word2vec词向量学习笔记
原文地址:http://blog.csdn.net/hjimce/article/details/51564783
个人微博:黄锦池-hjimce
一、使用原版word2vec工具训练
1、英文编译测试
(1)到官网到下载:https://code.google.com/archive/p/word2vec/,然后选择export 到github,也可以直接到我的github克隆:
- git clone https://github.com/hjimce/word2vec.git
(2)编译:make
(3)下载测试数据http://mattmahoney.NET/dc/text8.zip,并解压
(4)输入命令train起来:
- time ./word2vec -train text8 -output vectors.bin -cbow 1 -size 200 -window 8 -negative 25 -hs 0 -sample 1e-4 -threads 20 -binary 1 -iter 15
(5)测试距离功能:
2、中文训练测试
(1)中文词向量:下载数据msr_training.utf8,这个数据已经做好分词工作,如果想要直接使用自己的数据,就需要先做好分词工作
(2)输入命令train起来:
- time ./word2vec -train msr_training.utf8 -output vectors.bin -cbow 1 -size 200 -window 8 -negative 25 -hs 0 -sample 1e-4 -threads 20 -binary 1 -iter 15
(3)启动相似度距离测试:
(4)输入相关中文词:中国,查看结果:
- hjimce@hjimcepc:~/workspace/word2vec$ ./distance vectors.bin
- Enter word or sentence (EXIT to break): 中国
-
- Word: 中国 Position in vocabulary: 35
-
- Word Cosine distance
- ------------------------------------------------------------------------
- 中国人民 0.502711
- 美国 0.480650
- 中国政府 0.463177
- 我国 0.447327
- 亚太地区 0.444878
- 加勒比 0.418471
- 两国 0.408678
- 各国 0.392190
- 独立自主 0.391517
- 世界 0.387604
- 国际 0.382578
- 中美 0.382208
- 欧美 0.379807
- 古巴 0.378412
二、算法学习阶段
因为这个算法是半年前所学的算法,最近只是简单复习一下,所以不打算写详细的算法流程笔记,原理等也不打算啰嗦。word2vec网络结构可以分成两种:CBOW、Skip-Gram,其实网络结构都非常简单,不过是一个三层神经网络罢了。本文只讲解CBOW网络结构算法、算法流程。
CBOW又有两种方案,一种叫层次softmax,另一种叫:negative sample。这两种方法如果看不懂也没关系,你完全可以用原始的softmax替代网络的最后一层,进行训练,只是训练速度比较慢。
1、CBOW+层次softmax算法总体流程
先讲解层次softmax的算法实现过程:
(1)根据训练语料库,创建词典,并对词典每个单词进行二叉树霍夫曼编码。
如下图所示,比如经过编码后,可能汉语词典中的“自”就被编码成了:110,“我”对应的编码就是:001。这个算法与word2vec的实现过程关系不大,具体霍夫曼编码过程代码怎么写,不懂也没关系。我们只需要记住,字典中的每个单词都会被编码,每个单词对应二叉树的叶节点,每个单词的编码结果对应于:从跟节点到达当前单词,所经过的节点路径。编码中的1、0表示右节点、左节点。
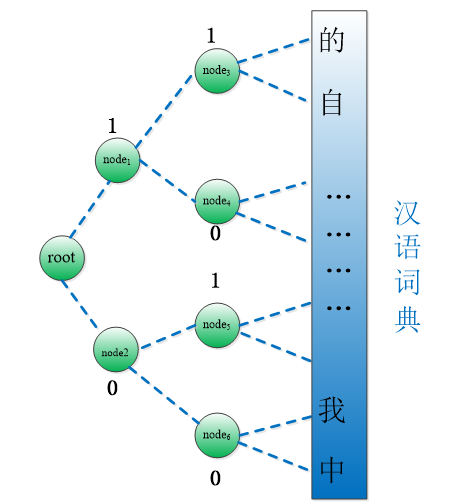
这边需要知道的是每一位编码的用处,因为每位的编码节点刚好可以对应到0、1输出标签,而且这颗二叉树节点就是神经网络的输出层神经元,具体可以看下面的图。假如在训练的时候,最后一层训练数据的输出是“自”,那么其实我们只需要训练节点root、node1、node3使得这三个节点的激活值分别为:1、1、0,这样就可以了。
因此对于层次softmax来说,神经网络的隐藏层其实是连接到二叉树的每个非叶子节点上(如果是原始的sotfmax,是直接连接到叶子节点上),然后对这些非叶子节点,根据输出单词的编码路径,对路径上的每个节点,根据对应的编码进行训练。
(2)根据定义窗口大小,截取出一个窗口内的单词作为一个样本,进行训练
这一步在word2vec里面,其实我们给出的参数值是一个max window size,然后word2vec底层生成一个随机大小的窗口,只要满足其范围在max window size 即可,这个可能是为了数据扩充吧。
(3)输入层-》隐藏层:对窗口内的左右单词(不包含自己)对应的词向量,进行累加,并求取平均向量Vavg。
(4)隐藏层-》非叶子节点:每个二叉树非叶子节点,链接到Vavg都有一个可学习的参数W,然后通过sigmoid可以得到每个非叶子节点的激活值(也表示概率值):
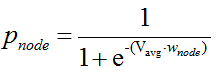
也就是说网络的参数除了词向量之外,还有隐藏层链接到二叉树结点的参数向量(从word2vec代码上看,我没有看到偏置参数b)。
(5)反向求导:根据输出文字的节点路径,更新路径上的每个非叶子节点链接到隐藏层的参数值w;并更新窗口内各个单词的词向量。
具体网络结构图如下所示:
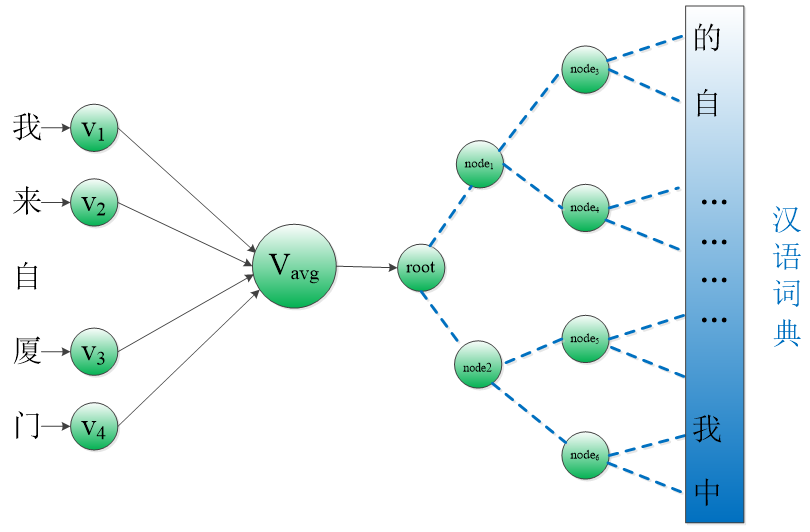
采用层次softmax的优点在于加快训练速度,参数个数、预测速度没啥差别。
2、CBOW+Negative Sample
这个比较简单,所谓的Negative Sample,就是除了正样本标签之外,还需要随机抽取出词典中的其它单词作为负样本(以前是把整个词典的其它单词都当成负样本),这个还是具体看源码实现吧。
三、源码阅读阶段
- word = sen[sentence_position];
- if (word == -1) continue;
- for (c = 0; c < layer1_size; c++) neu1[c] = 0;
- for (c = 0; c < layer1_size; c++) neu1e[c] = 0;
- next_random = next_random * (unsigned long long)25214903917 + 11;
- b = next_random % window;
-
-
- if (cbow) {
- cw = 0;
-
- for (a = b; a < window * 2 + 1 - b; a++)
- if (a != window)
- {
- c = sentence_position - window + a;
- if (c < 0) continue;
- if (c >= sentence_length) continue;
- last_word = sen[c];
- if (last_word == -1) continue;
- for (c = 0; c < layer1_size; c++)
- {
- neu1[c] += syn0[c + last_word * layer1_size];
- }
-
- cw++;
- }
-
- if (cw)
- {
-
- for (c = 0; c < layer1_size; c++)
- {
- neu1[c] /= cw;
- }
-
- if (hs)
-
- for (d = 0; d < vocab[word].codelen; d++)
- {
-
-
- f = 0;
- l2 = vocab[word].point[d] * layer1_size;
- for (c = 0; c < layer1_size; c++) f += neu1[c] * syn1[c + l2];
-
-
- if (f <= -MAX_EXP) continue;
- else if (f >= MAX_EXP) continue;
- else f = expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))];
-
-
- g = (1 - vocab[word].code[d] - f) * alpha;
-
- for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1[c + l2];
-
- for (c = 0; c < layer1_size; c++) syn1[c + l2] += g * neu1[c];
- }
-
- if (negative > 0)
- for (d = 0; d < negative + 1; d++)
- {
-
- if (d == 0)
- {
- target = word;
- label = 1;
- }
-
- else
- {
- next_random = next_random * (unsigned long long)25214903917 + 11;
- target = table[(next_random >> 16) % table_size];
- if (target == 0) target = next_random % (vocab_size - 1) + 1;
- if (target == word) continue;
- label = 0;
- }
- l2 = target * layer1_size;
- f = 0;
- for (c = 0; c < layer1_size; c++) f += neu1[c] * syn1neg[c + l2];
-
-
- if (f > MAX_EXP) g = (label - 1) * alpha;
- else if (f < -MAX_EXP) g = (label - 0) * alpha;
- else g = (label - expTable[(int)((f + MAX_EXP) * (EXP_TABLE_SIZE / MAX_EXP / 2))]) * alpha;
- for (c = 0; c < layer1_size; c++) neu1e[c] += g * syn1neg[c + l2];
- for (c = 0; c < layer1_size; c++) syn1neg[c + l2] += g * neu1[c];
- }
-
- for (a = b; a < window * 2 + 1 - b; a++) if (a != window)
- {
- c = sentence_position - window + a;
- if (c < 0) continue;
- if (c >= sentence_length) continue;
- last_word = sen[c];
- if (last_word == -1) continue;
- for (c = 0; c < layer1_size; c++) syn0[c + last_word * layer1_size] += neu1e[c];
- }
- }
- }
参考文献:
1、《Efficient Estimation of Word Representations in Vector Space》
2、《word2vec Explained: Deriving Mikolov et al.'s Negative-Sampling Word-Embedding Method》
3、https://code.google.com/archive/p/word2vec/























 299
299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









