")
# f11(3, f2)
# lambda应用
# 1.
l = [1, 5, 6, 8, 3, 2]
# def f1(e):
# return e
#
#
# l.sort(key=f1)
l.sort(key=lambda e: e)
print(l)
# 2.
l = [{"name": "小王子", "age": 18, "note": "玫瑰"},
{"name": "一级律师", "age": 28, "note": "公理之下,正义不朽"},
{"name": "海的女儿", "age": 16, "note": "美人鱼"},
{"name": "全球高考", "age": 25, "note": "世界灿烂盛大,欢迎回家"}
]
# def f2(e):
# """
# 确定排列规则
# """
# return e["age"]
#
#
# l.sort(key=f2)
l.sort(key=lambda e: e["age"])
print(l)
print(max(l, key=lambda e: e["age"]))
print(min(l, key=lambda e: e["age"]))

八、递归函数
必须要有递归出口,保障程序能退出来;自己调用自己
- 递归不是高性能的,能不用就不用
- 有深度限制:import sys,获取递归深度;sys.getrecursionlimit(),修改递归最大深度;sys.setrecursionlimit(修改值)
例题
1.计算1+2+3+4+5+…+100
# 常规方法
total = 0
for i in range(1, 101):
total += i
print(total)
# 函数
def f(n):
# 递归出口
if n == 1:
return 1
else:
# 自己调用自己
return n + f(n-1)
r = f(100)
print(r) # 5050
2.阶乘
def f1(n):
if n == 1:
# 递归出口
return 1
else:
# 自己调用自己
return n * f1(n-1)
r = f1(5)
print(r) # 120
# 递归的默认最大深度为999
3.斐波那契数列
def f2(n):
if n == 1 or n == 2:
return 1
else:
return f2(n-1) + f2(n-2)
r = f2(9)
print(r) # 34
补充:获取递归深度
import sys
# 获取递归深度
print(sys.getrecursionlimit()) # 1000
# 修改递归最大深度
# sys.setrecursionlimit(200)
九、装饰器
在Python中,装饰器是一个函数,用于修改其他函数的功能。装饰器的主要作用是在不改变被装饰函数源码的情况下,为其添加额外的功能。装饰器通过在被装饰函数之前和之后执行代码,实现对函数的包装。
装饰器的核心是闭包和语法糖
基础流程:
-
1.定义基本函数
-
2.编写闭包
-
3.使用闭包加工原始函数
-
4.给闭包添加权限校验
-
5.函数调用
-
使用@装饰器语法糖(备注)
在装饰器中,有两个经典案例:登录校验和时间花销
核心1:闭包
闭包三要素:
- 1.外部函数嵌套内部函数
- 2.外部函数可以将内部函数返回
- 3.内部函数可以访问外部函数的局部变量
nonlocal:nonlocal的作用相当于global,但是nonlocal用于外部函数的局部变量
代码推导过程
# 正常
def f1():
print("f1")
def f2():
print("f2")
f1()
f2()
# 1.外部函数嵌套内部函数
# 嵌套
# 注意:内部函数的调用要在外部函数中
def f1():
print("f1")
def f2():
print("f2")
f2()
f1() # f1 f2
# 2.外部函数可以将内部函数返回
def f1():
print("f1")
def f2():
print("f2")
return f2
r = f1() # f1 # 因为f1的返回值为f2,所以r等同于f2
print(type(r)) # <class 'function'> , r的类型为function,所以可以直接调用
r() # f2
# 3.内部函数可以访问外部函数的局部变量
def f1():
print("f1")
i = 0
def f2():
# nonlocal的作用相当于global,但是nonlocal用于外部函数的局部变量
nonlocal i
i += 1
print("f2", i)
return f2
# r等同于f2(r内部保存了一个外部函数的变量i)
r = f1() # f1
r() # f2 1
r() # f2 2
r() # f2 3
如果不使用闭包,函数添加新功能就需要修改函数实现,重复代码很麻烦。
如同下方代码中,我们想要在“欢迎查看首页”、“欢迎查看购物车”、“欢迎查看个人中心”中添加用户校验,就需要在每一个函数中添加用户校验的代码。
提示:以下是代码解释内容,下面案例可供参考,嫌麻烦可以不看,有点累赘,只是展示一下不适用闭包的话会怎样。
def index():
username = input("请输入用户名")
if username == "admin":
print("欢迎查看首页")
else:
print("用户校验失败")
index()
def shop_char():
username = input("请输入用户名")
if username == "admin":
print("欢迎查看购物车")
else:
print("用户校验失败")
shop_char()
def ge_ren():
username = input("请输入用户名")
if username == "admin":
print("欢迎查看个人中心")
else:
print("用户校验失败")
ge_ren()
完整的闭包如下方所示:
# 简单例子
def f1():
print("f1")
def check(f):
print("check 开始")
# f()
return f
# print("check 结束")
# r = check(f1) # check 开始
# r() # f1
# check可以对f1进行加工,给f1添加新功能,但是没有更改f1
f1 = check(f1)
f1()
# 例子2
def f1():
print("f1")
def check(f):
print("check 开始")
username = input("输入用户名")
if username == "admin":
return f
else:
print("用户校验失败")
下方是对上方的解释代码(就是那个在{“欢迎查看首页”、“欢迎查看购物车”、“欢迎查看个人中心”中添加用户校验})进行补充后的:
完整的闭包代码(带流程的,与最开始的装饰器流程对应,除了最后的语法糖)
# 1.定义基本函数
def index():
print("欢迎来到首页")
def cart():
print("欢迎来到购物车")
def mine():
print("欢迎来到个人界面")
# login_required 通过闭包对f进行加工
# 2.编写闭包
# 3.使用闭包加工原始函数
# 4.给闭包添加权限校验
def login_required(f):
def check1():
username = input("输入用户名")
if username == "admin":
f()
else:
print("用户校验失败")
return check1
# r相当于check
# r = login_required(index)
# 5.函数调用
index = login_required(index)
index()
cart = login_required(cart)
cart()
mine = login_required(mine)
mine()
核心2:语法糖
格式:@装饰器语法糖
将上一个代码采用语法糖,具体代码如下:
# 引入装饰器
def login_required(f):
def check2():
username = input("输入用户名")
if username == "admin":
f()
else:
print("用户校验失败")
return check2
# 语法糖
@login_required
def index():
print("欢迎来到首页")
@login_required
def cart():
print("欢迎来到购物车")
@login_required
def mine():
print("欢迎来到个人中心")
index()
cart()
mine()
个人练习,别看了!
# 登录校验
def login_request(f):
def check():
username = input("输入用户名")
pwd = int(input("输入密码"))
if username == "守望天空" and pwd == 123456:
f()
else:
print("您的用户名或密码错误")
return check
@login_request
def index():
print("欢迎来到汉服知识网站")
def learn():
print("朝代分类")
print("秦朝")
print("殷商")
print("盛唐")
print("强汉")
print("大明")
print("清朝")
@login_request
def my_center():
print("欢迎来到个人中心(*^▽^*)")
index()
learn()
my_center()
经典案例2:时间花销
这一节开头介绍了装饰器的两大比较经典的案例,分别是登录校验和时间花销,登录校验在闭包和语法糖的讲解中已经涉及,下面介绍时间花销。
在前几篇的文章中介绍了一个模块和其中的一个概念叫做时间戳,不知是否还记得,本次时间花销需要用到时间戳。
具体介绍请见这篇文章:https://blog.csdn.net/hanqing_165/article/details/135509158
时间戳:time.time()
# 装饰器
def time_cost(f):
def kx():
start = time.time()
f()
print(time.time() - start)
return kx
例题
题目:随机0-1000以内的500个数字放入列表,使用冒泡排序与选择排序对列表进行升序,编写装饰器,统计两个方法的时间开销
在这道题中请注意:生成数字放入列表L0中,但是在冒泡排序后L0是已经排好序的,再进行选择排序的时间比较不太公平,所以我们需要将L0中的数字再形成一个一模一样的新列表,这两个列表内容一样但不是一个列表
l0 = []
for i in range(500):
l0.append(random.randint(0, 1000))
# 因为列表是可变类型
# 所以得到第一个列表以后,将第一个列表内容复制组成一个新列表
# 两个列表互不干扰
l1 = [i for i in l0]
# 装饰器
def time_cost(f):
def kx():
start = time.time()
f()
print(time.time() - start)
return kx
# 冒泡
@time_cost
def mp():
for k in range(0, len(l0) - 1):
for j in range(k + 1, len(l0)):
if l0[k] > l0[j]:
l0[k], l0[j] = l0[j], l0[k]
# 选择排序
@time_cost
def xz():
for m in range(len(l1) - 1):
min_index = m
for j in range(m + 1, len(l1)):
if l1[min_index] > l1[j]:
min_index = j
if min_index != i:
l1[m], l1[min_index] = l1[min_index], l1[m]
mp()
xz()
扩展:多个装饰器
装饰器距离函数越近越先装饰
如下方代码被注释掉的部分(# @time_cost # @login_required)这个表示了先进行登录校验,再进行时间的计算(把登录校验的时间一并算上了,如果用户一直停留在登录校验界面不往下方进行,那么时间花销将较大)
# 扩展
# 多个装饰器
def login_required(f):
def check1():
username = input("输入用户名")
if username == "守望天空":
f()
return check1
def time_cost(f):
def cost():
start = time.time()
f()
print(f"时间花费{time.time() - start}")
return cost
# 装饰器距离函数越近越先执行
@login_required
@time_cost
# @time_cost
# @login_required
def index():
print("我是一个完整的函数")
index()
十、内置函数
| 内置函数 | 用法 |
|---|---|
| len | 长度 |
| – | – |
| 数学 | |
| abs | 绝对值 |
| divmod | 求整除和余;第一个为整除,第二个为求余 |
| pow | 次方 |
| round | 四舍五入 |
| sum | 求和 |
| all | 所有元素都是真,结果就是真;如果内容为空,返回真 |
| any | 所有元素都是假,结果才是假;如果内容为空,返回假 |
| – | – |
| 进制 | |
| bin | 将十进制转二进制 |
| hex | 将十进制转换十六进制 |
| oct | 将十进制转换八进制 |
| callable | 可调用:函数、类名 |
| – | – |
| ASCII | |
| chr | 将ascii值转字符 |
| ord | 将字符转ascii码值 |
| sorted | 根据ascii排序 |
| – | – |
| 局部与全局变量 | |
| locals | 返回所有局部变量,在函数内部使用 |
| globals | 返回全局变量 |
| – | – |
| 输入输出 | |
| input | 输入 |
| 输出 | |
| – | – |
| id | 返回对象唯一标识 |
| max、min | 最大最小 |
| – | – |
| 未来学习 | |
| delattr | 删除属性 |
| getattr | 获取属性 |
| hasattr | 是否有属性 |
| setattr | 设置属性 |
"""
本次代码将会演示内置函数
"""
# Python自带的函数
# 长度
print(len("hello")) # 5
# 绝对值
print(abs(-6)) # 6
# divmod:求整除和余
# 返回的为元组,第一个为整除,第二个为余数
print(divmod(100, 3)) # (33, 1)
# all:所有元素都为真结果为真,有一个为假,就为假
# 内容为空,结果也为True
print(all([0, 1, False])) # False
print(all([0, 1, True])) # False
print(all([10, 1, True])) # True
print(all([])) # True
# any:所有元素为假,结果才是假
# 内容为空,返回假
print(any([10, 0, False])) # True
print(any(["", 0, False])) # False
# bin:进制转换:将十进制转换为二进制
print(bin(10)) # 0b1010
# callable:可调用的
# 可调用的只有函数和类
print(callable(10), callable(lambda x: x)) # False True
# ASCII值
# chr:将ASCII值转字符,ord:将字符转ASCII值
print(chr(97), ord("A")) # a 65
# 本宫乏了,实例代码没有写完,仿照着写就可以了
总结
以上就是今天要讲的内容,本文介绍了Python中函数的使用,包含了函数的定义、调用、形参实参返回值、调试、变量作用域、参数的类型写法、匿名函数、递归函数、内置函数以及装饰器等9大内容,希望能对嫩们有些帮助














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









