






在本练习中,您将学习如何使用Redshift和Amazon QuickSight平台构建数据可视化应用程序。您将看到如何使用Amazon的数据仓库从数据湖中装载数据,并用完全托管的数据可视化工具进行展现。
本实验的目标包括:
- 1、 创建Redshift集群
- 2、 将S3的数据文件批量装载到Redshift数据库
- 3、 使用Quicksight对数据表进行可视化
本实验的架构图如下
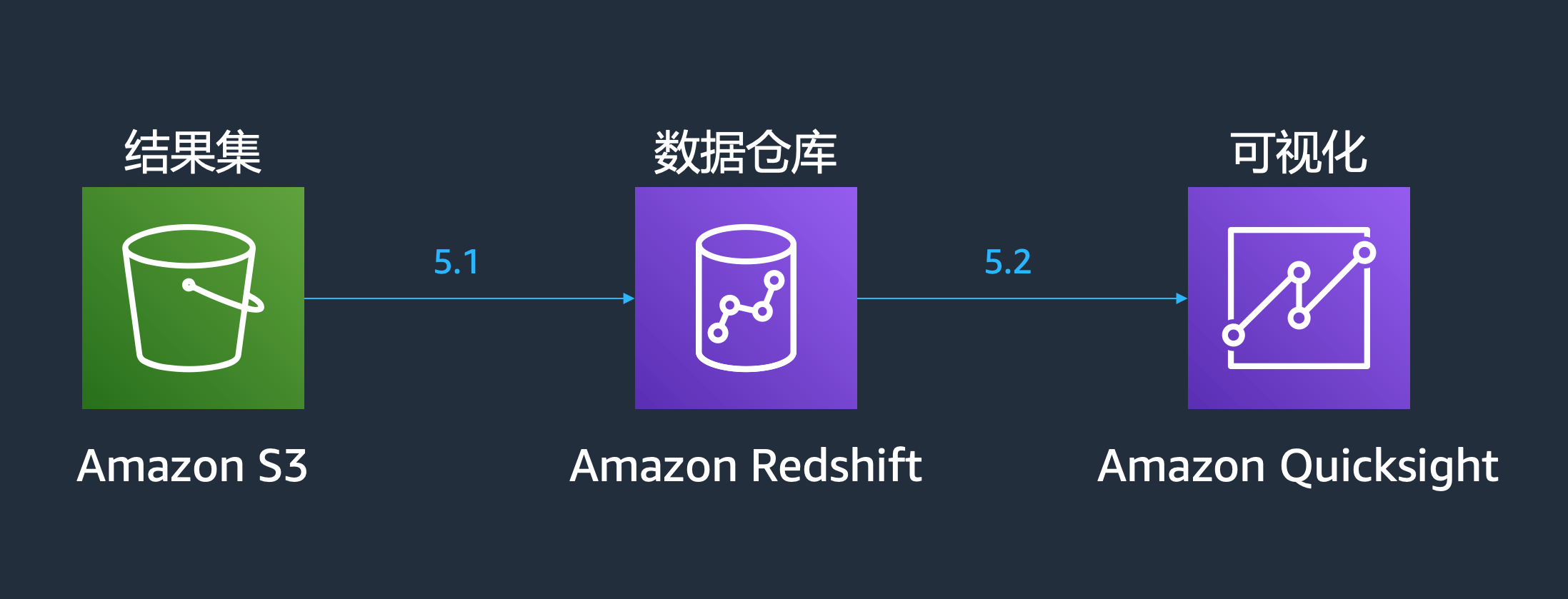
构建数据仓库
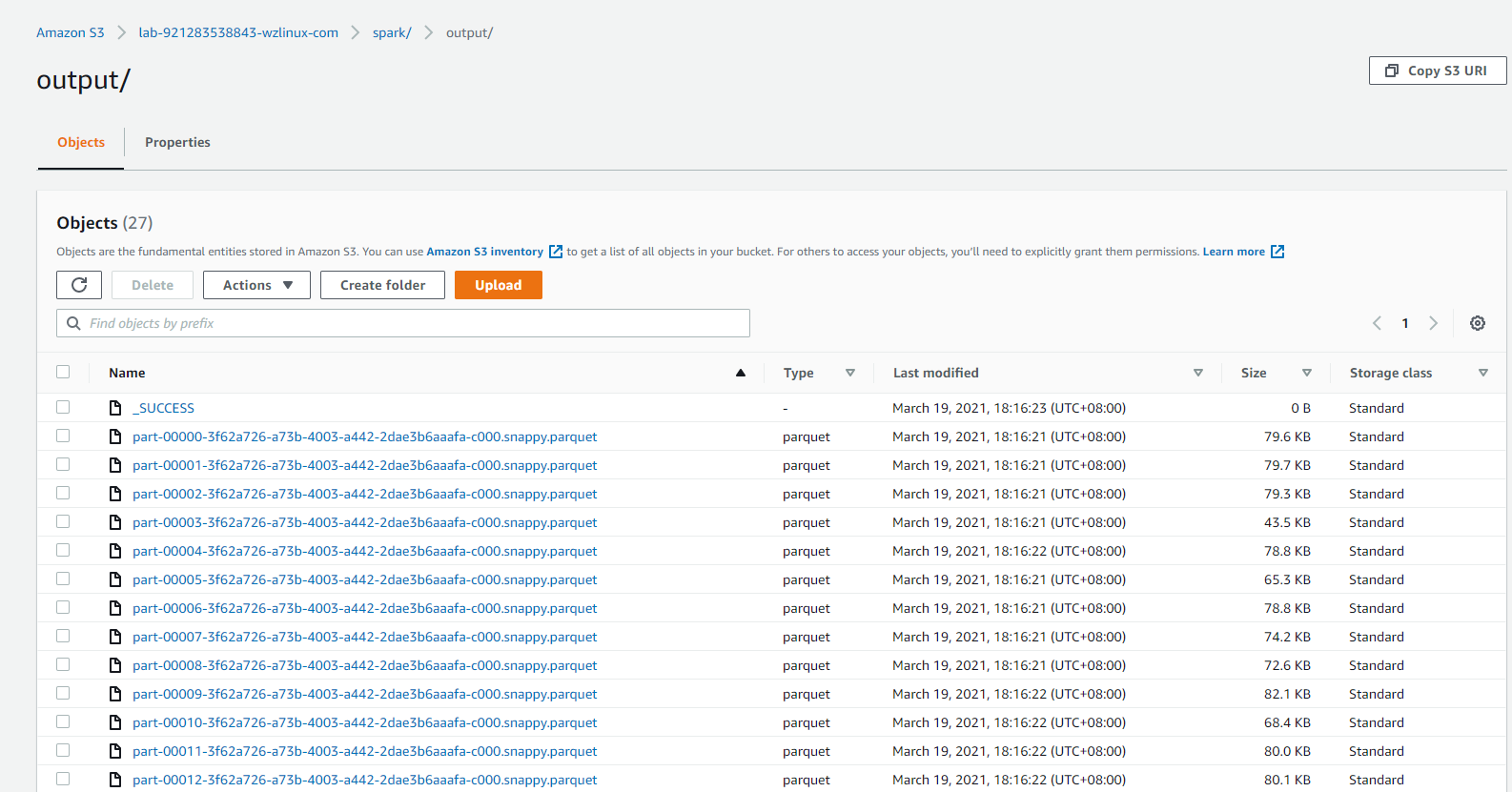
1.查看数据
查看 S3 桶(此处为 s3://lab-921283538843-wzlinux-com/spark/output)内的 EMR 实验中生成的parquet 格式文件是否存在。
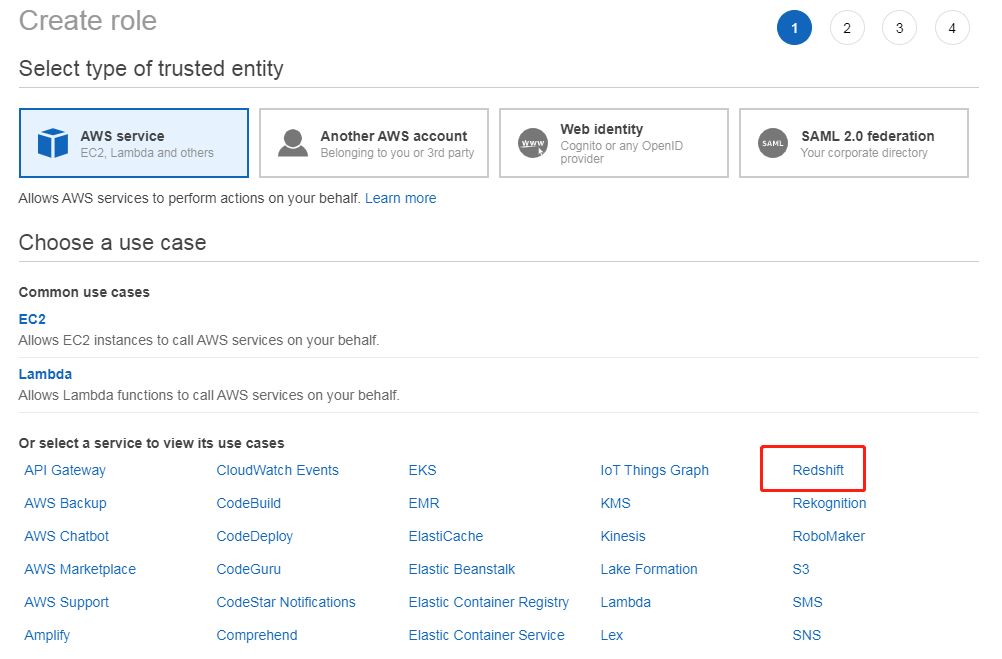
2.创建 IAM Role
选择 IAM 服务,点击角色->创建角色,选择 Redshift
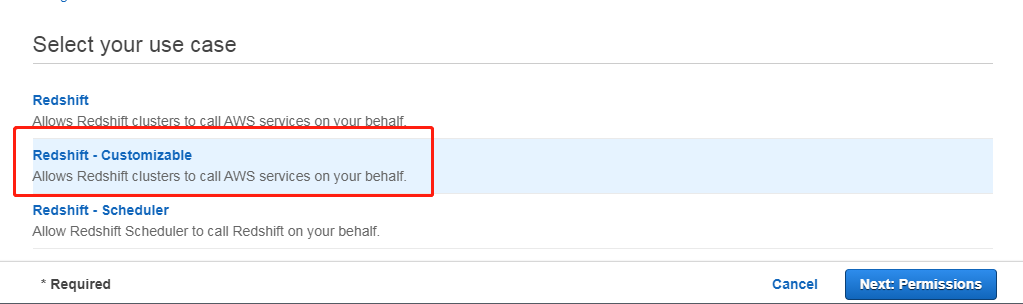
选择 Redshift-Customizable,点击下一步权限
选择权限 AmazonS3ReadOnlyAccess
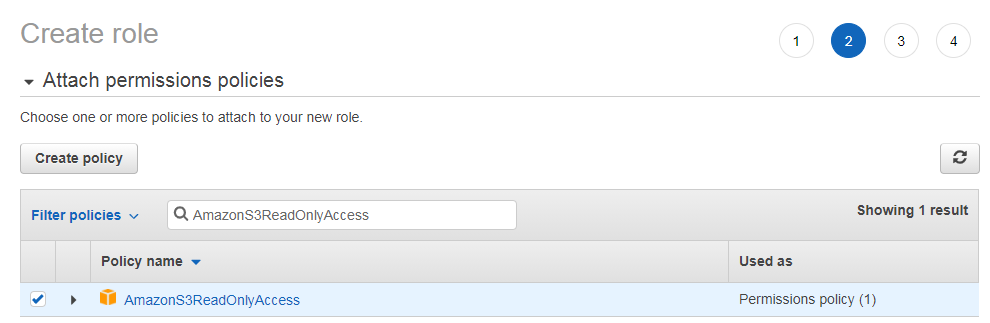
添加权限名字 myRedshiftRole,点击确认
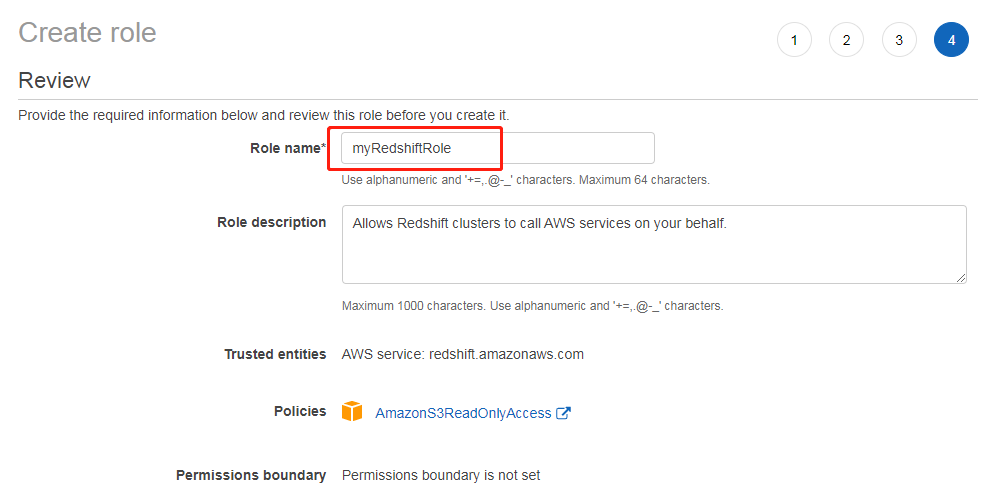
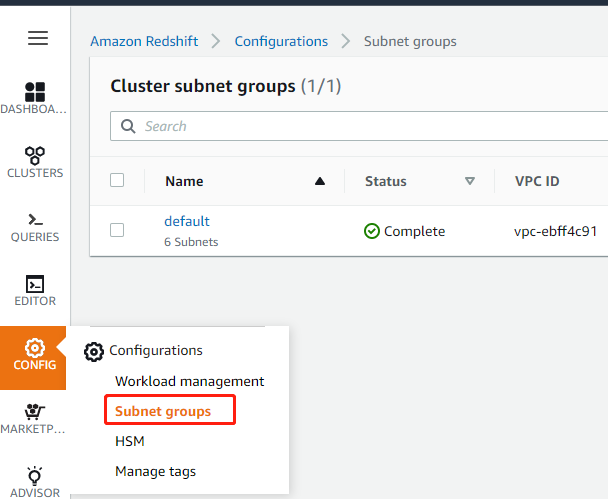
3.创建子网组
创建 Redshift 集群前,先创建子网组。选择 Redshift 服务,在左边菜单条中选择“CONFIG”->”管理子网组“
然后选择“创建集群子网组”,子网组名称可接受缺省名字“cluster-subnet-group-1“,在描述框中输入任意说明文字。选择“默认VPC”,选择“为此 VPC 添加所有子网“,然后点击“创建集群子网组”完成创建子网组。
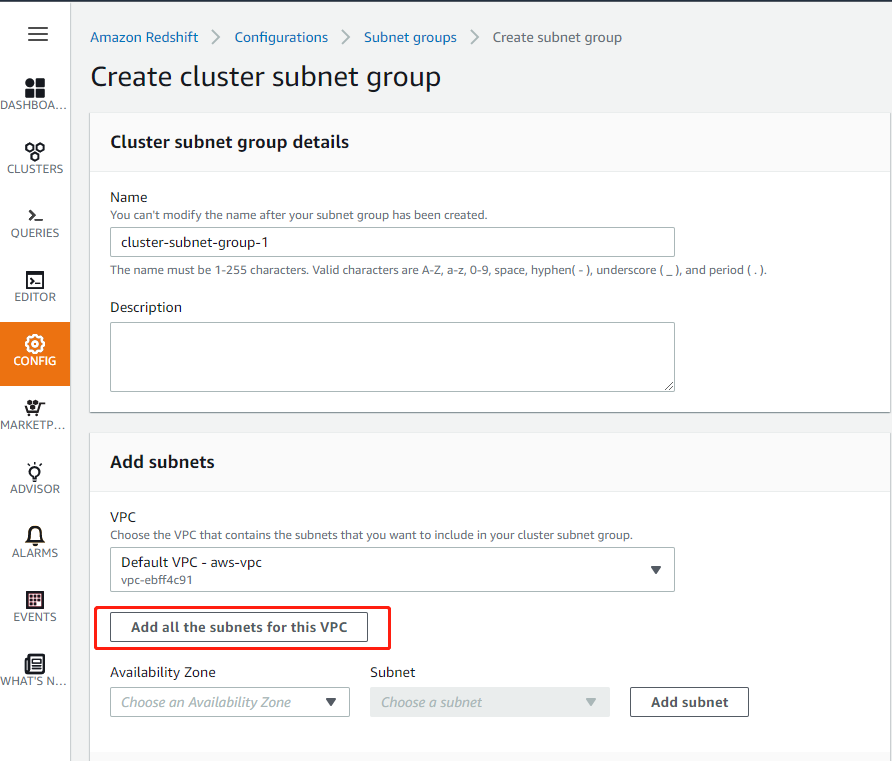
4.创建 Redshift 集群
在左侧菜单中选择“集群”,点击“创建集群“,设置集群的名字(不要用中文,不要用特殊字符,英文开头,可以有数字,可以有减号),节点类型选择 dc2.large
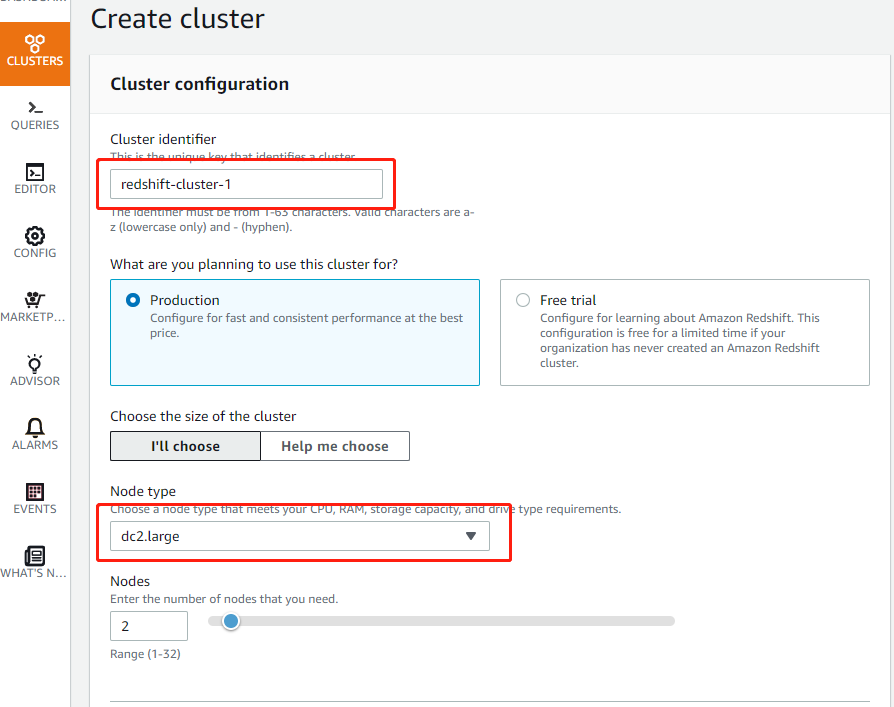
数据库配置接受缺省值,输入主用户密码(请记住您输入的密码)
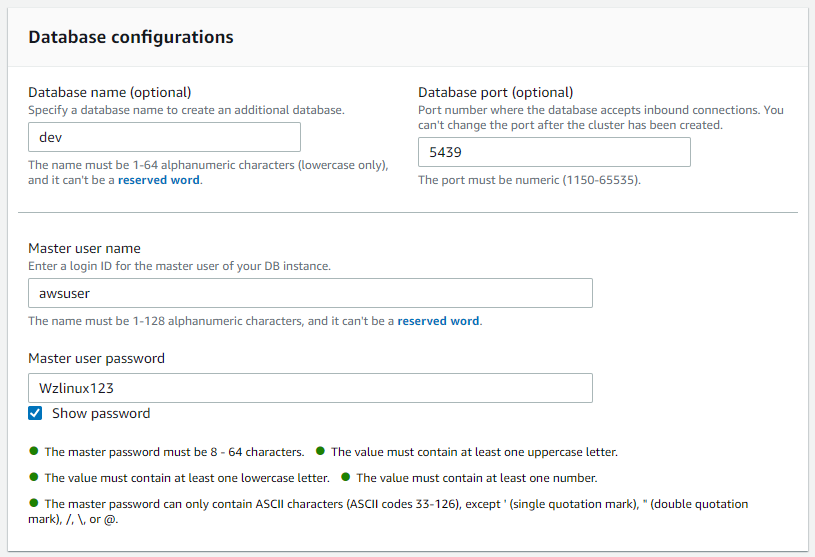
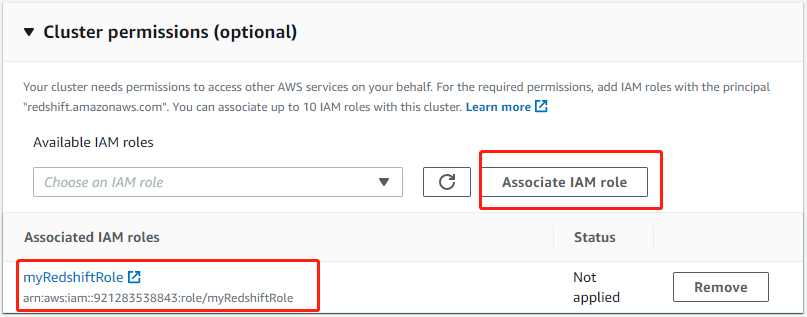
集群权限中,选择前面创建的 myRedshiftRole 角色,点击“Associate IAM role”
其它配置中,选择默认 VPC,缺省安全组和之前创建的集群子网组,点击确认“创建集群”,大约5分钟后,集群变为“Available”状态。
5.访问 Redshift 数据库
有两种方式访问 Redshift 数据库,一种是通过 Redshift Console 上的查询编辑器,一种是通过 SQL 客户端(例如 SQL Workbench/J 客户端)。
本实验中为了简便操作,使用 Redshift Console 上的查询编辑器来访问数据库。选择左边菜单中“编辑器”,在“连接到数据库”窗口中输入一下参数,然后“连接到数据库”
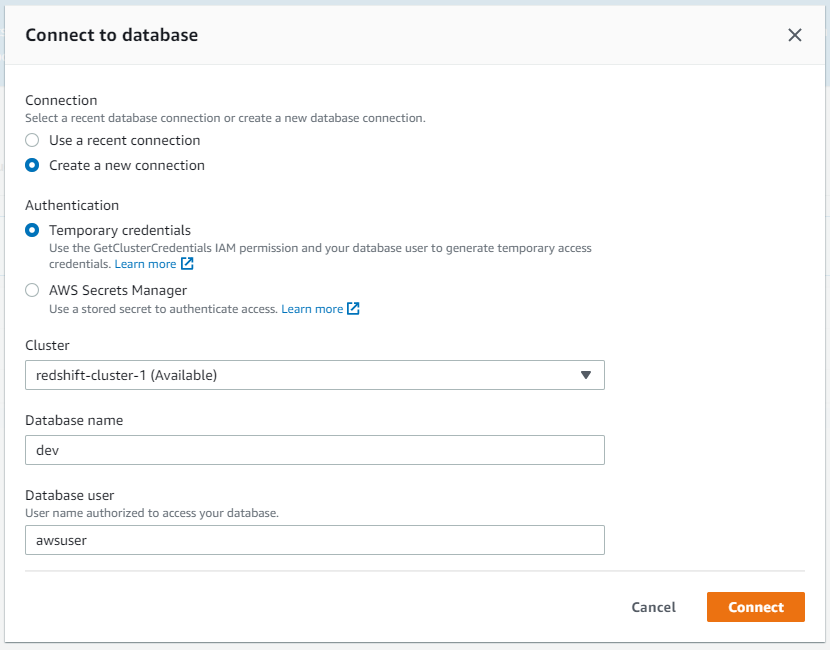
6.创建表
在查询编辑器中创建表,在左边Select Schema中选择“Public”,然后在SQL查询窗口中输入创建表的SQL语句:
create table table1(
tno varchar(20),
tdate varchar(15),
uno varchar(10),
pno varchar(10),
tnum int,
uname varchar(20),
umobile varchar(20),
ano varchar(20),
acity varchar(50),
aname varchar(50),
pclass varchar(10),
pname varchar(50),
price decimal(10, 2)
);如下图所示
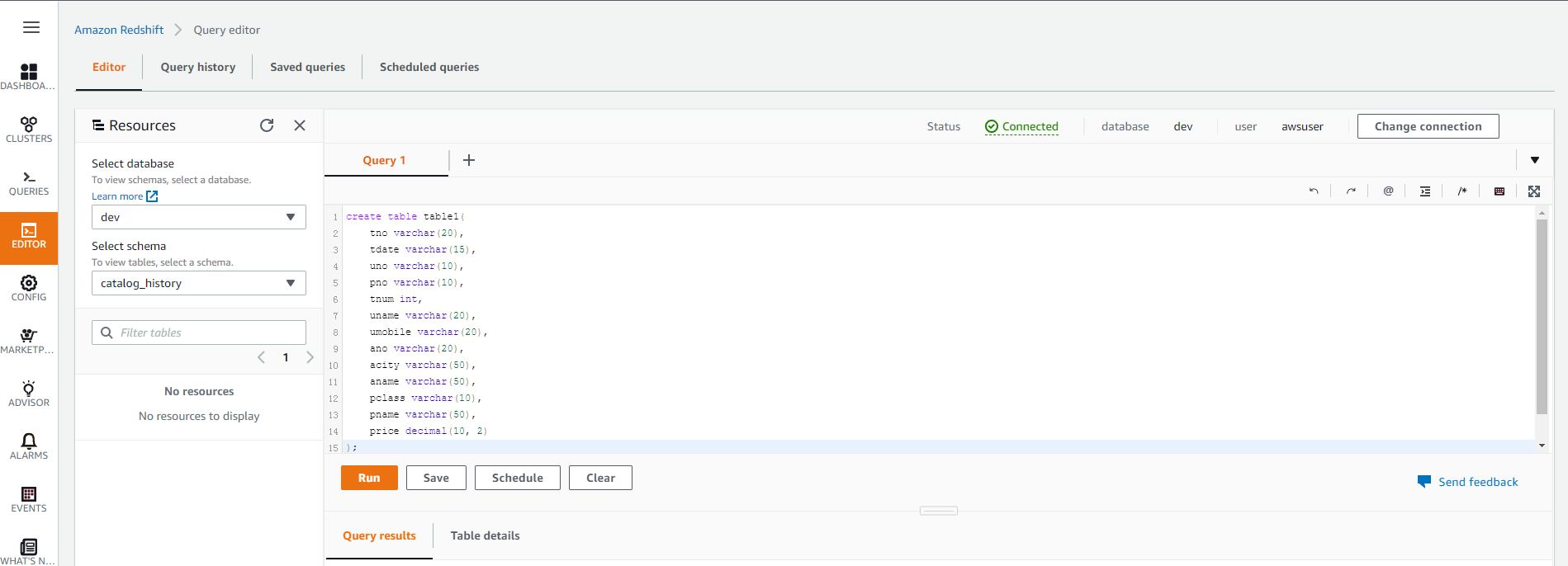
选择“运行”,结果应该显示”Completed”
7.导入S3数据
新开一个 SQL 查询窗口(此处为 Query 2),输入下面装载 S3 数据的 SQL 命令,注意要将帐号替换为实际的帐号 ID,并确认争取的 S3 桶地址。
copy table1 from 's3://lab-921283538843-wzlinux-com/spark/output/'
credentials 'aws_iam_role=arn:aws:iam::921283538843:role/myRedshiftRole'
format as parquet;如下图所示
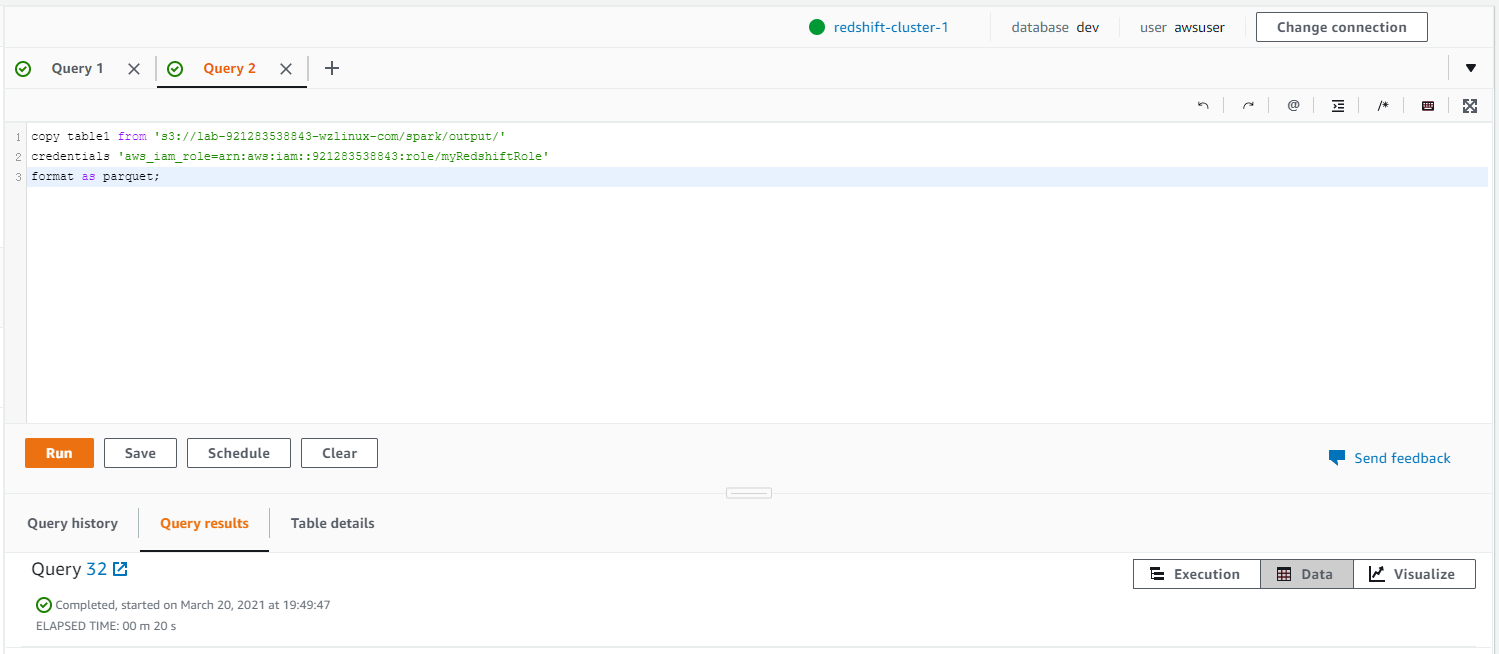
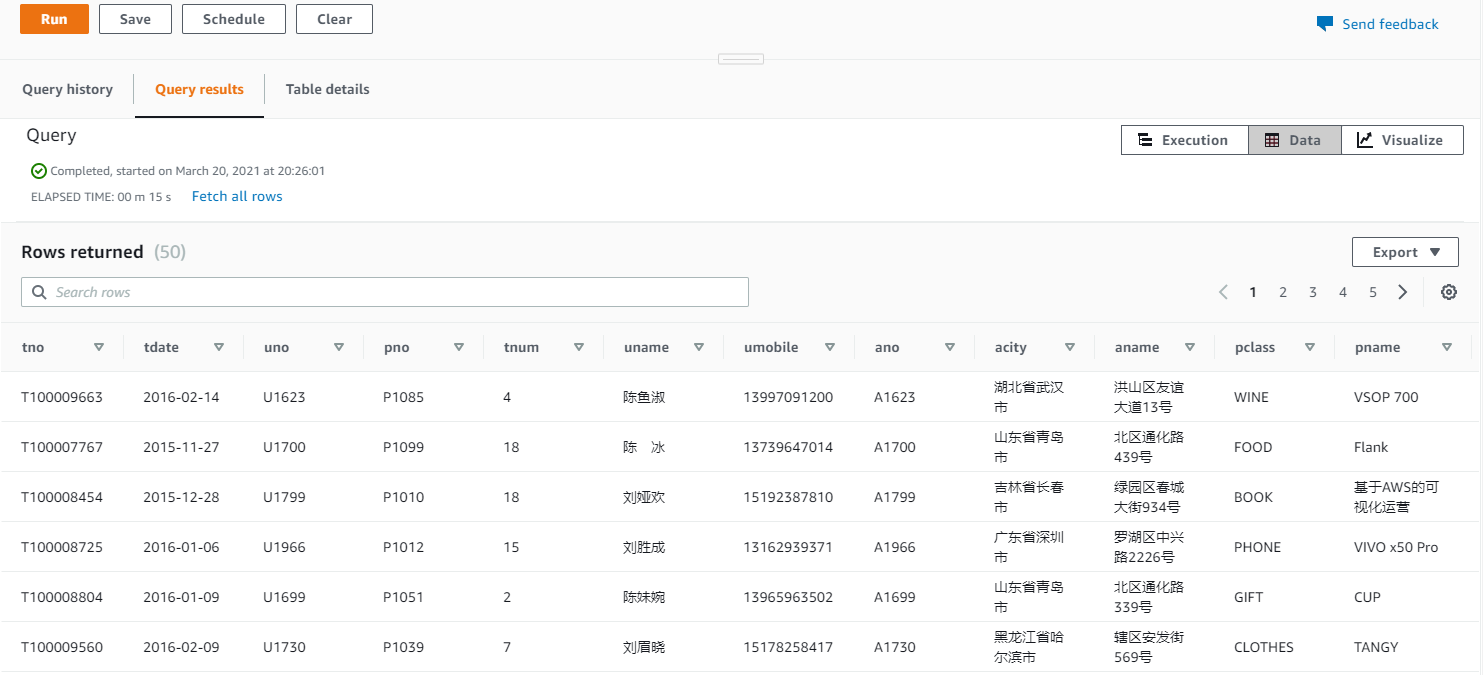
点击运行,结果应显示为“Completed”。在 Query3中 输入”select from table1;”应查询中表中的数据。在Query4 中输入“select count() from table1; “,应查询到表中的数据。这说明 S3 中的数据已完成 copy 到 Redshift 数据仓库中。
8.允许 Internet 访问
下一步,我们将使用 AWS Quicksight 将 Redshift 中的数据进行可视化展现。在此之前,需要给予 Quicksight 从 Internet 访问 Redshift 的权限。为此,我们先在 EC2 菜单中创建一个公网的弹性 IP 地址(过程略)。然后修改 Redshift 属性,赋予公开访问权限。
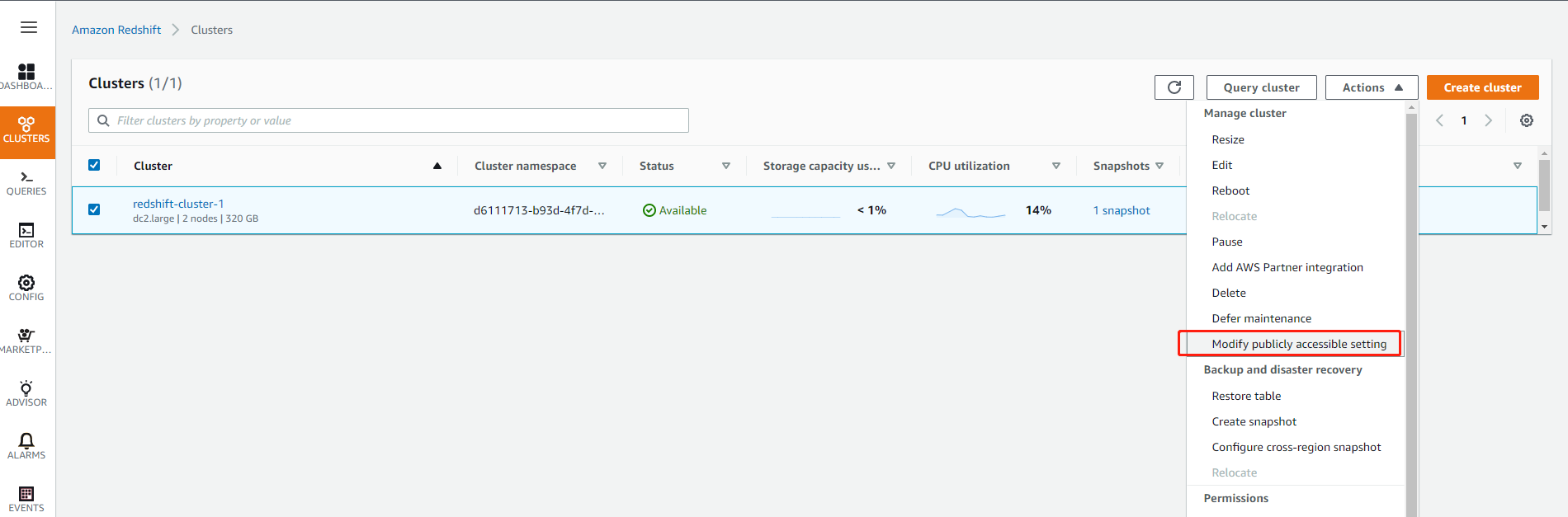
将可公开访问改成“是”,选择对应的弹性公网 IP 地址即可。
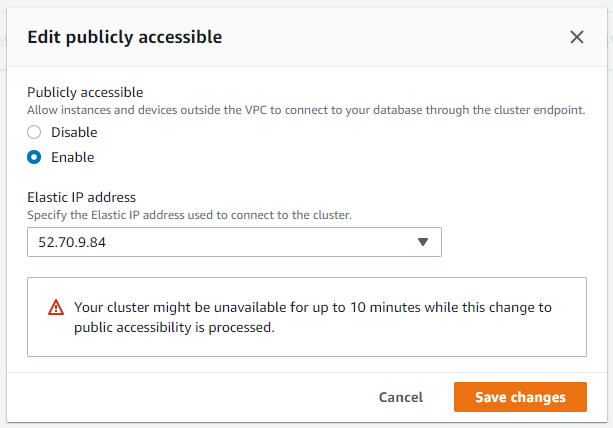
此操作需要一点时间,略微等待几分钟即可。
数据可视化
1.启用 Quicksight
关于启用 Quicksight 这里不再介绍,可以观看 Lab3。
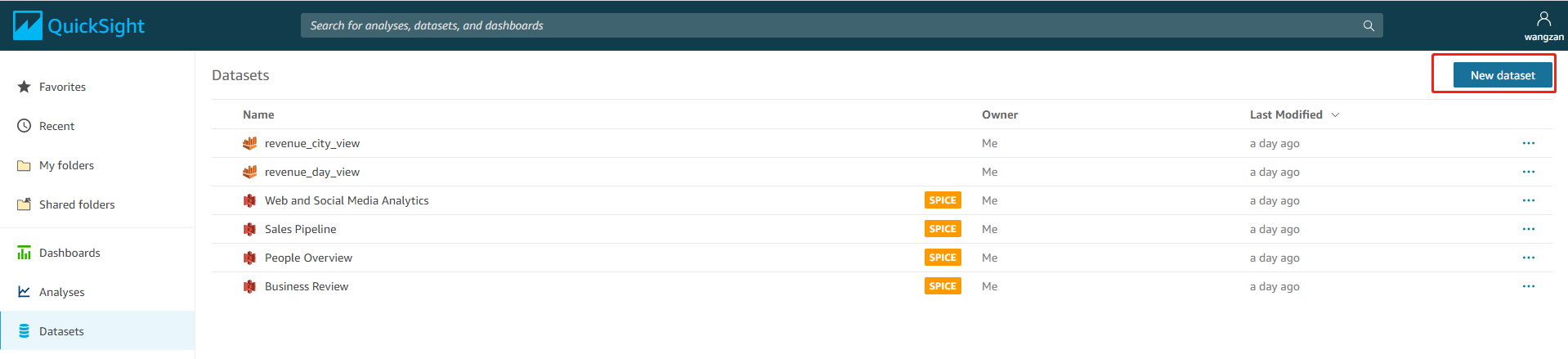
2.创建数据集
进入Quicksight控制台界面,点击左侧数据集,选择创建“新数据集”
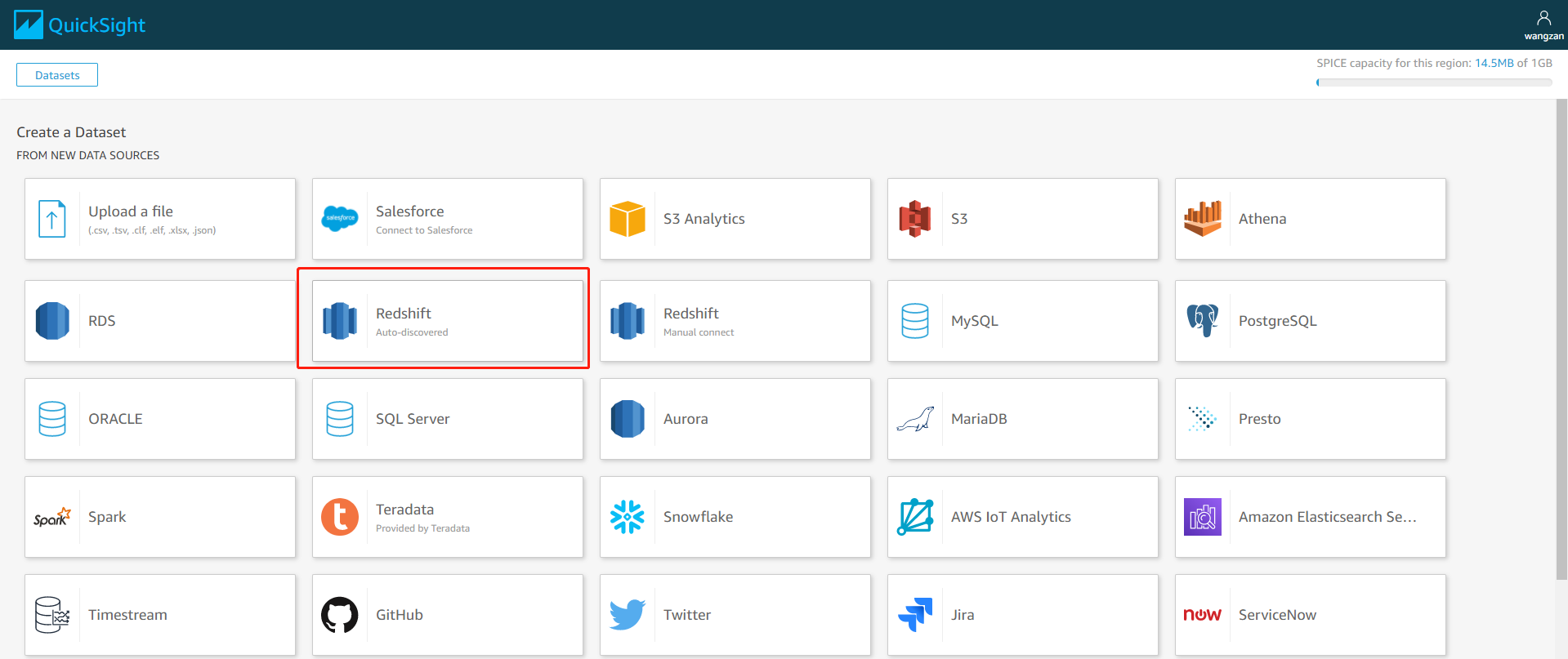
选择 Redshift(自动发现)数据集,Redshift 也有手动连接的方式,不过此处我们不演示
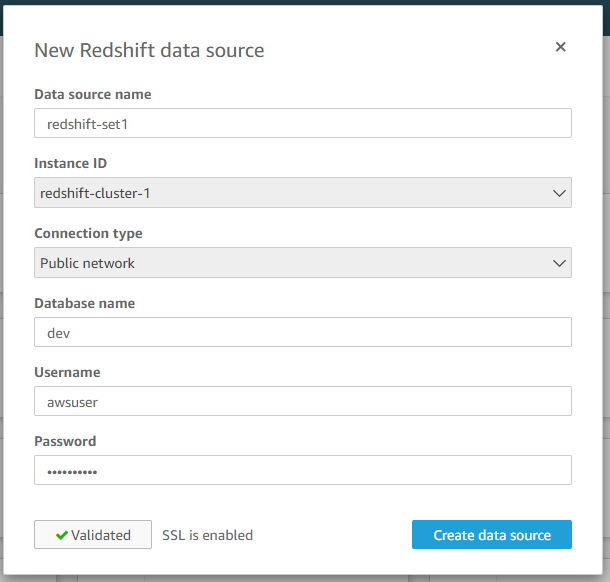
输入连接参数,选择“创建 data source”,选择对应的 Redshift 数据库,注意配置对应的地址,端口,数据库名称,用户名和密码
选择 Table1,点击“Select”,最后点击“Virtualize”完成创建数据集(此处我们选择把数据从 Redshift 导入到 Quicksigh 里面来,这样分析起来速度会快很多)
3.数据可视化
打开可视化对象窗口,选择展现方式为“竖条状图“
将 tdate 拖放到 X axis 栏,将 tnum 拖动到 value 栏(系统会自动选择计数)
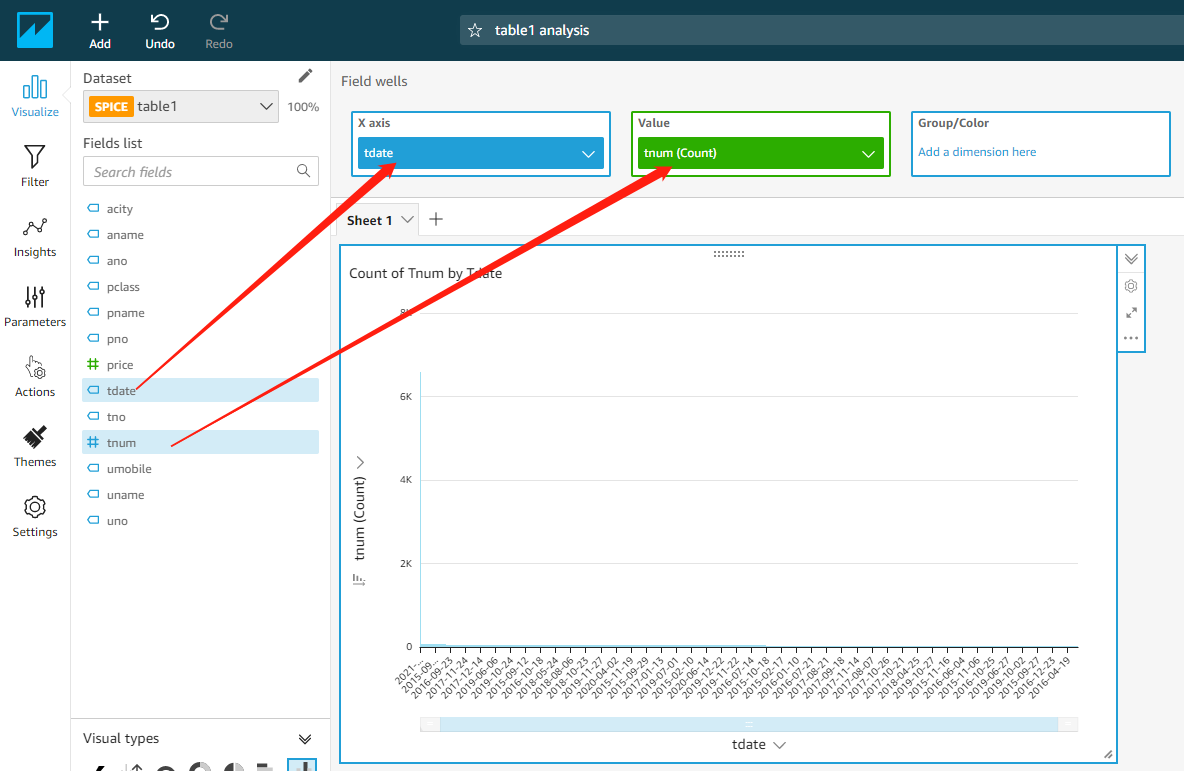
这样就完成了“以日期为X轴,以当天的总销售数量为Y轴从高到低的排名”展现。
欢迎大家扫码关注,获取更多信息
















 1268
1268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









