






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
提示:这里可以添加本文要记录的大概内容:
本文主要介绍Python中的re正则表达式,后面还有简单的有re的爬虫实例哦
千万不要走开啊!!!!
提示:以下是本篇文章正文内容,下面案例可供参考
一、re是什么?
Python中的re模块是正则表达式的模块,提供了用于处理正则表达式的函数和方法。正则表达式是一种强大的模式匹配工具,可以用来在文本中查找、替换特定的字符串
re:正则,字符串的处理方法,用于匹配、搜索、替换字符串的模块
优势:执行效率特别高
缺点:可读性不强
二、常用方法
大大们,别忘了导入模块,此为重中之重!!!!
import re
1.字符匹配
-
. ==> 匹配任意字符
-
\d 数字
-
\D 非数字
-
\w 字母数字下划线
-
\W 非字母数字下划线
-
\s 空白字符:空格 制表符 换行符
-
\S 非空白字符
代码如下(示例):
# \d :数字
r = re.findall(r"\d", "hello333 +-7*/")
print(type(r), r)
# <class 'list'> ['3', '3', '3', '7']
# \D :非数字
r = re.findall(r"\D", "hello333 +-7*/")
print(type(r), r)
# <class 'list'> ['h', 'e', 'l', 'l', 'o', ' ', '+', '-', '*', '/']
r = re.findall(r"\d\D", "he4llo333 +-7*/")
print(type(r), r)
# <class 'list'> ['4l', '3 ', '7*']
# \w :字母数字下划线
r = re.findall(r"\w", "he4l_333 +-7*/")
print(type(r), r)
# <class 'list'> ['h', 'e', '4', 'l', '_', '3', '3', '3', '7']
# \W :非字母数字下划线
r = re.findall(r"\W", "he4l_333 +-7*/")
print(type(r), r)
# <class 'list'> [' ', '+', '-', '*', '/']
r = re.findall(r"\w\W", "he4l_333 +-7*/")
print(type(r), r)
# <class 'list'> ['3 ', '7*']
# \s :空白字符、空格、制表符、换行符
# \S :非空白字符、空格、制表符、换行符
r = re.findall(r"\s", "he4l\t_333 +-7*/ wor\n$^ld")
print(type(r), r)
# <class 'list'> ['\t', ' ', ' ', '\n']
r = re.findall(r"\S", "he4l\t_333 +-7*/ wor\n$^ld")
print(type(r), r)
# <class 'list'> ['h', 'e', '4', 'l', '_', '3', '3', '3', '+', '-', '7', '*', '/', 'w', 'o', 'r', '$', '^', 'l', 'd']
r = re.findall(r"\s\S", "he4l\t_333 +-7*/ wor\n$^ld")
print(type(r), r)
# <class 'list'> ['\t_', ' +', ' w', '\n$']
2.函数及方法
-
match 从开头匹配 返回Match实例 或者None
补:(有一个不是就为空) ==> hello和 hi:h匹配,e和i不匹配 ==> 空 -
fullmatch:匹配整个字符串,从头开始到最后
-
search 匹配整个字符串 返回Match
(类似match,但search是在整个字符串找匹配的,不用在意第一个) -
findall 找到所有匹配的 返回列表
-
finditer 找到所有,返回迭代器
-
split 切割 返回列表
-
sub:替换 (模式、替换内容、字符串、次数) 返回字符串
-
subn 返回元组(“新字符串”, 替换次数)
代码如下(示例):
# match:第1个参数是模式(字符串 == > 特殊字符)
# 第2个参数是目标字符串,第3个参数是附加选项
# 匹配成功返回Match实例,匹配失败返回None
# 从头开始匹配
# 匹配成功,使用group返回匹配成功的值
# 补:(有一个不是就为空) ==》 hello和 hi:h匹配,e和i不匹配 ==》 空
z = re.match("hello", "hello word")
print(z, type(z), z.group())
# <re.Match object; span=(0, 5), match='hello'> <class 're.Match'> hello
z = re.match("hello", "hi word")
print(z, type(z))
# None <class 'NoneType'>
# fullmatch:匹配整个字符串,从头开始到最后
r = re.fullmatch(r"\d{3}", "123")
print(r, type(r))
if r:
print(r.group())
# <re.Match object; span=(0, 3), match='123'> <class 're.Match'>
# 123
# search:匹配整个字符串
# (类似match,但search是在整个字符串找匹配的,不用在意第一个)
r = re.search(r"\d", "a2b3c")
print(r, type(r))
if r:
print(r.group())
# <re.Match object; span=(1, 2), match='2'> <class 're.Match'>
# 2
# findall : 找到所有,返回列表
r = re.findall(r".", "hello world +-*/%/")
print(type(r), r)
# <class 'list'> ['h', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', ' ', '+', '-', '*', '/', '%', '/']
# finditer 找到所有,返回迭代器
r = re.finditer(r"\d", "1a2b3c")
print(r, type(r))
for e in r:
print(e, type(e), e.group())
# <callable_iterator object at 0x00000186B70C3C10> <class 'callable_iterator'>
# <re.Match object; span=(0, 1), match='1'> <class 're.Match'> 1
# <re.Match object; span=(2, 3), match='2'> <class 're.Match'> 2
# <re.Match object; span=(4, 5), match='3'> <class 're.Match'> 3
# sub:替换
# 模式、替换内容、字符串、次数
r = re.sub(r"\d", "+", "1a2b3c4d", 3)
print(r, type(r))
# +a+b+c4d <class 'str'>
# subn 返回元组("新字符串", 替换次数)
r = re.subn(r"\d", "+", "1a2b3c4e5f6g7h")
print(r, type(r))
# ('+a+b+c+e+f+g+h', 7) <class 'tuple'>
3.重复
| 字符 | 代表含义 |
|---|---|
| * | 出现0-n次 |
| + | 有1-n次 |
| ? | 有0或1个 |
| .* | 默认是贪婪模式(尽可能多的匹配) |
| .*? | 非贪婪模式(尽可能少的匹配) |
| {n} | 匹配n次 |
| {m,n} | 匹配m-n次 |
# *:可有可无,可以有无数个
print("********* 重复 *********")
r = re.search(r"a*", "abcabcabcabc")
print(r, type(r))
if r:
print(r.group())
# <re.Match object; span=(0, 1), match='a'> <class 're.Match'>
# a
r = re.findall(r"a*", "aaaabcabcabc")
print(r, type(r))
# ['aaaa', '', '', 'a', '', '', 'a', '', '', ''] <class 'list'>
# a*b ==》 任意多个a和一个b
r = re.findall(r"a*b", "aaaabcabcabc")
print(r, type(r))
# ['aaaab', 'ab', 'ab'] <class 'list'>
# a+ ==》 至少有一个a
r = re.findall(r"a+", "aaaabcabcabc")
print(r, type(r))
# ['aaaa', 'a', 'a'] <class 'list'>
r = re.findall(r"a+b", "aaaabcabcabc")
print(r, type(r))
# ['aaaab', 'ab', 'ab'] <class 'list'>
# ? ==》 没有/有一个
r = re.findall(r"a?", "aaaabcabcabc")
print(r, type(r))
# ['a', 'a', 'a', 'a', '', '', 'a', '', '', 'a', '', '', ''] <class 'list'>
r = re.findall(r"a?b", "aaaabcabcabc")
print(r, type(r))
# ['ab', 'ab', 'ab'] <class 'list'>
# 常见 ==> .*?
r = re.findall(r".*", "aa111bc")
print(r, type(r))
# ['aa111bc', ''] <class 'list'>
r = re.findall(r".?", "aa111bc")
print(r, type(r))
# ['a', 'a', '1', '1', '1', 'b', 'c', ''] <class 'list'>
r = re.findall(r".*?", "aa111bc")
print(r, type(r))
# ['', 'a', '', 'a', '', '1', '', '1', '', '1', '', 'b', '', 'c', ''] <class 'list'>
# {} : 匹配
# {n} : 匹配n次
# {m,n} : 匹配m-n次
r = re.findall(r"\d{2}", "12345")
print(r, type(r))
# ['12', '34'] <class 'list'>
r = re.findall(r"\d{2,3}", "12345")
print(r, type(r))
# ['123', '45'] <class 'list'>
r = re.findall(r"\d{2,4}", "12345")
print(r, type(r))
# ['1234'] <class 'list'>
4.边界
-
^:以…开头
-
$ :以…结尾
-
\b 匹配单词边界
-
\B 匹配非单词边界
# ^ : 以...开头
# $ : 以...结尾
r = re.search(r"^a.*?d$", "a1cc23+-d")
# 以a开头,以d结尾,中间任意字符
print(r.group())
# a1cc23+-d
# 单词边界: 有空格才认为是一个单词
# 类似空格字符
r = re.findall(r".*?\s.*?", "hello world I am china ")
print(r, type(r))
# "hello world I am china" == > ['hello ', 'world ', 'I ', 'am ']
# "hello world I am china " == > ['hello ', 'world ', 'I ', 'am ', 'china ']
r = re.findall(r".*?\b", "I love china")
print(r)
# ['', 'I', '', ' ', '', 'love', '', ' ', '', 'china', '']
# 非单词边界
r = re.findall(r".*?\B", "I love china")
print(r)
# ['I l', '', 'o', '', 'v', '', 'e c', '', 'h', '', 'i', '', 'n', '']
5.标识符
-
re.I 忽略大小写
-
re.M 多行模式: 如果有换行符
# re.I:忽略大小写
z1 = re.match("hello", "Hello", re.I)
print(type(z1), z1.group())
# match='Hello'> <class 're.Match'> Hello
# re.M == 多行模式
r = re.findall(r"^a.*?d$", "a1cc23+-d\na111222d\n+++", re.M)
print(r)
# ['a1cc23+-d', 'a111222d']
6.特殊字符
-
[abcdefg] 只能取其中一个
-
[ ^abcdefg] 不在abcdefg中间
-
[a-zA-Z0-9_ ] 所有字母数字下划线 ,相当于 \w
# []:只能取其中一个
r = re.findall(r"a[bc]d", "abdacdaedafd")
# 匹配abd或者acd
print(r)
# ['abd', 'acd']
# 变种:a-z ==》 a到z全部小写字母
r = re.findall(r"a[a-z]d", "abdacdaedafd")
print(r)
# ['abd', 'acd', 'aed', 'afd']
# 所有字母数字下划线 _相当于 \w
r = re.findall(r"a[a-zA-Z0-9_]d", "abdaAdCAAaea2d223")
print(r)
# ['abd', 'aAd', 'a2d']
7.分组
- () 分组
- \n 取前面的分组匹配的内容
- ( | ) 分组
# () 分组
# # 匹配连续重复的字符
r = re.findall(r"(.)\1+", "Heelloooooo, Worrlddd!!")
print(r)
# ['e', 'l', 'o', 'r', 'd', '!']
r = re.findall(r"(\d)a\1", "1a12a23a3")
print(r)
# \1与\d的数字一样
# ['1', '2', '3']
# (|)
r = re.findall(r"(\d|a)-\d", "1-1a-3, 4-5")
print(r)
# ['1', 'a', '4']
三、简单爬虫实例
这里基本上是百度贴吧的爬取实例
1.高校专题
后续的小爬虫基本均是点击检查找的网址码哦
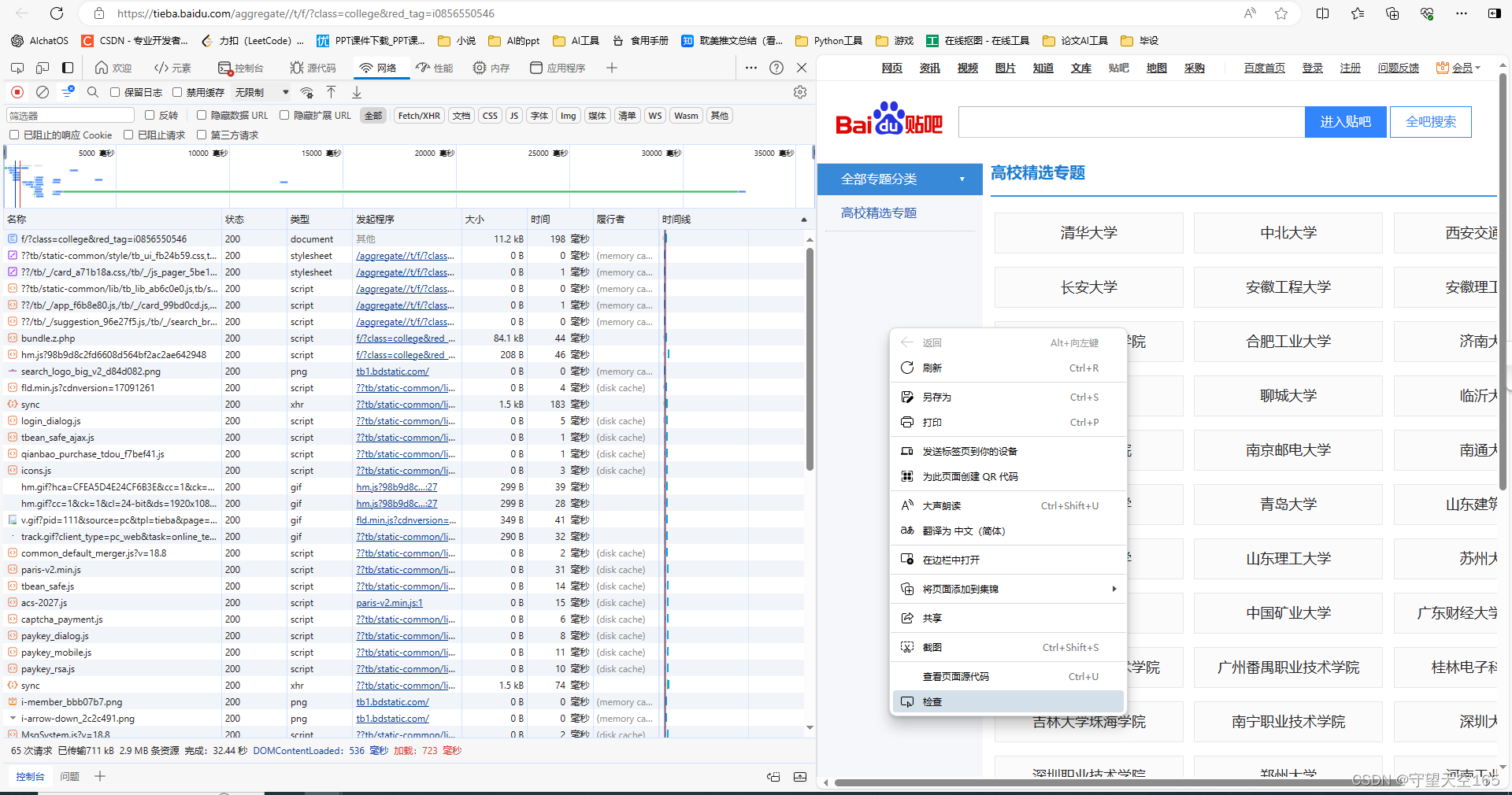
在检查中选择网络,别忘了刷新网页哦

在响应的代码中找到你需要获取的,进行re正则替换就可以了,就像上面的

替换后就是上方的代码了
以下为完整代码:
import json
import re
import time
from urllib import request
# 高校专题
result_datas = []
res = request.urlopen("https://tieba.baidu.com/t/f/?class=college")
# 解码
res = res.read().decode()
result = re.findall(r'<a class="each_topic_entrance_item" href="//tieba.baidu.com/t/f/(\d+)" data-fid="\1">(.*?)</a>',
res)
# 模块
for school in result:
# print(f"https://tieba.baidu.com/t/f/{school[0]}", school[1])
res_school = request.urlopen(f"https://tieba.baidu.com/t/f/{school[0]}")
res_school = res_school.read().decode()
school_obj = {
"name": school[1],
"modules": []
}
modules = re.findall(r'<div class="module_item">(.*?)</ul></div>', res_school)
for module in modules:
module_name = re.findall(r'<p class="module_name">(.*?)</p>', module)[0]
nums = re.findall(r'<div class="thread_item_left">(\d+)</div>', module)
titles = re.findall(r'<a class="thread_title" href="//tieba.baidu.com/p/\d+">(.*?)</a>', module)
contents = re.findall(r'<div class="thread_content thread_type_word.*?"><p>(.*?)</p><img src=.*?></div>',
module)
module_obj = {
"name": module_name,
"items": []
}
for i in range(len(nums)):
module_obj["items"].append({
"num": nums[i],
"title": titles[i],
"content": contents[i]
})
school_obj["modules"].append(module_obj)
result_datas.append(school_obj)
# 保存
# 保存文件时要记得使用 encoding="utf8"(保存汉字时一般采用)
# ensure_ascii=False ==》 使打开的json文件内容为汉字而不是2进制形式
with open("百度贴吧高校专题--正则爬虫.json", "w", encoding="utf8") as f:
f.write(json.dumps(result_datas, ensure_ascii=False))
爬取成功后会在代码文件下方出现一个json文件
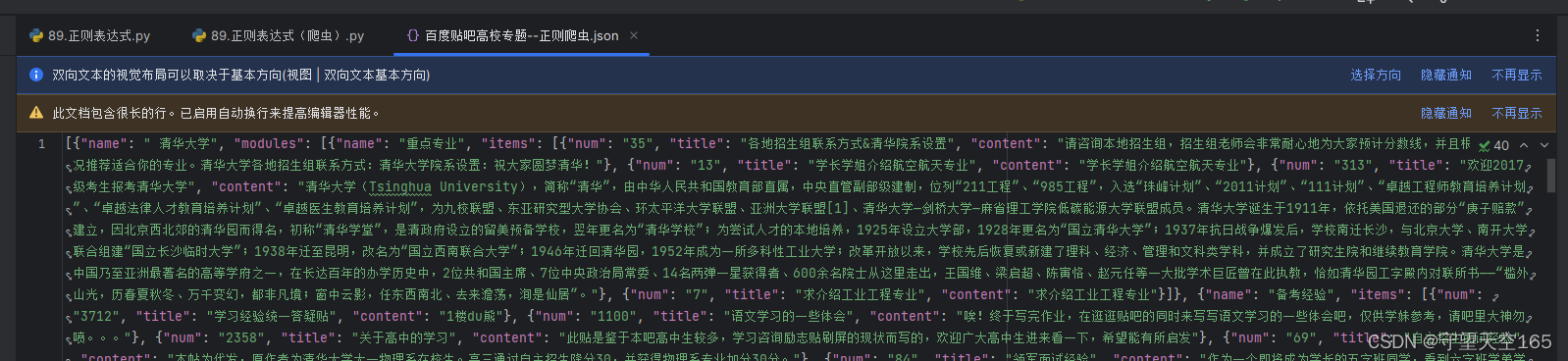
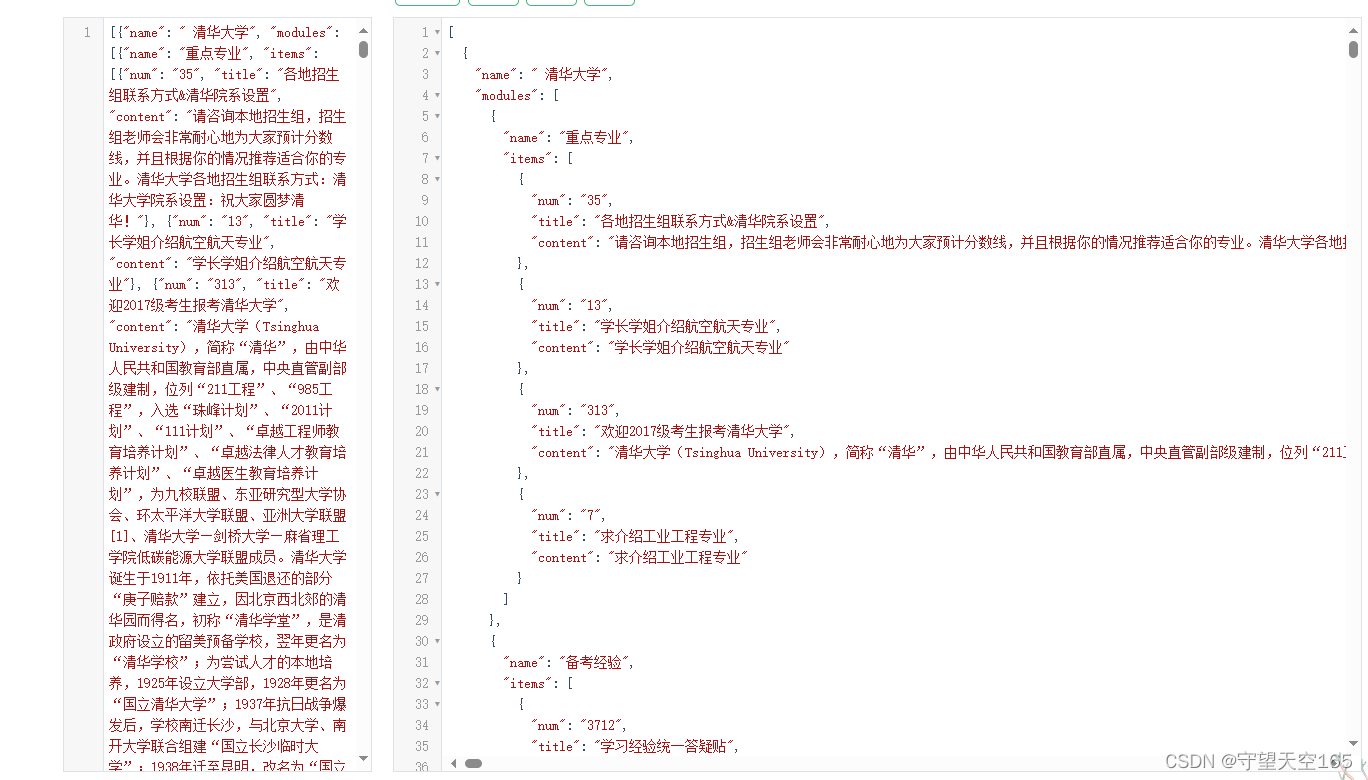
爬取出来的结果可以使用一个json在线工具进行格式化,就好看多了
这个是我的json格式化工具
https://www.toolhelper.cn/JSON/JSONFormat
2.热议榜单
result_datas = []
res = request.urlopen("https://tieba.baidu.com/hottopic/browse/topicList?res_type=1")
res = res.read().decode()
result = re.findall(r'<li class="topic-top-item">(.*?)</li>', res)
for hot_division in result:
title = re.findall(r'class="topic-text">(.*?)</a>', hot_division)
hort = re.findall(r'<span class="topic-num">(.*?)</span>', hot_division)
content = re.findall(r'<p class="topic-top-item-desc">(.*?)</p>', hot_division)
result_datas.append({
"标题": title,
"热度": hort,
"内容": content
})
with open("百度贴吧热搜榜单--正则爬虫.json", "w", encoding="utf8") as f:
f.write(json.dumps(result_datas, ensure_ascii=False))
3.体育迷
result_data = []
for page in range(1, 31):
res = request.urlopen(
f"https://tieba.baidu.com/f/index/forumpark?cn=&ci=0&pcn=%E4%BD%93%E8%82%B2%E8%BF%B7&pci=275&ct=&st=new&pn={page}")
res = res.read().decode()
result = re.findall(r'<div class="ba_info(.*?)</div>', res)
print(f"当前正在爬取第{page}页,数据{len(result)}条")
for sport in result:
tem_name = re.findall(r'<p class="ba_name">(.*?)</p>', sport)
note = re.findall(r'<p class="ba_desc">(.*?)</p>', sport)
m_num = re.findall(r'<span class="ba_m_num">(\d+)</span>', sport)
p_num = re.findall(r'<span class="ba_p_num">(\d+)</span>', sport)
result_data.append({
"吧名": tem_name,
"标注": note,
"关注人数": m_num,
"评论数": p_num
})
time.sleep(5)
with open("百度贴吧体育迷.json", "w", encoding="utf8") as f:
f.write(json.dumps(result_data, ensure_ascii=False))
悄咪咪的说一声别忘了在程序中添加一个短暂休眠的time.sleep(2) 以防被封哦,就像这里
总结
以上就是Python中re模块的简单介绍,通过re模块可以方便地进行正则表达式的匹配、搜索、替换等操作。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









