






 本文探讨了AWS大数据实时流处理的趋势,强调了Spark在实时流处理中的重要性。通过Kinesis Streams、生产者和消费者应用的详细阐述,介绍了AWS实时大数据分析的参考架构,并提供了相关最佳实践,包括Kinesis Streams的配置要点、生产者应用的选择和消费者应用的资源分配建议。同时,提到了Spark Streaming的工作原理和注意事项,以及AWS Kinesis Analytics服务的预览,展示了一个简化服务器管理的Lambda架构方案。
本文探讨了AWS大数据实时流处理的趋势,强调了Spark在实时流处理中的重要性。通过Kinesis Streams、生产者和消费者应用的详细阐述,介绍了AWS实时大数据分析的参考架构,并提供了相关最佳实践,包括Kinesis Streams的配置要点、生产者应用的选择和消费者应用的资源分配建议。同时,提到了Spark Streaming的工作原理和注意事项,以及AWS Kinesis Analytics服务的预览,展示了一个简化服务器管理的Lambda架构方案。
随着移动互联网和物联网(IoT)技术的飞速发展,各种移动设备、智能器件 、社交网络和在线游戏等每一秒钟都在产生着大量的半结构化和非结构化数据,其中蕴含的巨大的价值和机会仍有待于我们去发掘。
Hadoop平台已经存在十年多,针对于海量数据通过Map/Reduce算法进行批处理也早已飞入寻常百姓家,成为每一个大数据工程师的入门级装备,但是如何更好的让大数据技术产生价值,在大数据特性的3个V:Volume、Variety、Velocity中, Velocity是成功与否的关键。所以,如何实时挖掘数据的价值,成为大数据领域的焦点。对流式数据的实时分析,很多用户还正在寻找一个适合自己的架构平台。
三年来,AWS技术支持,一直在大数据业务上为国内客户提供了从业务分析、架构设计到平台搭建、性能调优和故障诊断等全方位的咨询和帮助。同时我们基于客户案例的分析和总结,也发现如下非常明显的趋势:
- 2013-2014年,客户问题主要集中在以Java、Python等开发语言为主的Hadoop应用实践和参数调优方向。
- 2014-2015年,主要问题向交互式应用Hive、Impala、Presto,工作流管理Oozie,以及HBase等各种Hadoop生态系统中的组件上转移,客户更加专注在实际业务上。
- 2015-2016年,Spark以其同时支持批处理、交互式、迭代以及实时流处理等特性成为客户案例和咨询中最热门的关键词,而将Spark应用在实时流处理上的案例又是其中最多的。
另一个明显的趋势就是随着客户对AWS大数据服务的熟悉,问题也越来越深入和复杂,通过技术支持不仅可以很快的避开其他AWS用户已经碰到的问题、还可以了解到目前最流行的架构,快速的搭建比肩Netflix、NASDAQ等著名公司的大数据平台。
在AWS上,结合最近上线的Kinesis服务,使用EMR包含的Spark Streaming方案,已经成为主流,相比用户在EC2自搭Kafka + Storm要简单得多。该架构可参考图1。
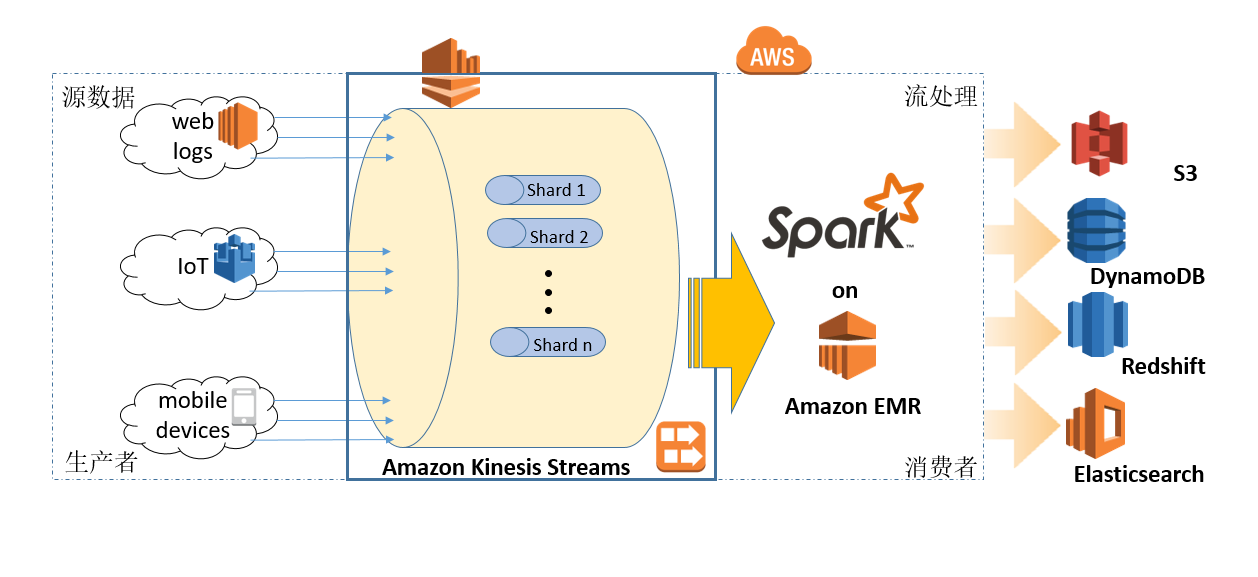
接下来将从Kinesis Streams流配置、生产者应用和消费者应用程序三个方面来阐述该架构的特点和最佳实践:
Kinesis Streams
- put到get的延迟小于1秒。即生产者的数据可以立即被消费。
- 多个消费者应用可以并发和互相独立地消费生产者放入Kinesis流中的数据。
- 流(Stream)等同于Apache Kafka中的Topic概念。
- 流中的每一条记录都有一个唯一的序列号。
- 记录按照Partition Key的MD5哈希值做分片(shard)。
- 分片的限制为:读请求2MB/s,写请求1MB/s。
- 单条记录最大大小为1MB。
- 缺省保留时间为24小时,可扩展到7天。
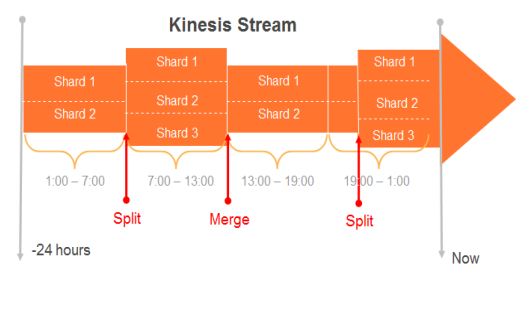
- 动态扩展收缩工具(图2),详见https://github.com/awslabs/amazon-kinesis-scaling-utils
生产者应用程序
针对生产者,有三种方式:使用KPL库、使用Java API,或者使用Kinesis Agent。使用KPL的好处:
- 自动重试机制。
- 聚合多记录,改进吞吐量,结合KCL消费者端自动分解。
- 与CloudWath指标关联,直观了解应用性能。
图2 amazon-kinesis-scaling-util
消费者应用程序
- 每个消费者应用在同一个region下取名要唯一,因为该名称被用于创建DynamoDB表,并存储Checkpoint相关的信息,该名称还用于CloudWatch监控指标的收集。
- 使用最新版本的EMR,EMR 4.x每6周发布一个新版本,包含Spark和AWS SDK的最新版本。
- 分配足够的计算资源来防止饥饿现象,同时也可以减小单个批次数据的处理时间。
关于Spark的最佳实践
Spark是基于内存的通用计算引擎,其核心思想是RDD (resilient distributed dataset,分布式弹性数据集) ,即一组分区的不可变记录集,Spark针对RDD提供两组API: transformations和actions,每一个transformation会得到新的RDD,按照函数式语言思想,lazy evaluation,只是在遇到action操作时才返回结果。按照应用的逻辑RDD之间构成一定的关系lineage,形成有向无环图(DAG),所以Spark与生俱来就有故障恢复能力,可以很快的重建丢失的RDD记录。
Spark Streaming是建立在Spark核心API之上,其工作原理如下:
将输入的raw数据流转化为基于一定时间窗口的微批次micro-batch,然后通过Spark引擎处理得到成批次的结果流,用于dashboard呈现或者存储。
连续的数据流,即RDD序列在Spark Streaming中被称之为离散流(discretized stream,或者DStream)。针对每个输入离散流Spark会调度一个Receiver来接受和存储该数据。
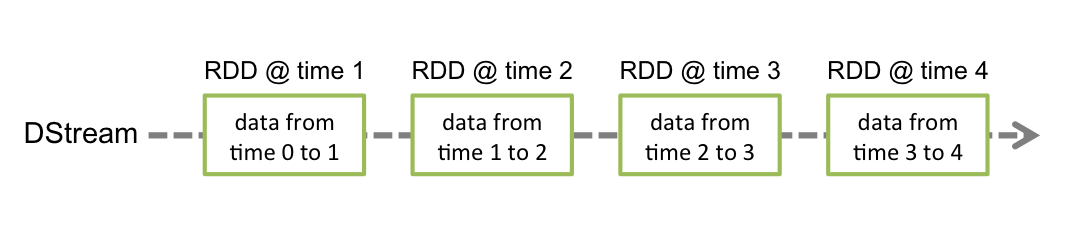
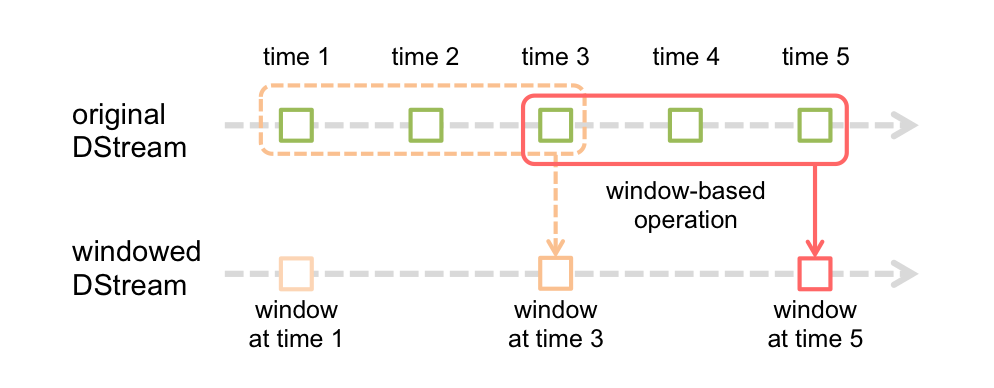
在开发Spark Streaming应用时,需要注意的几点:
- Transformation和Output(action)操作在调用ssc.start () 之后才开始执行,而且开始后无法再修改或者添加新的操作。
- ssc.stop () 之后,无法再重启。同一时间一个sc下只有一个active的ssc。
- 在一个streaming应用中接受多个数据流,需要创建多个DStream时,为应用分配的core数一定要大于Receiver的个数。
- 自EMR4.4发布,缺省已经打开spark.dynamicAllocation.enabled 和 maximizeResourceAllocation,这些参数可以更优化系统资源的使用,根据实际应用还可以继续调整spark.executor.memory和spark.executor.cores进一步优化性能。
- 提交任务的时候使用–master yarn-cluster模式,可以将Driver放到从节点上释放主节点的压力。
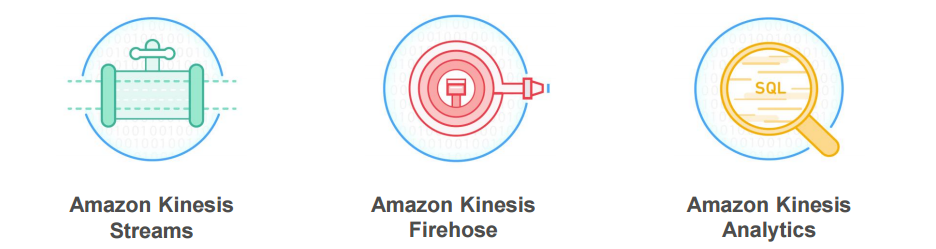
随着AWS Kinesis Analytics服务预览的推出,相信很快会有更多高效和易用的选项供大家选择。下图中的Kinesis Firehose可以直接将数据流写入S3、RedShift、Elasticsearch等服务,不同于Kinesis Streams不需要用户撰写任何应用程序,弹性适应数据流的吞吐量的准实时服务。而分析模块Kinesis Analytics则可以直接使用SQL来分析和查询数据流。
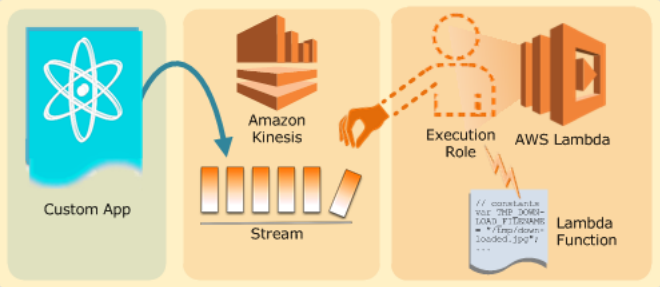
最后提一下目前流行的Lambda架构也是处理实时数据的优秀选项。















 394
394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









