







目录
(本文章仅作为记录及总结)
快速排序基本原理
简单的说,快速排序(这里是升序)就是:
①确定一个枢纽元素pivot;
②将序列中所有的元素和枢纽元素pivot进行比较,比它大的放到右边,比它小的放到左边;
③对左右两个区间的元素,重新进行①②两个操作。
如图示例:

这里两个问题比较关键:如何选择枢纽元素?如何进行进行第②步?
枢纽元素选择不当,会导致排序效率低下,假如每次选择的枢纽元素是子序列中的最大值,那么在进行第②步操作时,会将所有元素都放到该元素的左边,该值右边为空,然后下次拆区间时,右边区间啥都没有,左边区间只排出了刚选择的枢纽值,时间复杂度退化成。建议随机选择或头尾中三值取中间值。
第②步中,有两种通常的方法来进行计算:挖坑填数法和指针交换法,这里分别进行了介绍,同时还介绍了一种非递归的方式的实现。
快速排序两种算法
- 挖坑填数
顾名思义,用一种先挖坑,再填数的方式,实现基于枢纽元素的左右拆分。
如图,这里以一个循环为例进行分解讲解:
a.初始状态如下,序列为value[]数组,我们选择枢纽pivot为序列头部元素,在这里挖个坑,同时将枢纽元素提前存储起来,坑的位置是可以用来交换其他元素使用的。(枢纽元素可以选择其他数值,可以通过交换到首部来保证算法的统一性)。i为头部,j为尾部。

b.先从右往左
如果value[j] < pivot,将该数值value[j]填坑到枢纽(此时为i)处,此时i位置被占用,i++右移,j处变为坑,然后跳出b步骤。如图:
如果value[j] > pivot,j左移j--,继续进行b步骤,直到j==i或value[j] < pivot。

c.从左往右
如果value[i] > pivot,将该数值value[i]填坑到上个坑(j)处,此时j被占用,j--,i处变为坑,跳出该步骤。否则i++,继续进行c步骤,直到i==j或value[i] > pivot。
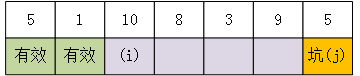
对于上图,i所在位置1<pivot(7),i++,变为:
此时value[i]为10,大于pivot(7),则j处设坑,将i赋值到j原始坑处,同时j--,变为:
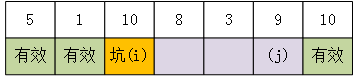
d.持续进行b和c两个步骤,最后的图为:
此时i不满足j<j,退出循环,本次序列调整完毕。
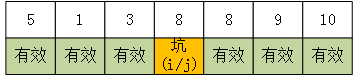
e.最后将pivot的原始值7赋值到j处:
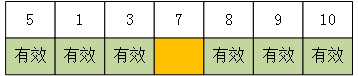
f.递归剩余的两个子序列(除了枢纽元素)
最终的代码(c语言描述):
void quick_sort1(int value[], int startIndex, int endIndex)
{
if (startIndex >= endIndex) {
//注意这里用的是>=而不是光==,因为本函数最后的递归函数参数起始位i+i输入,可能会超过endIndex
return;
}
int pivotValue = value[startIndex];//坑的原始值(枢纽元素),取第一个元素
int i = startIndex;//此时坑为i
int j = endIndex;
while (i < j) {
//从右往左
while (i < j) {
if (value[j] < pivotValue) {
value[i] = value[j];//原始坑填数,j自动变为新坑
i++;//i之前作为坑已经填上有效数值,右移i
break;//跳出--关键
}
j--;
}
//从左往右
while (i < j) {
if (value[i] > pivotValue) {
value[j] = value[i];//原始坑填数,i自动变为新坑
j--;
break;
}
i++;
}
}
assert(i == j);
value[i] = pivotValue;
//递归其他的
quick_sort1(value, startIndex, i-1);
quick_sort1(value, i+1, endIndex);
}- 指针交换
此方法和上面类似,只是没有【挖坑】的概念,只要满足一定条件后,交换两个指针(i和j)即可。
这里枢纽元素还是选择首部,交换的条件是从右往左找到<pivot,且从左往右找到>pivot。过程简单来说:
①确定枢纽元素
②从右往左,对j进行操作(j--),一直找到value[j] < pivot停止;
③从左往右,对i进行操作(i++),一直找到value[i] > pivot停止;
④交换i和j处的数值,继续②和③的搜索;
⑤最后j==j,交换枢纽元素和i的数值即可;
⑥递归左右子序列,从①开始。
具体代码如下:
void quick_sort2(int value[], int startIndex, int endIndex)
{
if (startIndex >= endIndex)
{
return;
}
//选左第一个元素为枢纽
int pivotValue = value[startIndex];
int i = startIndex;
int j = endIndex;
while (i < j) {
while (i < j) {
if (value[j] < pivotValue) {
break;
}
j--;
}
while (i < j) {
if (value[i] > pivotValue) {
break;
}
i++;
}
//交换i和j
std::swap(value[i], value[j]);
}
assert(i == j);
std::swap(value[startIndex], value[i]);
quick_sort1(value, startIndex, i-1);
quick_sort1(value, i+1, endIndex);
}非递归实现快速排序
这里基于挖坑法,自定义一个栈来存储递归时传递的参数,初始时把大的边界传入栈,然后开始循环栈,循环栈中的步骤和上面的一样,最后拆分子序列递归修改为压入栈两个参数。
代码如下:
typedef struct TStackValue
{
int start;//起始
int end;//终止
}TStackValue;
//非递归方式,采用挖坑填数法
void quick_sort1_norecursive(int value[], int startIndex, int endIndex)
{
std::stack<TStackValue> stackValue;
if (startIndex >= endIndex)
{
return;
}
TStackValue tValue = {startIndex, endIndex};
stackValue.push(tValue);
while (!stackValue.empty()){//退出条件--栈空
auto topValue = stackValue.top();//处理栈顶
if (topValue.start >= topValue.end)
{
stackValue.pop();//不满足条件,弹出该元素
continue;
}
//下面和挖坑法基本一样
int i = topValue.start;
int j = topValue.end;
int pivotValue = value[i];
while (i < j) {
while (i < j) {
if (value[j]<pivotValue) {
value[i] = value[j];
i++;
break;
}
j--;
}
while (i < j){
if (value[i]>pivotValue) {
value[j] = value[i];
j--;
break;
}
i++;
}
}
value[i] = pivotValue;
TStackValue tValue1 = {topValue.start, i-1};//创建两个栈元素来代替递归
TStackValue tValue2 = {i+1, topValue.end};
stackValue.pop();
stackValue.push(tValue1);
stackValue.push(tValue2);
}
}总结
理解了左右元素的交换原理,注意大于小于等于的边界,很容易就可以把代码写出来,一定要注意枢纽元素的选择。在实际应用中当元素个数少时,会有其他的算法来减少递归次数,实际的排序算法是多种方式的混搭。















 542
542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









