1 哈夫曼树
- 哈夫曼编码,又称为霍夫曼编码,它是现代压缩算法的基础
- 假设要把字符串【ABBBCCCCCCCCDDDDDDEE】转成二进制编码进行传输,可以转成ASCII编码,但是有点冗长
- 可以先约定5个字母对应的二进制,从而使编码更短

- 注意新的编码,谁都不是谁的前缀,否则无法将二进制码解码成原字符串
- 对应的二进制编码:000001001001010010010010010010010010011011011011011011100100,一共20个字母,转成了60个二进制位
- 使用哈夫曼编码,可以压缩至41个二进制位,约为原来长度的68.3%
- 构建哈夫曼树
- 先计算出每个字母的出现频率(权值,这里直接用出现次数)

- 以权值作为根节点构建 n 棵二叉树,组成森林
- 在森林中选出 2 个根节点最小的树合并,作为一棵新树的左右子树,且新树的根节点为其左右子树根节点之和
- 从森林中删除刚才选取的 2 棵树,并将新树加入森林
- 重复 2、3 步骤,直到森林只剩一棵树为止,该树即为哈夫曼树
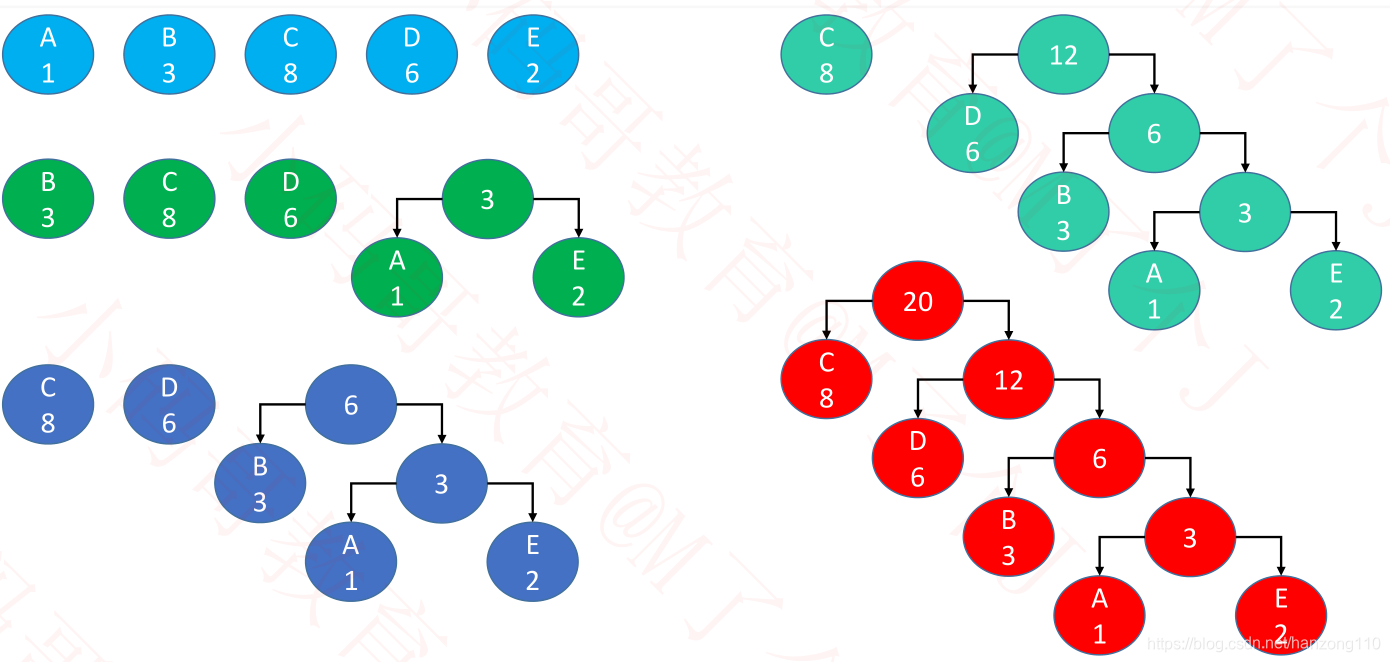
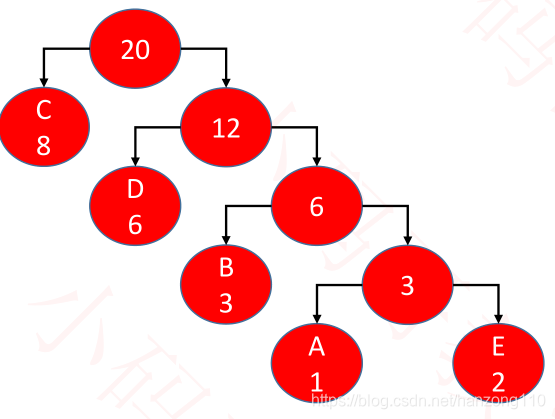
- left为0,right为1,可以得出5个字母对应的哈夫曼编码

- 因此ABBBCCCCCCCCDDDDDDEE的哈夫曼编码是1110110110110000000001010101010101111
- 总结
- n 个权值构建出来的哈夫曼树拥有 n 个叶子节点
- 5个字母对应的哈夫曼编码实际上就是叶子节点的路径二进制码表示,而每个叶子节点的路径都不可能是其它叶子节点的前缀,所以不会重复
- 哈夫曼树可以保证出现频率最高字母的编码最短,因此可以保证哈夫曼树是带权路径长度最短的树
- 带权路径长度:树中所有的叶子节点的权值乘上其到根节点的路径长度。与最终的哈夫曼编码总长度成正比关系
2 Trie
- Trie 也叫做字典树、前缀树(Prefix Tree)、单词查找树
- Trie 搜索字符串的效率主要跟待查找的字符串的长度有关
- 假设使用 Trie 存储 cat、dog、doggy、does、cast、add 六个单词
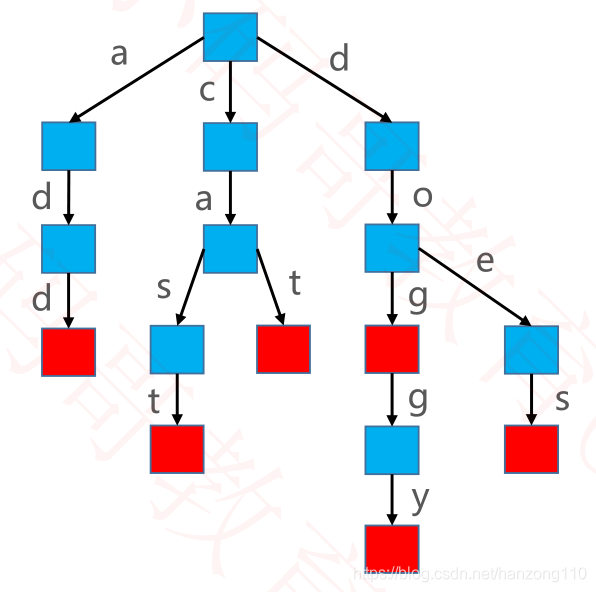
- Trie 的缺点:需要耗费大量的内存,因此还有待改进
- Trie
package com.mj;
import java.util.HashMap;
public class Trie<V> {
private int size;
private Node<V> root;
public int size() {
return size;
}
public boolean isEmpty() {
return size == 0;
}
public void clear() {
size = 0;
root = null;
}
public V get(String key) {
Node<V> node = node(key);
return node != null && node.word ? node.value : null;
}
public boolean contains(String key) {
Node<V> node = node(key);
return node != null && node.word;
}
public V add(String key, V value) {
keyCheck(key);
if (root == null) {
root = new Node<>(null);
}
Node<V> node = root;
int len = key.length();
for (int i = 0; i < len; i++) {
char c = key.charAt(i);
boolean emptyChildren = node.children == null;
Node<V> childNode = null;
if(emptyChildren) {
node.children = new HashMap<>();
}else {
childNode = node.children.get(c);
}
if (childNode == null) {
childNode = new Node<>(node);
childNode.character = c;
node.children.put(c, childNode);
}
node = childNode;
}
if (node.word) {
V oldValue = node.value;
node.value = value;
return oldValue;
}
node.word = true;
node.value = value;
size++;
return null;
}
public V remove(String key) {
Node<V> node = node(key);
if (node == null || !node.word) return null;
size--;
V oldValue = node.value;
if (node.children != null && !node.children.isEmpty()) {
node.word = false;
node.value = null;
return oldValue;
}
Node<V> parent = null;
while ((parent = node.parent) != null) {
parent.children.remove(node.character);
if (parent.word || !parent.children.isEmpty()) break;
node = parent;
}
return oldValue;
}
public boolean startsWith(String prefix) {
return node(prefix) != null;
}
private Node<V> node(String key) {
keyCheck(key);
Node<V> node = root;
int len = key.length();
for (int i = 0; i < len; i++) {
if (node == null || node.children == null || node.children.isEmpty()) return null;
char c = key.charAt(i);
node = node.children.get(c);
}
return node;
}
private void keyCheck(String key) {
if (key == null || key.length() == 0) {
throw new IllegalArgumentException("key must not be empty");
}
}
private static class Node<V> {
Node<V> parent;
HashMap<Character, Node<V>> children;
Character character;
V value;
boolean word;
public Node(Node<V> parent) {
this.parent = parent;
}
}
}
3 补充
3.1 四则运算
- 四则运算的表达式可以分为3种
- 前缀表达式(prefix expression),又称为波兰表达式
- 从最右面的运算符开始算起,每次都是将运算符的后两个数做运算
- 中缀表达式(infix expression)
- 后缀表达式(postfix expression),又称为逆波兰表达式

- 表达式树
- 如果将表达式的操作数作为叶子节点,运算符作为父节点(假设只是四则运算)
- 这些节点刚好可以组成一棵二叉树
- 比如表达式:A / B + C * D – E
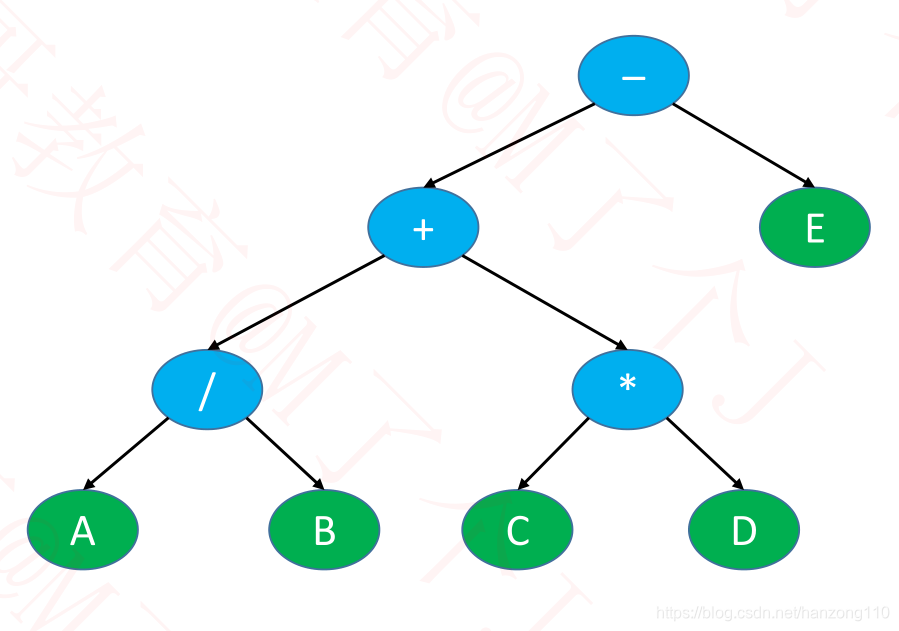
- 前序遍历
- – + / A B * C D E
- 刚好就是前缀表达式(波兰表达式)
- 中序遍历
- A / B + C * D – E
- 刚好就是中缀表达式
- 后序遍历
- A B / C D * + E –
- 刚好就是后缀表达式(逆波兰表达式)























 233
233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









