










一、运维工作中的事件
https://www.51cto.com/article/687753.html
二、运维故障排查
一)故障排查步骤
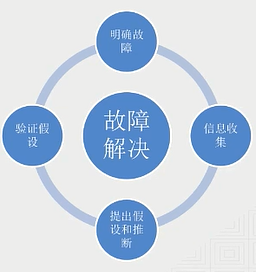
1、明确故障
- 故障现象的直接表现
- 故障发生的时间、频率
- 故障发生影响哪些系统
- 故障发生是否有明确的触发条件
故障举例:无法通过ssh登录系统
影响因素
- ssh(用户态应用)登录不到服务器用户态也会报一些信息
- 网络软件和硬件
- 操作系统:CPU、内存、磁盘IO等
2、信息收集
- 故障发生前后所有与之直接相关的信息,包括但不限于配置、日志、屏显
- 故障发生前后与之间相关的子模块的信息
- 尽量区分信息的重要程度,以免信息过载造成对故障产生负面作用
重要日志项
- /var/log/messages ---- 多数的系统日志和内核日志
- /var/log/secure ---- 安全相关日志,如sshd,login,pam
- /var/log/dmesg ---- 内核日志
- /var/log/boot.log ---- 启动屏显
- /var/log/cron ---- 计划任务日志
- /var/log/btmp ---- last 日志
- /var/log/sa/ ---- sar 历史性能能日志
- 应用层日志
红帽操作系统特有的
#安装sos软件包 yum install sos #运行sosreport --batch #全面的系统信息tar包位置 rhel6:/tmp/sosreport-* rhel7:/var/tmp/sosreport-*
3、提出假设和推断
- 基于对系统的深刻理解,对信息的综合分析,结合症状提出合理的、具体的假设
- 分解排除
- 分层模型,自下而上
- 模快化
- 发散思维
- 对比
4、验证假设
- 一次验证只考虑一种故障因素的组合
- 记录验证结果,可能产生新的线索
- 反复验证所有可能的因素组合
二)故障解决
- 故障归档:
- 故障现象
- 故障环境
- 根本原因
- 解决办法等
- 改进方法:避免再发生
三)故障排查需要的能力
- 对系统和架构的深入理解
- 善用工具
- 严密的逻辑思维
- 对信息的筛选
- 发散思维
- 运气
四)寻求帮助
1、以RedHat操作系统为例
- Red Hat Customer Portal - Access to 24x7 support and knowledge 受限
- 800远程支持:电话交流或提交case,附带sosreport
- GPS红帽服务和咨询团队
- Google查询解决办法(有辨别度)
man命令介绍
# 安装man包
yum install man-pages
# man man
# man -k <关键字>
# man文档类型
1 Executable programs or shell commands 可执行工具的使用文档
2 System calls (functions provided by the kernel) 系统调用接口文档
3 Library calls (functions within program libraries) libc接口文档
4 Special files (usually found in /dev) 特殊文件说明文档
5 File formats and conventions, e.g. /etc/passwd 配置文件格式说明
6 Games
7 Miscellaneous (including macro packages and conventions), e.g. man(7), groff(7)
8 System administration commands (usually only for root)
9 Kernel routines [Non standard]
五)举例一:硬件故障排查
1、硬件故障现象举例
- 磁盘掉盘或者大量IO error
- 网卡灯不亮,或网卡丢包严重影响到应用层面
- 硬件日志报警
2、识别硬件
读取bios信息
dmidecode
识别CPU
lscpu
/proc/cpuinfo
识别内存
dmidecode -t memory
free
/proc/meminfo
识别pci设备
lspci
识别scsi设备
lsscsi
识别block设备
lsblk
3、驱动程序
列出所有加载模块
lsmod
查看模块信息
modinfo
模块加载/卸载
modprobe
模块日志
dmesg
4、排查手段
- 排查硬件日志,硬件状态,检查bios信息
- RAS(reliablity(可靠性)、availability(可用性)、serviceability(安全性))特性
- 需要硬件厂商支持,硬件和驱动
- rasdaemon(rhel7/8)
- 日志输出到/var/log/messages
- 检查/var/log/messages和dmesg
- 检查驱动
- 硬件厂商提供的驱动
- 操作系统kernel中提供的驱动
5、常见硬件故障的日志形态
- HBA卡链路故障
- 日志样例如图:

- 日志样例如图:
- 磁盘IO故障
- 日志样例如图:
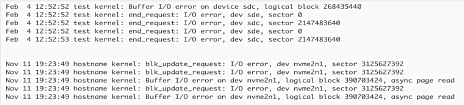
- 日志样例如图:
- MCE故障
- 日志样例如图:
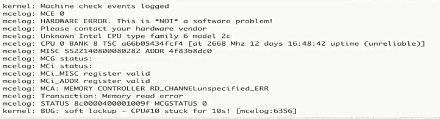
- 日志样例如图:
六)举例二:启动故障排查
1、启动故障举例(清楚系统启动的细节(顺序))
- 找不到启动盘
- 在grub菜单过后 kernel panic
- 文件系统挂载失败
- 服务启动阶段长时间卡住
2、启动流程
- BIOS POST开机自检
- BIOS扫描启动盘(直通、阵列卡、网卡、光纤卡、CD)
- 感知到MBR( 主引导记录(MBR,Master Boot Record)),以及bootable分区
- stage 1(MBR) > stage 1.5(boot文件系统驱动) > stage 2 (grub boot loader启动读取grub.conf)
- 载入vmlinuz和initramfs
- 载入硬件驱动,初始化磁盘,lvm和根文件系统
- sysV/systemd启动管理器开始运行,挂载文件系统,初始化网络,继续进行服务启动
3、排查手段
- 单用户模式
- 适合排查初始引导过后的sytemd启动阶段故障
- 救援模式
- 适合排查引导盘存储故障
- rd.break模式
- 适合排查初始化引导阶段故障
- 云环境,将主机的系统盘挂载到其他云主机上,修改文件内容
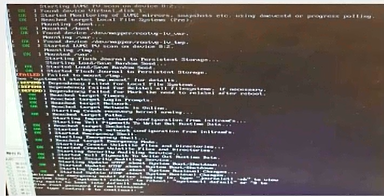
4、常见的启动故障的日志形态
- 根盘LVM故障
-
- boot image故障
-
- fstab故障
-

七)举例三:文件系统故障
1、文件系统故障
- 文件系统满
- 文件系统只读
- 文件系统空间未释放
- lsof | grep -i deleted
- 若是误删的情况,可以通过cp /proc/$pid/fd/删除内容到指定目录下
- 文件系统脏
2、关于空间未释放问题
- 文件的open与close
- df vs du
- 释放空间的小技巧
- echo > /path/to/file
- true > /path/to/file
- 误删文件后恢复的小技巧
- 文件仍被open状态,文件会保存到/proc/$pid/fd
3、常见文件系统故障的日志形态
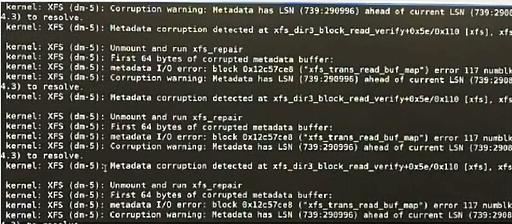
xfs元数据故障
八)举例四:网络性能分析
1、网络性能分析项
- 主机侧
- 网络配置查看
- 监控
- 网络链路
- 包转发时延
- 吞吐量
- 带宽
- 等指标
2、性能分析工具
-
ping:测试网络连通性
-
ifconfig:接口配置
-
ip:网络接口统计信息
-
netsat:多种网络栈和接口统计信息
-
ifstat:接口网络流量监控工具
-
netcat (nc):快速构建网络连接
-
tcpdump:抓包工具
- Wireshark:网络封包分析工具
-
sar:统计信息历史
-
traceroute:测试网络路由
-
pathchar:确定网络路径特征
- trace:跟踪进程执行时的系统调用和所接收的信号 linux trace命令详解-CSDN博客
-
dtrace:TCP/IP 栈跟踪
-
iperf / netperf / netserver:网络性能测试工具
-
perf 性能分析神器
详见:Linux中如何进行网络性能分析 - 系统运维 - 亿速云
九)举例五:应用debug的方法
1、shell
bash -x 断点
2、python
pdb
3、Java
Jvm heap dump Thread dump
4、C/C++
操作系统的核心
gdb
十)举例六:操作系统崩溃分析
1、kexec vs kdump
- kexec是一种热启动机制,能够跳过耗时较长的BIOS启动阶段,直接启动新的内核,这个新的内核叫capture kernel
- kdump是利用了kexec的特性,通过在内存预留区域放置了capture kernel的image,在特定条件下触发启动capture kerne,并把crash的诶村镜像抽取保存
- 不是所有的crash都触发kdump,需要在内核执行路径上执行panic()
2、kdump配置
- grub.cfg中指明内存预留空间
- “crashkernel=xxM”:让crashkernel运行起来(机器越大,硬件(外设)越多,使用的内存越多,建议值256/512M)
- “crashkernel=auto”:虚拟机设置设置此值没问题
- 指定dump文件的存放位置,默认在/var/crash,支持nfs,ssh或外部存储
- dump文件并非把整个内存都收集,而是必须必要数据,剔除多余数据,并运行适当压缩
3、kdump测试
利用kernel的sysrq特性产生kernel dump
- 配置:sysctl.conf 中 kernel.sysrq=1
- 测试方法:
- echo c > /proc/sysrq-trigger #机器立即宕机(c是crash)
-
- 键盘可操作:Alt+prtsc+c
- 硬件bmc触发dump(硬件厂商:硬件安装bmc的驱动程序)
4、kdump触发事件
什么情况下会触发kdump?
sysctl -a|grep panic
- oom:内存溢出,将机器干掉
- Hung process:进程120s hang住
- Nmi:硬件不可信(不可屏蔽故障)
- Soft lookup:死锁的环境
- other oops


















 1843
1843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









