







转:https://zhaokv.com/machine_learning/2016/01/learning-from-imbalanced-data.html
这几年来,机器学习和数据挖掘非常火热,它们逐渐为世界带来实际价值。与此同时,越来越多的机器学习算法从学术界走向工业界,而在这个过程中会有很多困难。数据不平衡问题虽然不是最难的,但绝对是最重要的问题之一。
一、数据不平衡
在学术研究与教学中,很多算法都有一个基本假设,那就是数据分布是均匀的。当我们把这些算法直接应用于实际数据时,大多数情况下都无法取得理想的结果。因为实际数据往往分布得很不均匀,都会存在“长尾现象”,也就是所谓的“二八原理”。下图是新浪微博交互分布情况:
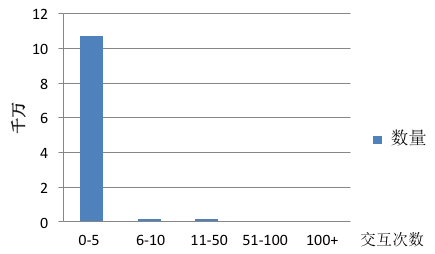
可以看到大部分微博的总互动数(被转发、评论与点赞数量)在0-5之间,交互数多的微博(多于100)非常之少。如果我们去预测一条微博交互数所在档位,预测器只需要把所有微博预测为第一档(0-5)就能获得非常高的准确率,而这样的预测器没有任何价值。那如何来解决机器学习中数据不平衡问题呢?这便是这篇文章要讨论的主要内容。
严格地讲,任何数据集上都有数据不平衡现象,这往往由问题本身决定的,但我们只关注那些分布差别比较悬殊的&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1185
1185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









