







原文链接:The importance of preprocessing in data science and the machine learning pipeline I: centering, scaling and k-Nearest Neighbours
作者:Hugo Bowne-Anderson
译者:刘翔宇 审校:刘帝伟
责编:周建丁(zhoujd@csdn.net)
未经许可,谢绝转载!
数据预处理是一个概括性术语,它包括一系列的操作,数据科学家使用这些方法来将原始数据处理成更方便他们进行分析的形式。例如,在对推特数据进行情感分析之前,你可能想去掉所有的HTML标签,空格,展开缩写词,将推文分割成词汇列表。在分析空间数据的时候,你可能要对其进行缩放,使其与单位无关,也就是说算法不关心原始的度量是英里还是厘米。然后,数据预处理并不是凭空产生的。预处理只是一种达到目的的手段,并没有硬性、简便的规则:我们将会看到这有标准的做法,你也会了解到哪些可以起作用,但最终,预处理一般是面向结果管道的一部分,它的性能需要根据上下文来判断。
在这篇文章中,我将通过缩放数值数据(数值数据:包含数字的数据,而不是包含类别/字符串;缩放:使用基本的算术方法来改变数据的范围;下面会详细描述)来向你展示将预处理作为机器学习管道结构一部分的重要性。为此,我们将会使用一个实际的例子,在此例子中缩放数据可以提升模型的性能。在文章的最后,我也会列出一些重要的术语。
首先,我将介绍机器学习中的分类问题以及K近邻,它是解决这类问题时使用到的最简单的算法之一。在这种情形下要体会缩放数值数据的重要性,我会介绍模型性能度量方法和训练测试集的概念。在接下来的试验中你将会见识到这些所有的概念和实践,我将使用一个数据集来分类红酒的质量。我同样会确保我把预处理使用在了刀刃上——在一次数据科学管道迭代开始的附近。这里所有的样例代码都由Python编写。如果你不熟悉Python,你可以看看我们的DataCamp课程。我将使用pandas库来处理数据以及scikit-learn 来进行机器学习。
机器学习中分类问题简介
给现象世界中的事物进行分类和标记是一门古老的艺术。在公元前4世纪,亚里士多德使用了一套系统来分类生物,这套系统使用了2000年。在现代社会中,分类通常作为一种机器学习任务,具体来说是一种监督式学习任务。监督式学习的基本原理很简单:我们有一堆有预测变量和目标变量组成的数据。监督式学习的目标是构建一个“擅长”通过预测变量来预测目标变量的模型。如果目标变量包含类别(例如“点击”或“不是”,“恶性”或“良性”肿瘤),我们称这种学习任务为分类。如果目标是一个连续变化的变量(例如房屋价格),那么这是一个回归任务。
以一个例子进行说明:考虑心脏病数据集,其中有75个预测变量,例如“年龄”,“性别”和“是否吸烟”,目标变量为心脏病出现的可能性,范围从0(没有心脏病)到4。此数据集的许多工作都集中于区分会出现心脏病的数据和不会出现心脏病的数据。这是一个分类任务。如果你是要预测出目标变量具体的值,这就是一个回归问题了(因为目标变量是有序的)。我将会在下一篇文章中讨论回归。在这里我将集中于讲述分类任务中最简单的算法之一,也就是K近邻算法。
机器学习中K近邻分类
假如我们有一些标记了的数据,比如包含红酒特性的数据(比如酒精含量,密度,柠檬酸含量,pH值等;这些是预测变量)和目标变量“质量”和标签“好”和“坏”。然后给出一条新的未标记的红酒特性数据,分类任务就是预测这条数据的“质量”。当所有的预测变量都是数值类型时(处理分类数据还有其他的方法),我们可以将每一行/红酒看作是n维空间中的一点,在这种情形下,不管在理论上还是计算上,K近邻(k-NN)都是一种简单的分类方法:对于每条新的未标记的红酒数据,计算一个整数k,是在n维预测变量空间中距离最近的k个质心。然后我们观察这k个质心的标签(即“好”或“坏”),然后将最符合的标签分配给这条新的红酒数据(例如,如果k=5,3的质心给出的是“好”,k=2的质心给出的是“坏”,那么模型将新红酒数据标记为“好”)。需要注意的是,在这里,训练模型完全由存储数据构成:没有参数需要调整!
K近邻可视化描述
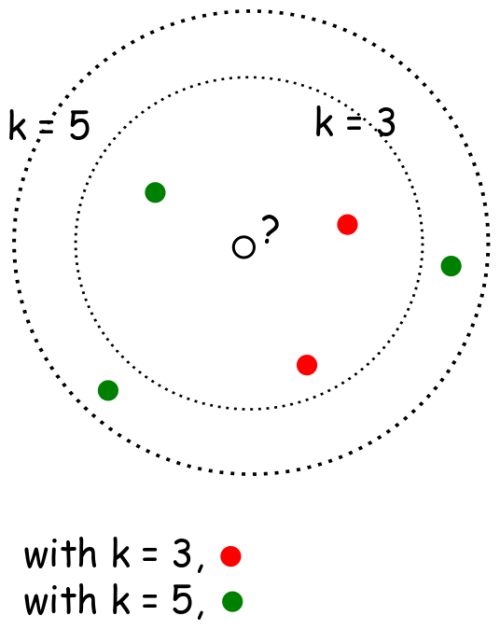
下图是2维k-NN算法的样例:你怎么分类中间那个数据点?如果k=3,那么它是红色,如果k=5,那么它是绿色。
from IPython.display import Image
Image(url= 'http://36.media.tumblr.com/d100eff8983aae7c5654adec4e4bb452/tumblr_inline_nlhyibOF971rnd3q0_500.png')
Python(scikit-learn)实现k-NN
现在我们来看一个k-NN实战例子。首先我们要导入红酒质量数据:我们把它导入到pandas的dataframe中,然后用直方图绘制预测变量来感受下这些数据。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









