






滴滴出行工程生产力团队技术总监齐贺详细讲解滴滴如何用数据来驱动产品决策,以及如何规避实验过程中七大技术坑。
去年的一天,滴滴出行CEO程维在内部产品体验群里抛出了一张滴滴叫车页面的手机截图,并提出了一个问题:为什么我看到的车的数量少了?为什么只有5辆?昨天我看到的好像要比这个数量多很多。
由此引发了一个产品决策的探讨,页面上到底应该显示5辆车还是10辆车?哪一种是最适合呈现给用户的产品体验?后来滴滴有了自己的答案。
不同的决策场景,如何系统解决?
实际上,这个故事引申出了日常研发中经常出现的几个决策场景,例如:最近训练出几个模型,该如何选择?如何证明机器学习模型优于目前人工设置的模型?几个新设计的产品方案,该如何选择?
对上述问题,解决方法是:功能的定向投放、灰度发布和AB测试,业务系统需要具备支持这三种实践的能力,才能满足越来越多决策场景的需要。
定向发布,针对所有用户,能够按照一定的规则,把符合规则的人群筛选出来,然后把一个功能投放给这个特定人群。就类似于一个漏斗的方式,让符合这种规则的用户漏下来,让不符合的人留下,进而投放功能,这个叫做定向投放。
灰度发布。我把规则放的更大一些,添加了一线城市用户,这又会带来一个很大量的用户,目标群体也会被扩充。相对于刚才提到的定向,人群在逐步的扩大,当我把规则完全去掉,意味着所有的人群都会放进来,这个时候就就是全流量发布,灰度发布是一个从小到大、一级一级的发布出去这样一个过程。
AB测试。可能我有几种方案举棋不定,会首先找到一个目标人群,然后按一定比例分配,之后我们针对不同的组调节其中的单一变量,比如说某一个颜色、大小、圆角、直角位置等等。这个变量的调节作用在一个产品里,它会对用户的行为产生不一样的影响,而这个不一样的影响又会通过用户的行为、数据来形成对应的一些关键指标的区别,比如说转化率、日活、留存等等这些非常常见的目标。通过对不同组的相同指标对比,我们可以推断出某一个方案可能优于另外一个方案,然后再借助灰度发布的手段逐步转全,逐步生效。”
产品上如何实现?
产品线同学提出的一系列问题,可以由上述三个方法来解决。当然,它可能是三个方法的叠加、组合而成。拔高一点,就是经常提及的数据驱动方法。
而针对这套系统的方法,从产品上如何来实现?
首先是把部署和发布分离。我们把部署和发布进行分离,部署在这个时候只意味着你开发完的包被打出来,被部署到线上去,具备服务能力,但是它并不一定真正给用户提供服务,或者叫抵达到用户手里,而发布真正在做这样一个环节的事情,如果有平台能够提供这方面的管理,我们就可以非常灵活的来控制这种发布的行为了。
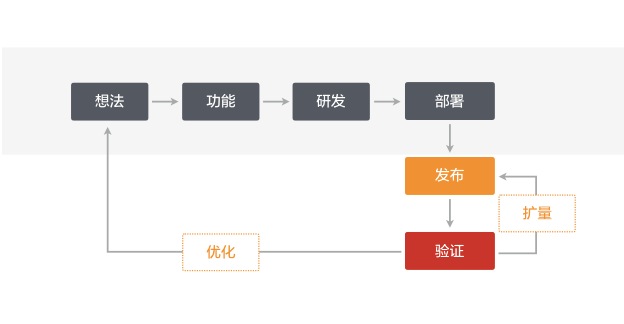
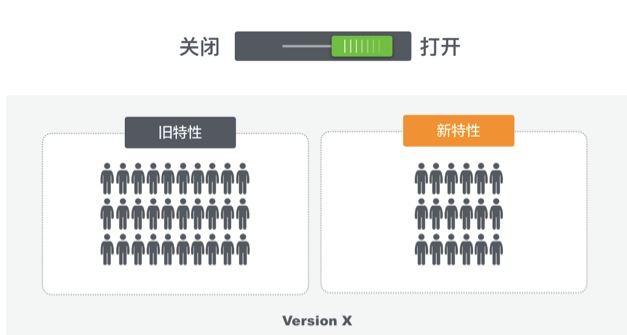
而实现这种分离的途径就是软件开关,一个版本中提供新旧两种特性,通过服务端规则匹配确定抵达用户的特性是哪一个,这样的方式可以支持灵活的规则设置,快速的发布效率,以及很高的扩展性。
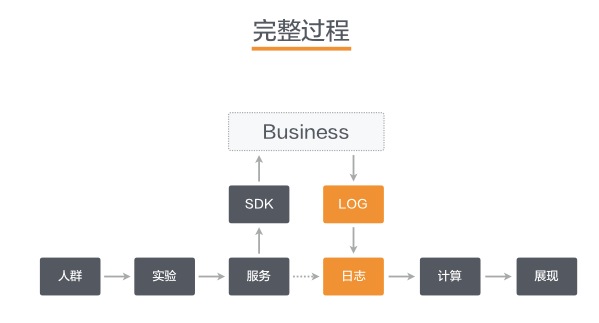
其次是提供各种SDK支持各种场景。我们内部在使用很多编程语言,包括手机端、服务端、策略端等,不同的业务场景可以使用不同语言的SDK来加载灰度或实验匹配后的结果,从而形成一个实验分群或者是一个灰度发布。

到底显示5辆车还是10辆车?
介绍完整套系统,回到最初的车标实验,到底应该在用户的页面上显示5辆车还是10辆车?
基于刚才提到的这套整个的系统,我们进行了车标实验。首先,我们这个实验设计在广州、深圳来做,然后我们为实验设置了三个组,当这个车的数量大于10辆的时候,我们为不同的三组用户展现三种不同的方式,第一种方式是展示5辆,第二种方式是10辆,第三种是有多少展示多少。
我们使用的指标选择的是专车快车比较核心的十几个业务指标,实验运行了大概两周多的时间,最后在几个关键指标上,我们发现10组的效果其实要明显优于5组和全量,当然,有可能9组也不错,这就需要接下来不断的去调节这个参数,设定实验找到那个最好的数字,依据这个实验,我们现在用的版本就是用10辆车标来做展现。
如何躲避七大技术坑?
对于技术人员而言,哪些技术坑要躲避是特别宝贵的经验。滴滴实验实现时常遇到的七大技术坑,如果你要做实验,要特别注意这几个技术环节,叫坑也可以,尽量避免掉到坑里。
实验碰撞。以前很早时候,我们最简单是拿手机号的奇数和偶数,聪明点的会拿手机号的倒数第二位的奇数和偶数去做,那么一个实验没有问题,两个实验、三个实验以及更多实验的时候,问题就会产生。我们内部叫做实验碰撞,对于手机号基数的用户来讲,如果有三个实验,那么他会匹配到A1、B1和C1,它最终作用的结果是A1加B1,加C1,写另外一个偶数的组看到的A2、B2和C2,这会有一个什么问题呢,我做A实验的一个PM,可能他看到的结果是A1、B1、C1是大于A2、B2、C2的,这个时候如果他下了一个A1大于A2的结论,这个时候就会错了。而且,是数据帮他证明这个结论,这其实是很可怕的一件事。
分桶策略。第一要保证幂等性,保证相同用户进入相同的分组;第二是保证均匀化,如果总是那么一波人被灰度或者是做实验,所有的东西都是在手机尾号低位的,比如1到5这几个人来做,实验或灰度的结果会受到影响,而另外一部分可实验的资源也会被浪费;第三,能够支持更多的实验;第四,支持实验互斥。
怎么实现扩量?扩量是做AB实验时常遇到的场景,比如我有一个模型,我要做这么一个实验,A组、B组,A组20%,B组20%,那对应的控制组是60%,当我想把A组扩到30%的时候,就会有一些问题。我们刚才说的拿手机取域就是下面这个人群,大家可以看20、20、60这样一个比例,如果拿手机号尾号区间实现的话,我把那个区间加大就可以,从B组挪两个人过来,再从控制组组挪两个人过来,这就实现了30:20:50这样一个结果,但是这个是有问题的,我们把它叫做比较糟糕的扩量。因为你在做实验的时候,你希望的是A组和B组与做实验人之前是双盲的,这个时候,忽然你把B组的用户切到了A组,这个作用在最终结果上就会出现偏差。更好的方式是什么呢,就是我从A里面挪过来,对B组不做任何的变化,由此也转化为了一个挪动影响最小的算法问题
对于这种大型产品来讲,一定要梳理好你的日志,因为日志是所有决策数据的源头,如果日志不准,打的乱七八糟会有很多的问题,所以我们也和滴滴的其他部门一起合作在着力推动日志统一的事情,这里面有几个点很关键,第一个是日志要有规范,然后要有来源的管理,就是不同的服务器在端的本地,不同场景下日志要有规范化的管理,然后要有日志搜集的手段,比如说怎么做连接和清洗,怎么做管理,不符合的得到预警,然后才能基于这些数据做很多的应用系统。
事件池、指标池建设,其实还是基于日志展开,如果大家在需要指标的时候,不看别人有没有埋这个对应的点,然后自己就去埋了,这会有很多问题,比如说对用户流量的影响,对于性能的影响,这些都需要去建立池子,进行统一的管理,然后让大家一起来贡献。计算指标也是一样的,你可以想象如果两个产品线对于转换率的计算方式完全不一样,那大家在比较转化率的时候又有什么意义呢,这些东西都要统一来做。
实验的科学性,实验设计时要考虑多种因素,比如说新鲜期影响,我调整了一个界面,可能用户一开始会觉得这个挺好玩的,我要多点几次。但是随着它对这个东西的熟悉呢,他慢慢就没有那么新鲜了。还有一个是局部优化,我调整了一个按纽的颜色,看似对按纽的点击产生了影响,但是有可能会对我的Title bar点击产生了负向的影响,对于整体来讲可能是一个零和的,也就意味着没有任何变化,左手倒右手而已。此外还需要考虑周期性因素,不同时间对用户的不同影响;选择指标的时候也需要有针对性,不要一味地追求大的结果指标,忽略掉实际的提升点。
实验的统计非常重要,因为实验往往是基于局部去猜测全局,如果样本小,执行时间少,很容易让你在拿到一个看似比较好的数据,或者符合你假设的时候,你可能会下一个错误的结论,在这个时候一定要考虑在统计学上的意义,通常我们建议使用p-value和power做为实验决策的辅助指标。
本文根据作者在QCon全球软件开发大会的演讲内容整理。
作者:齐贺,滴滴出行工程生产力团队研发技术总监,长期致力于高效能团队建设,目前主要的工作方向是在移动互联网场景下,结合大数据技术,建立灵活、准确的产品研发闭环。推动灰度发布、AB测试等实践在公司范围的落地,推进滴滴的数据驱动转型,同时也为组织效率提升方面贡献行之有效的方案。

















 3901
3901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









