







本文实例讲述了Python利用Scrapy框架爬取豆瓣电影。分享给大家供大家参考,具体如下:
1、概念
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
通过Python包管理工具可以很便捷地对scrapy进行安装,如果在安装中报错提示缺少依赖的包,那就通过pip安装所缺的包
pip install scrapy
scrapy的组成结构如下图所示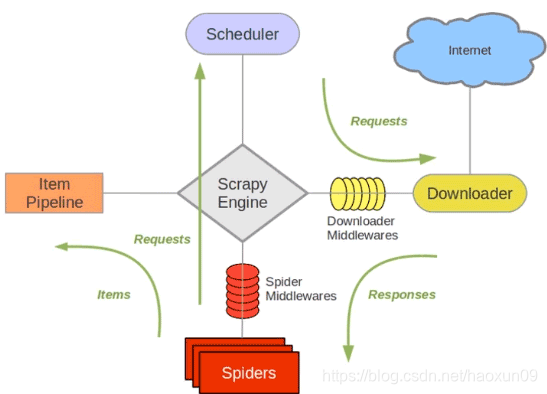
引擎Scrapy Engine,用于中转调度其他部分的信号和数据传递
调度器Scheduler,一个存储Request的队列,引擎将请求的连接发送给Scheduler,它将请求进行排队,但引擎需要时再将队列中的第一个请求发送给引擎
下载器Downloader,引擎将请求Request链接发送给Downloader之后它就从互联网上下载相应的数据,并将返回的数据Responses交给引擎
爬虫Spiders,引擎将下载的Responses数据交给Spiders进行解析,提取我们需要的网页信息。如果在解析中发现有新的所需要的url连接,Spiders会将链接交给引擎存入调度器
管道Item Pipline,爬虫会将页面中的数据通过引擎交给管道做进一步处理,进行过滤、存储等操作
下载中间件Downloader Middlewares,自定义扩展组件,用于在请求页面时封装代理、http请求头等操作
爬虫中间件Spider Middlewares,用于对进入Spiders的Responses和出去的Requests等数据作一些修改
scrapy的工作流程:首先我们将入口url交给spider爬虫,爬虫通过引擎将url放入调度器,经调度器排队之后返回第一个请求Request,引擎再将请求转交给下载器进行下载,下载好的数据交给爬虫进行爬取,爬取的数据一部分是我们需要的数据交给管道进行数据清洗和存储,还有一部分是新的url连接会再次交给调度器,之后再循环进行数据爬取
2、新建Scrapy项目
首先在存放项目的文件夹内打开命令行,在命令行下输入scrapy startproject 项目名称,就会在当前文件夹自动创建项目所需的python文件,例如创建一个爬取豆瓣电影的项目douban,其目录结构如下:
Db_Project/
scrapy.cfg --项目的配置文件
douban/ --该项目的python模块目录,在其中编写python代码
__init__.py --python包的初始化文件
items.py --用于定义item数据结构
pipelines.py --项目中的pipelines文件
settings.py --定义项目的全局设置,例如下载延迟、并发量
spiders/ --存放爬虫代码的包目录
__init__.py
...
之后进入spiders目录下输入scrapy gens
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 792
792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









