







背景
当前,ClickHouse 能快速的查询和分析自身写入到 S3 上的数据,但我们还期望 ClickHouse 能查询和分析 S3 上已存在的标准化格式的数据(非 ClickHouse 写入)。这不仅可以大大的提升我们对 Event-Collector 中间数据(通过 Flink Job 写入到 S3)的查询和分析效率,还能极大的缩短我们对 AWS CUR 数据(通过 AWS 服务投递到 S3)的分析链路,为 ClickHouse on S3 的使用带来更多可能性。ClickHouse 通过 S3 Table Engine 来提供对 S3 上数据查询和分析的功能,下面我们介绍该引擎的配置和基本使用。
配置
机器级别的 IAM Role
ClickHouse S3 Table Engine 允许我们通过 AWS IAM Role 的方式对 S3 进行访问。但是其内部采用的 AssumeRoleWithWebIdentity 的方式,导致我们无法直接使用服务级别的 IAM Role 的方式来为 ClickHouse 授权。
延伸阅读:ClickHouse Credentials Provider 源码
由于 ClickHouse 在提供极速查询体验的时候,在资源消耗方面也非常恐怖。所以我们在实际场景中不会将其和其他服务混部。故最终我们选择使用机器级别的 IAM Role 的方式来为 ClickHouse 对 S3 访问进行授权。其对应的配置如下:
<s3>
<shiyou-labs-aws-cur-test>
<endpoint>https://shiyou-labs-aws-cur-test.s3.ap-southeast-1.amazonaws.com/</endpoint>
<use_environment_credentials>true</use_environment_credentials>
</shiyou-labs-aws-cur-test>
</s3>权限
ClickHouse 想要访问 AWS S3 服务,就需要 S3 服务为提供 ClickHouse 服务的 EC2 所关联的 IAM Role(后面将该 IAM Role 称为 ClickHouse IAM Role) 授予访问权限。下面我们从同账号 S3 查询和跨账号 S3 查询 2 种情况来介绍授权过程:
-
同账号 S3 查询
当为 ClickHouse 提供服务的账号与需要访问的 S3 服务的账号相同,区域不限时,我们需要如下配置:
-
在 ClickHouse IAM Role 关联的策略中增加访问 S3 Bucket(
shiyou-labs-aws-cur-test) 的权限。
{
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::shiyou-labs-aws-cur-test"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject*"
],
"Resource": "arn:aws:s3:::shiyou-labs-aws-cur-test/*"
}
],
"Version": "2012-10-17"
}-
跨账号 S3 查询
当为 ClickHouse 提供服务的账号与需要访问的 S3 服务账号不同,区域不限时,我们需要做如下配置:
-
在 ClickHouse IAM Role 关联的策略中增加访问 S3 Bucket(
shiyou-labs-aws-cur-test) 的权限。
{
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::shiyou-labs-aws-cur-test"
]
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject*"
],
"Resource": "arn:aws:s3:::shiyou-labs-aws-cur-test/*"
}
],
"Version": "2012-10-17"
}-
在 S3 Bucket(假设 Bucket 名为
shiyou-labs-aws-cur-test) 的 policy 中增加允许 ClickHouse IAM Role 访问此 bucket 的权限
{
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Principal":{
"AWS":"arn:aws:iam::56589613640:role/x86_iam_role"
},
"Resource": [
"arn:aws:s3:::shiyou-labs-aws-cur-test"
]
},
{
"Effect": "Allow",
"Principal":{
"AWS":"arn:aws:iam::56589613640:role/x86_iam_role"
},
"Action": [
"s3:GetObject*"
],
"Resource": "arn:aws:s3:::shiyou-labs-aws-cur-test/*"
}
],
"Version": "2012-10-17"
}使用方式
建表
CREATE TABLE s3_engine_table (name String, value UInt32)
ENGINE = S3(path, format, [compression])
[SETTINGS ...]建表语句如下:
-- 创建 cur 外部表,并跳过第1列
CREATE TABLE default.ods_aws_cost_and_usage_reports(
identity_lineitemid String COMMENT '',
identity_timeinterval String COMMENT '',
bill_invoiceid String COMMENT ''
) engine = S3('https://shiyou-labs-aws-cur-test.s3.ap-southeast-1.amazonaws.com/*.csv.gz', 'CSV')
SETTINGS input_format_csv_skip_first_lines = 1; 参数描述如下:
-
path:【必填】该表对应的 S3 路径。在查询模式下,支持通配符。具体如下:-
*:匹配除/以外的任意数量的任何字符 -
?:匹配任何单个字符 -
{a,b,c}:匹配'a','b','c'中的任意一个字符串 -
{N..M}:匹配 从 N 到 M 范围内的任何数字,包括边界。N 和 M 前面可以有 0 。例如000..078
-
-
format:【必填】文件的格式。目前内置多种格式。不同的格式决定 Clickhouse 如何解析文件。比较常见的是 CSV 和 TabSeparated。
-
compression:【选填】文件的压缩类型。目前支持none,gzip/gz,brotli/br,xz/LZMA,zstd/zst。默认会根据文件的扩展名自动探测对应的压缩类型。
查询
-- 查询表中部分字段
SELECT
identity_lineitemid,
identity_timeinterval,
bill_invoiceid
FROM ods_aws_cost_and_usage_reports
LIMIT 2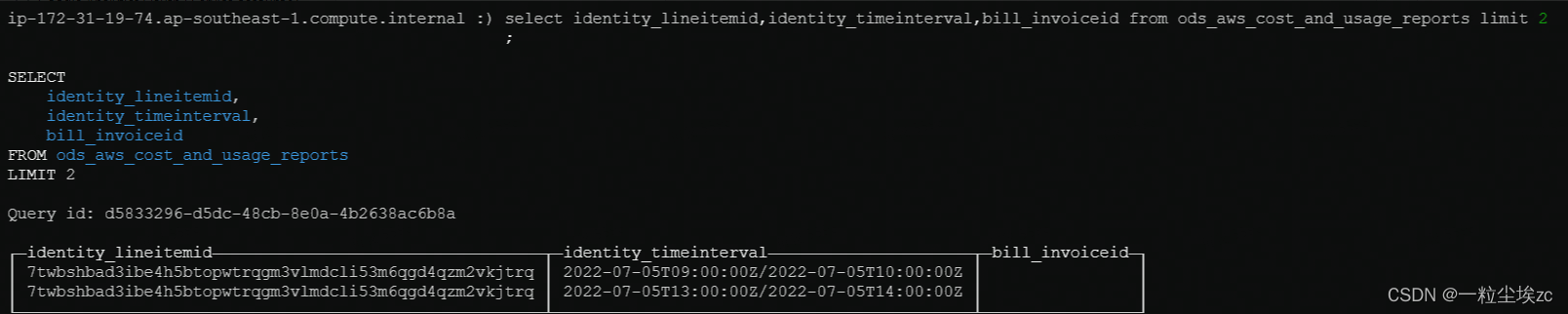
虚拟列
S3 Table Engine 除了提供对建表语句中的字段进行查询外,还额外提供如下 2 个虚拟列供我们查询和筛选。
-
_path:数据所属文件在 S3 上的路径
-
_file:数据所属文件的名称
示例如下:
-- 查询虚拟列
SELECT
_path,
_file,
identity_lineitemid,
identity_timeinterval,
bill_invoiceid
FROM ods_aws_cost_and_usage_reports
LIMIT 2Tips:
- 由于 S3 Table Engine 暂不支持直接创建分区表,导致我们在查询数据时没法直接使用过滤分区的方式来提高整个查询效率,但我们在查询时充分利用
_path和_file条件来快速过滤对应的文件,从而提高整个查询效率。 -
如果建表中的字段名和虚拟列名冲突,则虚拟列不可访问
-
select *类型的查询语句,不会返回虚拟列的内容 -
SHOW CREATE TABLE和DESCRIBE TABLE查询结果中不会返回虚拟列名 -
虚拟列是只读的
限制
-
不支持
ALTER和SELECT ... SAMPLE操作
-
不支持
Indexes
和 Superset 结合
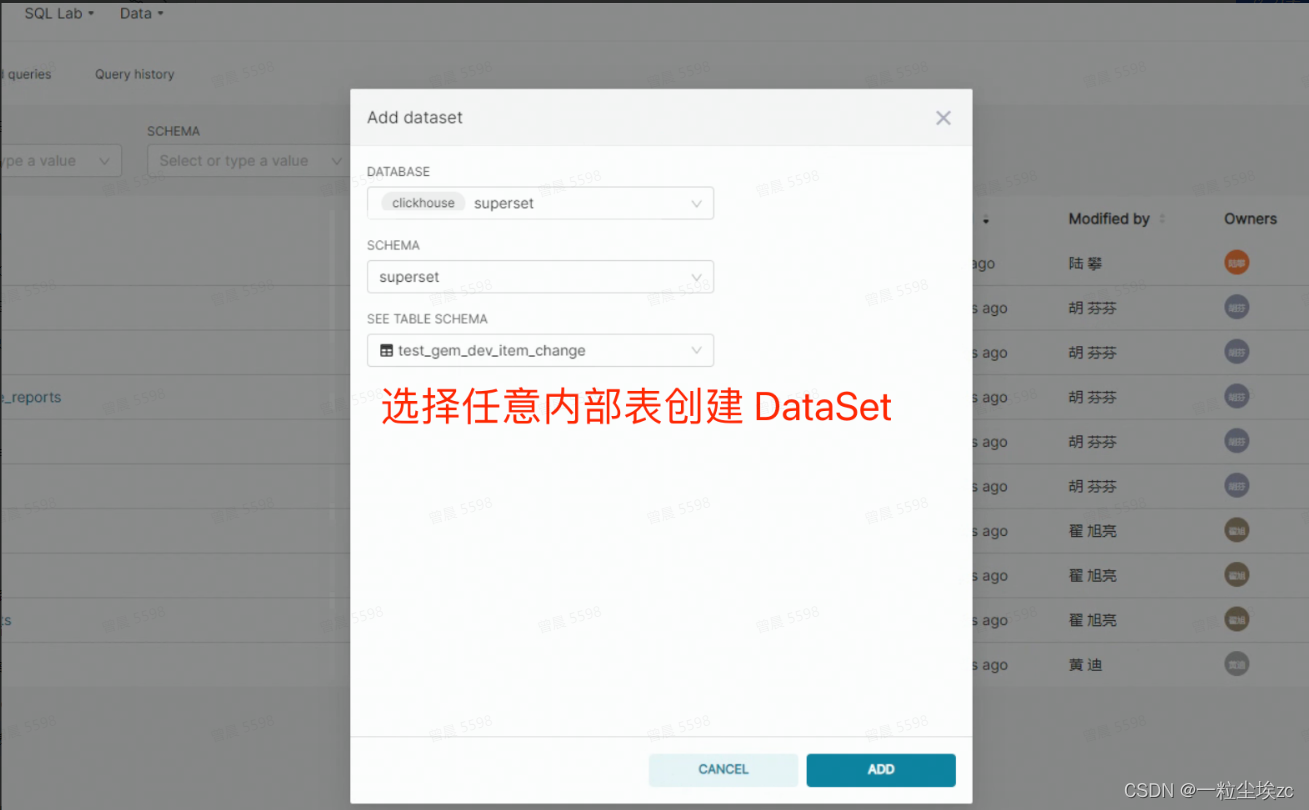
Superset 是非常优秀的开源的数据可视化工具,尽管暂不直接支持基于 S3 外表来创建 Dataset 进行数据可视化,但我们可以通过 Dataset 的 Virtual SQL 功能来解决。具体步骤如下:
- 使用任意内部表(非 S3 外表)创建 Dataset
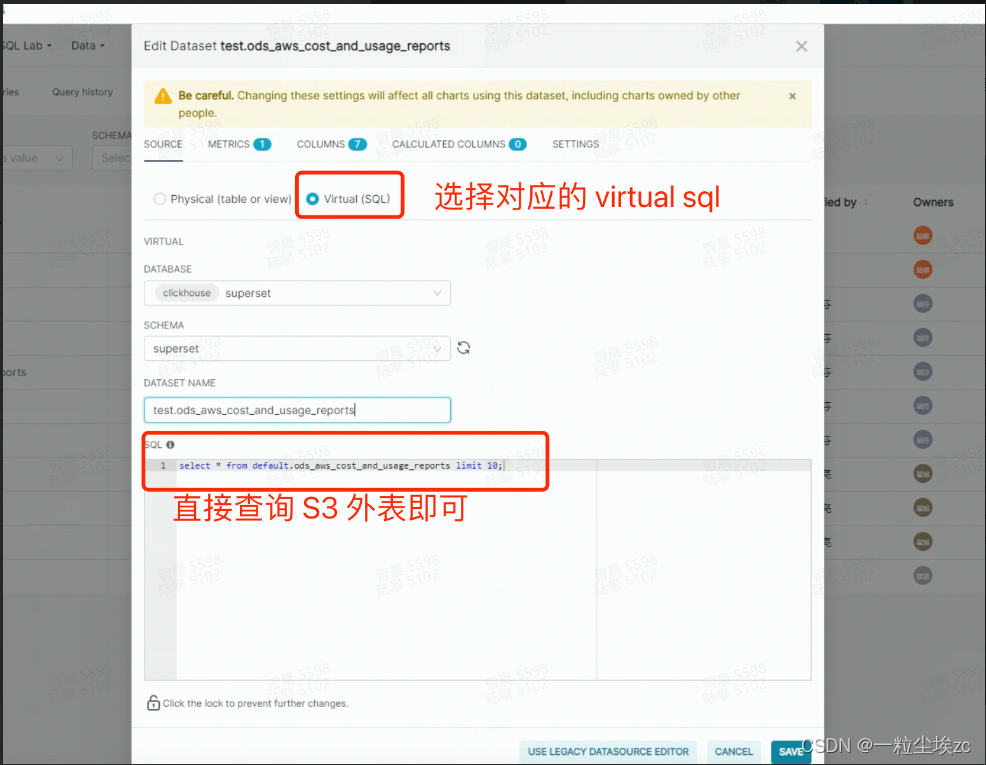
- 修改步骤 1 中创建的 DataSet 为 Virtual SQL,并输入 S3 外表查询即可创建具有查询 S3 外表的功能的 DataSet
-
基于 Dataset 创建对应的 Chart 即可















 437
437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









