







1 引言
如果从人类最初的幻想开始算起,人工智能的历史非常久远,也许能与人类文明比肩。而现代化的人工智能历史是从1956年达特茅斯会议开始的。在这之后,人工智能的研究几经起落,符号主义、联结主义、专家系统等都曾经兴盛一时。如今,深度学习又代表人工智能走上了时代潮头,几乎渗透到了这个时代的每一个领域。

然而,不管是哪一种技术手段,到目前为止,人工智能终究不过是一种对人类智能的拙劣模仿。每一种学说和流派都只是站在某一个角度来看待、模仿人类某一方面的思维、语言和行动。
从某种程度上说,是深度学习让人工智能走出学术象牙塔和科幻作品,在二十一世纪的第二个十年火遍整个世界。然而令人遗憾的是,这种盛况的出现并不是因为人工智能理论的突破,而是因为人类社会整体科技和生活方式的发展。
正如很多人了解的那样,如今蓬勃发展的人工智能技术有三大支柱,分别是算法、算力和数据。准确地说,这三根支柱支撑起来的不是人工智能技术,而是深度学习技术。再进一步地说,真正促使人工智能在二十一世纪腾飞的,不是算法,而是算力和数据。
2 深度学习的基石
早在1957年,Rosenblatt就在Cornell航空实验室发明感知机——一种简单的人工神经网络。然而,单层感知机能解决的问题是十分有限的,为此,Minsky甚至专门写了一本叫《感知机》的书与Rosenblatt论战,并取得了完胜。感知机的发展也因此而停滞,直到六十多年后才出现了多层感知机——深度神经网络。Rosenblatt的那个年代也是一个神仙打架的时代,Minsky更不用多说,他是达特茅斯会议的发起人之一、图灵奖获得者,更有一个响亮的称号——“人工智能之父”。如果仅仅是将人工神经网络的层数加深就能解决问题,这些宗师级的人物会想不到吗?当时摆在Rosenblatt眼前的事实是,他不知道如何对多层感知机进行训练。这就像一座无法逾越的大山,让当时的人看不到感知机未来的希望,直到计算机硬件水平发展到了二十世纪末才让多层感知机有了出现的基础。
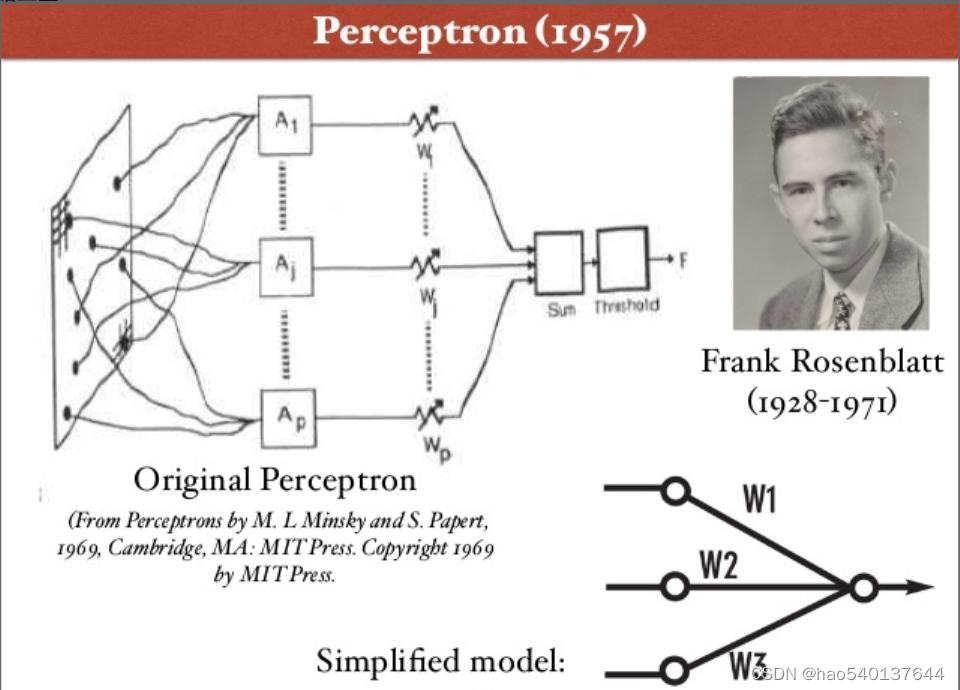
1986年,Rummelhart、McClelland和Hinton在多层感知器中使用BP算法,才解决了深度人工神经网络训练的问题。1990到1998年期间,Lecun等人陆续发表了关于第一个深度卷积神经网络LeNet的论文,LeNet也成功应用于手写体字符识别应用中,在MNIST数据集上实现了99.2%的准确率。以最典型的LeNet-5为例,LeNet-5网络一共由7层组成,分别是三个卷积层(C1、C3、C5),两个下采样层(S2、S4),一个全连接层(F6)和一个输出层(softmax)。LeNet基本具备了现代CNN网络的特点,其局部感受野、权值共享和下采样的核心思想至今依然影响着CNN网络的发展。然而,真正使深度神经网络声名鹊起的却
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2007
2007











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









