







原文链接:https://www.techbeat.net/article-info?id=3942&isPreview=1
作者:黄斐
本文将介绍清华&字节跳动 AI Lab NLP 等在 ICML 2022 上发表的并行生成模型学习理论。该理论指出,条件总相关 (Conditional Total Correlation) 是数据分布的一个重要属性,其大小将严重影响并行生成模型的学习难度。 同时,该研究发现,现有的大部分模型都等价于优化同一目标 MPLE,其本质在减小数据集中的条件总相关,因此提升了模型性能。该理论将现有模型统一到同一框架下,标志着对并行模型理解的进一步深入,引导了未来的并行模型设计。

作者单位:
1 The CoAI group, Tsinghua University
2 Institute for AI Industry Research, Tsinghua University
3 University of California Santa Barbara † Work done at ByteDance AI Lab
论文链接:
https://arxiv.org/abs/2206.05975
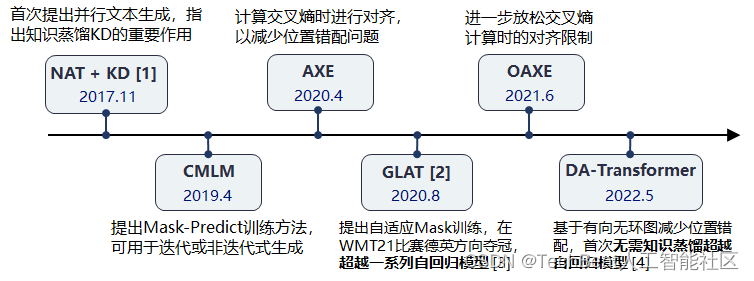 图1:并行(非自回归)生成模型中的典型方法
图1:并行(非自回归)生成模型中的典型方法
近年来,并行文本生成模型(非自回归模型)的飞速发展引发了学界的广泛关注。与传统自回归模型相比,并行生成模型能够显著减少生成解码时的延迟,在最近的工作中取得了相近甚至更好的生成质量。
与自回归模型不同,直接使用最大似然估计 (Maximum Likelihood Estimation, MLE) 优化并行模型会生成不流畅的句子。目前虽然已有较多工作从不同的角度缓解了该问题,但仍缺少统一的理论解释。
本文将介绍一篇来自 ICML 2022 的论文。该论文从统一视角揭示了并行生成模型的学习奥秘,其中包含两个要点:
- 并行模型学习中的挑战主要来自于数据集的本身特性。 数据集的条件总相关 (Conditional Total Correlation) 越高,并行模型学习会损失更多的信息,生成性能也会越差。
- 已有模型的成功实质上具有同样的深层原因。 这些模型通过构造新的目标分布来减少数据集中的条件总相关,因此减少了学习中的信息损失
一、背景:自回归模型和并行模型的训练目标
传统自回归文本生成模型,例如自回归 Transformer (Autoregressive Transformer, AT),通过逐词预测的方式分解整句话的生成概率。在该分解下,我们通常使用最大化似然估计 (Maximum Likelihood Estimation) 训练AT模型。

近年来,并行生成模型因其高效的解码过程获得了大量关注。非自回归 Transformer (Non-Autoregressive Transformer, NAT) 尝试在解码过程中同时、独立地预测每一个词。在该假设下,最大似然估计的训练目标如下图所示。

实验表明,仅仅优化并行模型的似然函数并不一定能带来性能的提升,下面一个例子可以说明这一点。
例子:似然概率与生成质量的背离
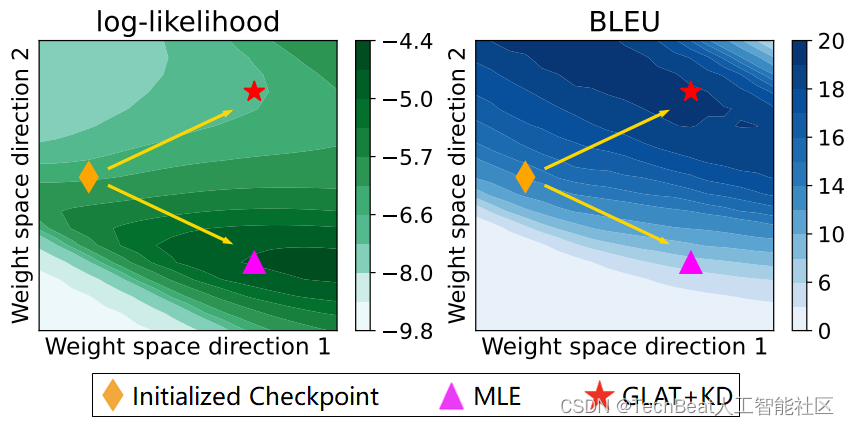
图2:使用传统 MLE 和其他优化方法 (GLAT+KD) 训练 NAT 模型的轨迹(二维平面投影)。以上数据在WMT14 En-De 机器翻译数据集获得。
上图的例子分别选用了 MLE 和另一种 NAT 训练方法 (GLAT+KD, [2]),从同一 Checkpoint 开始训练。结果显示,MLE 训练可以提升模型的似然概率 (Likelihood),但最终却降低了生成质量 (BLEU);GLAT+KD 的结果恰好相反。 这说明,传统的最大似然估计在 NAT 训练中并不奏效。
二、挑战从何而来:数据集的条件总相关 (Conditional Total Correlation)
该工作指出,NAT 模型在 MLE 优化下的生成质量与数据集本身的特性具有较大的联系。在介绍具体概念之前,我们先观察一个直观的例子。
直观理解:为何MLE无法提升生成质量
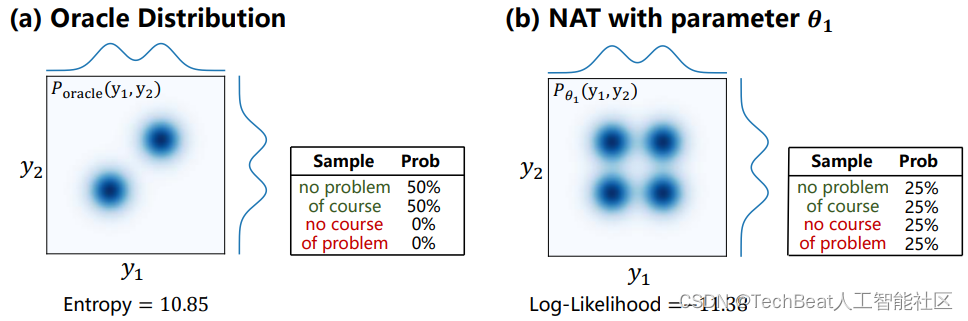
图3:(a) 目标数据分布。
y
1
,
y
2
y_1,y_2
y1,y2 分别代表句子中的两个词。左侧使用了连续分布,可以类比为表格中的离散分布。 (b) 使用 MLE 训练的 NAT 模型。注意 NAT 需要满足独立预测性质,因此
P
θ
1
(
y
1
,
y
2
)
=
P
θ
1
(
y
1
)
P
θ
1
(
y
2
)
P_{\theta_1}(y_1, y_2)=P_{\theta_1}(y_1)P_{\theta_1}(y_2)
Pθ1(y1,y2)=Pθ1(y1)Pθ1(y2) 。
上图展示了给定目标分布 (a) 下,NAT模型 (b) 的拟合情况。可以看到,NAT虽然可以完美地拟合数据的边际分布 (marginal distribution),但丢失了词间的关联信息,因此生成不正常的词语搭配(例如 “no course” 或 “of problem”)。
理论解释:条件总相关导致信息丢失
在上一个例子中,我们看到使用 MLE 训练的 NAT 模型将丢失一部分信息。那具体来说,这部分丢失信息和什么有关,又是否能被减轻呢?该工作证明了以下定理:
定理1: 给定数据集 P data ( Y ∣ X ) P_{\text{data}}(Y|X) Pdata(Y∣X) ,NAT模型的信息损失可以表示为 D KL ( P θ ( Y ∣ X ) ∣ ∣ P data ( Y ∣ X ) ) \mathcal{D}_{\text{KL}}(P_{\theta}(Y|X)||P_{\text{data}}(Y|X)) DKL(Pθ(Y∣X)∣∣Pdata(Y∣X)) ,其最小值不低于数据集的条件总相关 C C C 。
其中,条件总相关是数据分布的一种属性[5],其物理含义为: X X X 已知时,目标序列 Y Y Y 中每个词之间的关联信息大小。当数据分布确定后,该属性值也已经确定。
该定理有两点推论:
- 通过 MLE 训练的 NAT 模型,其信息损失恰好为数据的条件总相关 C C C 。
- 任何 NAT模型,若数据分布已确定,无论使用何种训练手段,其信息损失将不少于条件总相关 C C C 。
上述推论表明,数据集的条件总相关为 NAT 训练中的最大障碍,它使得传统的 MLE 训练失效,同时也无法通过简单的方法来减少学习中的信息损失。

图4:文章选取了多个数据集展示条件总相关
C
\mathcal{C}
C 和生成质量的关系。
Δ
BLEU
\Delta \text{BLEU}
ΔBLEU 为 MLE 训练下 AT 与 NAT 的生成质量差距。总体来说,数据集的条件总相关越小,NAT 的生成质量越好。
三、并行模型学习的统一视角
上一节的推论表明,NAT 模型学习时的信息损失由数据分布完全确定,仅仅调整训练方法将无法减少该信息损失。那么已有的 NAT 模型是如何取得更好的生成质量呢?
通过观察 NAT 中现有的训练方法,该工作发现:大部分 NAT 的训练方法均构造了一个新的分布用于减少数据集中的条件总相关,并取代了原始数据分布优化模型。 其中,被构造的新分布被称为代理分布。
代理分布 Proxy Distribution
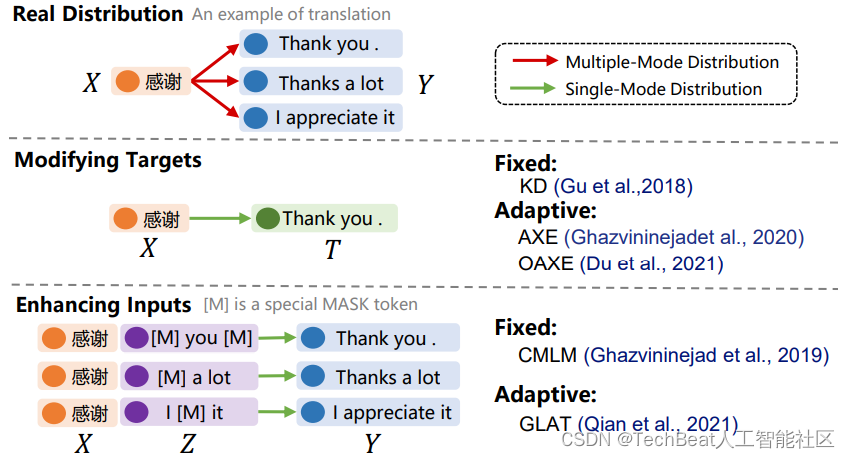
图5:NAT典型训练方法中构造代理分布的示意图
如上图,NAT的典型训练方法通过两类手段构造了代理分布:
- 修改输出目标( Y → T Y\rightarrow T Y→T )。例如:知识蒸馏 (KD) 使用自回归模型的输出来替代原始数据集的目标。
- 增强输入( X → X , Z X \rightarrow X, Z X→X,Z )。例如:CMLM 引入被 Mask 过的目标作为提示,输入给解码器。
除图中所示的方法外,文章还分析了其他的一些方法与构造代理分布的关系,包括:隐变量模型、迭代式模型、预测长度倍增模型 (CTC与DA-Transformer) 等。
统一学习框架 :Maximum Proxy-Likelihood Estimation
基于以上分析,该工作提出了统一的学习框架——最大代理似然估计 (Maximum Proxy-Likelihood Estimation,MPLE)。该框架的训练目标可以简单写为:
L MPLE = D KL ( Q ∣ ∣ P θ ) + R ( Q , P data ) \mathcal{L}_{\text{MPLE}} = \mathcal{D}_{\text{KL}}(Q ||P_{\theta}) + \mathcal{R}(Q, P_{\text{data}}) LMPLE=DKL(Q∣∣Pθ)+R(Q,Pdata)
该目标分为两项:
- 修改的 MLE 目标。 第一项在原始 MLE 的目标基础上,将真实数据替换为了代理分布 Q Q Q ,以优化 NAT 模型 P θ P_{\theta} Pθ 在 Q Q Q 上的似然函数。
- 与真实数据偏差。 第二项约束了代理分布 Q Q Q 与真实数据 P data P_{\text{data}} Pdata 分布间的差距。
该工作进一步通过变分理论的推导,得到了以上 MPLE 训练目标的可计算形式,此处不再赘述。
实验验证:MPLE 减少信息损失
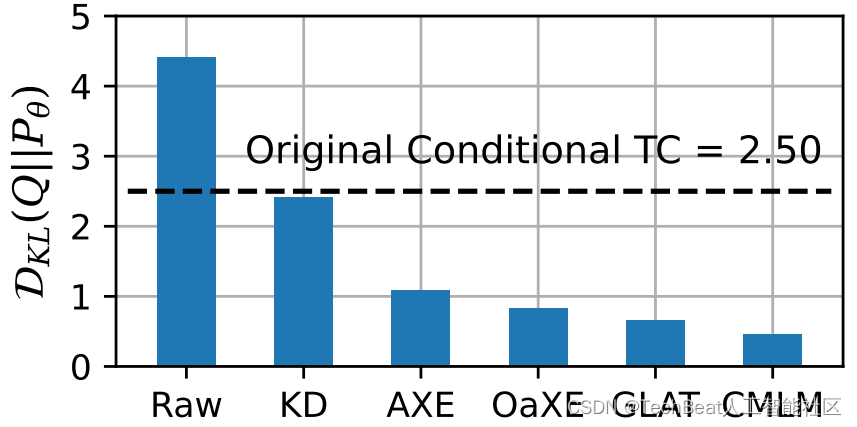
图6:各方法的信息损失与原数据集条件总相关 (Conditional TC) 的大小比较。
为了验证代理分布 Q Q Q 能够减少 NAT 模型学习时的信息损失,上图比较了各个方法的信息损失与原数据条件总相关的大小。可以发现,除了不修改数据集 (Raw) 外,其他优化方法均能有效的减少训练时丢失的信息,进而提升模型的生成性能。
除以上验证外,该工作还给出了更多的分析结果:
- 优化目标与质量的相关性。 与 MLE 不同,实验证明 MPLE 的目标函数与模型生成质量有较强的相关性 (Pearson相关系数 |r|>0.95)。
- 提高现有方法可解释性。 MPLE 解释了各方法中的超参选择,即很多已有方法引入的超参均在平衡 MPLE 中的两项损失:代理分布的条件总相关,以及距离真实数据数据的偏差。
- 指导新训练方法的设计。 基于 MPLE,该工作提出了知识蒸馏的变种,通过直接优化 MPLE 的训练目标,提高了生成质量 (+0.7 BLEU) 。
四、总结
该工作详细讨论了并行模型学习中存在的问题,并指出其主要挑战来自于数据集的条件总相关 (Conditional Total Correlation)。该工作进一步提出了统一视角 MPLE,来解释已有的模型训练方式,即构造代理分布来降低学习中的信息损失。实验表明,该视角能够很好地解释目前的各类现象,并能引导新训练方法的设计。
并行生成模型作为文本生成的新范式,近年来获得了越来越多的关注。本文介绍的工作揭示了其学习过程中的重要挑战,并将大量已有工作纳入了统一框架。并行生成的下一步应该走向哪里?希望本文能给大家带来一些思考。
参考文献
[1] Gu, J., Bradbury, J., Xiong, C., Li, V. O. K., and Socher, R. Non-autoregressive neural machine translation. ICLR 2018.
[2] Qian, L., Zhou, H., Bao, Y., Wang, M., Qiu, L., Zhang, W., Yu, Y., and Li, L. Glancing transformer for non-autoregressive neural machine translation. ACL 2021.
[3] Qian, L., Zhou, Y., Zheng, Z., Zhu, Y., Lin, Z., Feng, J., Cheng, S., Li, L., Wang, M., and Zhou, H. The volctrans GLAT system: Non-autoregressive translation meets WMT21.
[4] Huang, F., Zhou, H., Liu, Y., Li, H., and Huang, M. Directed acyclic transformer for non-autoregressive machine translation. ICML 2022.
[5] Watanabe, M. S. Information theoretical analysis of multivariate correlation. IBM J. Res. Dev., 4(1):66–82, 1960
-The End-
关于我“门”
▼
将门是一家以专注于发掘、加速及投资技术驱动型创业公司的新型创投机构,旗下涵盖将门创新服务、将门-TechBeat技术社区以及将门创投基金。
将门成立于2015年底,创始团队由微软创投在中国的创始团队原班人马构建而成,曾为微软优选和深度孵化了126家创新的技术型创业公司。
如果您是技术领域的初创企业,不仅想获得投资,还希望获得一系列持续性、有价值的投后服务,欢迎发送或者推荐项目给我“门”:
bp@thejiangmen.com














 832
832











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









