






1. 实验引言
1.1 背景知识
本实验中提到的“北美五大职业体育联盟”(以下简称“五大联盟”)包括传统的“北美四大职业体育联盟”和美国职业足球大联盟(MLS),其中,“北美四大职业体育联盟”由美国职业篮球联赛(NBA)、美国国家橄榄球联盟(NFL)、国家冰球联盟(NHL)以及美国职棒大联盟(MLB)组成。
1.2 选题背景
近年来,五大联盟中新军创建的脚步加快,成为体育产业关注的一大焦点。例如,国家冰球联盟在2017年新增了维加斯黄金骑士队(Vegas Golden Knights);2020年,由前著名足球运动员大卫·贝克汉姆参与创建的国际迈阿密足球俱乐部(Inter Miami CF),正式加入美国职业足球大联盟,在其之后又相继(将)有三支球队加入:奥斯汀足球俱乐部(Austin FC)(2021年)、夏洛特足球俱乐部(Charlotte FC)(2022年)、圣路易斯城足球俱乐部(St. Louis City SC)(2023年);2022年6月,著名球星勒布朗·詹姆斯在采访中谈及自己想要拥有一支位于拉斯维加斯的NBA球队的想法,随后他也在Twitter上证实了此事。
球队选址是球队创建过程中的重要决策,它对于球队的未来发展具有决定性作用。我对于球队创建者在球队选址方面的决策很感兴趣,这促使我选择在本实验中去探索球队的成功指数与地理分布的具体关系,从成功可能性的角度出发,分析已经做出的决策并预测未来潜在的决策。
2. 问题描述
2.1 研究对象
2.1.1 球队
本实验中研究涉及的球队为五大联盟中的美国本土球队,不包括位于加拿大的球队。
2.1.2 地理区划
本实验中研究涉及的地理区域范围为美国全境,主要采用的地理区划为城市(City)。
2.2 研究内容
本实验主要研究五大联盟球队的成功指数与地理分布信息之间的具体关系,并在此基础上构建预测模型,结合城市的地理分布信息预测在该地创建球队的成功可能性,从而根据预测结果找出最适合创建新军的城市。这里所提到的地理分布信息由五个地理影响因子组成:经度、纬度、城市人口密度(人/平方千米)、城市人口占所在州总人口的比例、所在州人均GDP(千美元)。
3. 实验方法
3.1 数据采集
3.1.1 Kaggle
首先从Kaggle网站(https://www.kaggle.com)上下载了5个csv文件形式的数据集,主要包含了五大联盟球队名单,美国各州的人口、GDP数据和各城市的经纬度、人口数据。数据集下载地址如下:
https://www.kaggle.com/datasets/logandonaldson/sports-stadium-locations
https://www.kaggle.com/datasets/alexandrepetit881234/us-population-by-state
https://www.kaggle.com/datasets/darinhawley/us-2021-census-cities-populations-coordinates
https://www.kaggle.com/datasets/axeltorbenson/us-cities-by-population-top-330
https://www.kaggle.com/datasets/davidbroberts/us-gdp-by-state-19972020
下载的数据集经过重命名后如下图所示:

3.1.2 Sportico
Sportico是PMC旗下的数字内容平台,致力于提供专业的体育产业相关信息。我从Sportico网站手动获取了五大联盟球队的冠军数、市值和年营销收入等数据。数据获取地址如下:
https://d3data.sportico.com/NBAVal2021/NBAVal.html
https://d3data.sportico.com/NFLVal2021/NFLVal.html
https://d3data.sportico.com/NHLVal/NHLVal.html
https://d3data.sportico.com/MLBVal2022/MLBVal.html
https://d3data.sportico.com/MLSVal/MLSVal.html
3.2 数据预处理
3.2.1 构建球队数据集
首先构建五大联盟球队数据集,命名为team_data.csv。
首先取US_teams.csv的Team和League字段加入team_data.csv,剔除位于加拿大的球队和缺乏有关数据的新成立球队,并更正部分球队名的拼写错误。
team_data.drop(labels=20, inplace=True) # Toronto Raptors
team_data.drop(labels=65, inplace=True) # Montreal Canadiens
team_data.drop(labels=67, inplace=True) # Winnipeg Jets
team_data.drop(labels=68, inplace=True) # Ottawa Senators
team_data.drop(labels=83, inplace=True) # Vancouver Canucks
team_data.drop(labels=84, inplace=True) # Edmonton Oilers
team_data.drop(labels=86, inplace=True) # Toronto Maple Leafs
team_data.drop(labels=87, inplace=True) # Calgary Flames
team_data.drop(labels=117, inplace=True) # Toronto Blue Jays
team_data.drop(labels=127, inplace=True) # Vancouver Whitecaps FC
team_data.drop(labels=128, inplace=True) # Toronto FC
team_data.drop(labels=145, inplace=True) # CF Montréal
team_data.drop(labels=132, inplace=True) # Inter Miami CF
team_data.drop(labels=138, inplace=True) # Nashville SC
team_data.drop(labels=142, inplace=True) # Austin FC
team_data = team_data.reset_index(drop=True)
team_data.loc[14, 'Team'] = 'Sacramento Kings'
team_data.loc[30, 'Team'] = 'Kansas City Chiefs'
team_data.loc[69, 'Team'] = 'Florida Panthers'
team_data.loc[84, 'Team'] = 'Philadelphia Flyers'
team_data.loc[108, 'Team'] = 'Cleveland Guardians'通过查询维基百科确定各球队的所在城市,若球队所在区域不为城市(如county, borough等),则以距离此区域最近的城市作为其所在城市。手动输入添加City字段。
cities = ['Dallas', 'Orlando', 'San Antonio', 'Denver', 'New York', 'Washington', 'Oakland', 'Los Angeles',
'Los Angeles', 'Memphis', 'Milwaukee', 'Phoenix', 'Miami', 'Indianapolis', 'Sacramento', 'Detroit',
'New York', 'Portland', 'Oklahoma City', 'Cleveland', 'New Orleans', 'Charlotte', 'Atlanta',
'Minneapolis', 'Boston', 'Houston', 'Chicago', 'Salt Lake City', 'Philadelphia', 'Oakland', 'Kansas City',
'Dallas', 'Charlotte', 'New Orleans', 'Denver', 'Washington', 'Cleveland', 'Detroit', 'Quincy',
'Miami Gardens', 'Pittsburgh', 'Buffalo', 'Green Bay', 'Santa Clara', 'Philadelphia', 'Indianapolis',
'Seattle', 'Baltimore', 'Atlanta', 'Newark', 'Newark', 'Nashville', 'Houston', 'Cincinnati', 'Tampa',
'Inglewood', 'Inglewood', 'Chicago', 'Glendale', 'Jacksonville', 'Minneapolis', 'Tampa', 'Dallas',
'Denver', 'Nashville', 'Washington', 'Seattle', 'Los Angeles', 'St. Louis', 'Davie', 'Tempe', 'Anaheim',
'Buffalo', 'Detroit', 'New York', 'Columbus', 'Raleigh', 'Pittsburgh', 'Newark', 'San Jose', 'Boston',
'Las Vegas', 'New York', 'Chicago', 'Philadelphia', 'Minneapolis', 'Milwaukee', 'Anaheim', 'St. Louis',
'Phoenix', 'New York', 'Philadelphia', 'Detroit', 'Denver', 'Los Angeles', 'Boston', 'Arlington',
'Cincinnati', 'Chicago', 'Kansas City', 'Miami', 'Houston', 'Washington', 'Oakland', 'San Francisco',
'Baltimore', 'San Diego', 'Pittsburgh', 'Cleveland', 'Seattle', 'Minneapolis', 'Tampa', 'Atlanta',
'Chicago', 'New York', 'Minneapolis', 'Washington', 'Los Angeles', 'Kansas City', 'Denver', 'Long Beach',
'Orlando', 'Quincy', 'Columbus', 'Seattle', 'Atlanta', 'San Jose', 'Houston', 'Portland', 'Newark',
'West Jordan', 'Chicago', 'Philadelphia', 'Frisco', 'Cincinnati', 'New York']利用Sportico网站提供的球队冠军数、市值和年营销收入数据,手动输入添加Titles, Team Value, Annual Revenue字段。其中,Los Angeles Lakers的冠军数中不包括球队在明尼苏达时代获得的5次冠军,Golden State Warriors的冠军数中不包括球队在费城时代获得的2次冠军,Oklahoma City Thunder的冠军数中不包括球队在西雅图时代获得的1次冠军。
titles = [1, 0, 5, 0, 0, 1, 4, 0, 12, 0, 2, 0, 3, 0, 1, 3, 2, 1, 0, 1, 0, 0, 1, 0, 17, 2, 6, 0, 3, 3, 2, 5, 0, 1, 3,
3, 0, 0, 6, 2, 6, 0, 4, 5, 1, 2, 1, 2, 0, 4, 1, 0, 0, 0, 2, 1, 0, 1, 0, 0, 0, 3, 1, 2, 0, 1, 0, 2, 1, 0,
0, 1, 0, 11, 4, 0, 1, 5, 3, 0, 6, 0, 4, 6, 2, 0, 0, 1, 11, 1, 2, 2, 4, 0, 7, 9, 0, 5, 3, 2, 2, 1, 1, 9, 8,
3, 0, 5, 2, 0, 3, 0, 4, 3, 27, 0, 4, 0, 2, 1, 5, 0, 0, 2, 2, 1, 2, 2, 1, 0, 1, 1, 0, 0, 0, 0]
team_values = [2670, 1690, 2050, 1740, 2660, 1990, 4470, 3060, 5550, 1530, 1960, 1900, 2490, 1800, 1880, 1740, 5450,
1990, 1670, 1750, 1510, 1600, 1830, 1550, 3410, 2790, 3450, 1690, 2520, 3180, 3080, 6470, 2730, 2820,
3800, 4030, 2730, 2440, 4650, 3320, 3570, 2500, 3470, 4220, 3870, 2830, 3600, 3100, 3250, 4630, 4080,
2680, 3840, 2400, 2800, 3960, 3000, 4000, 2690, 2650, 3120, 805, 825, 640, 680, 940, 860, 990, 710,
520, 410, 690, 600, 960, 1400, 525, 545, 845, 750, 705, 940, 835, 865, 1220, 910, 785, 1.43, 2.11,
2.335, 1.36, 2.68, 2.375, 1.45, 1.415, 4.11, 3.89, 1.89, 1.365, 1.715, 1.175, 1, 2.38, 2.16, 1.34,
3.34, 1.49, 1.745, 1.3, 1.385, 1.66, 1.59, 1.185, 2.27, 3.82, 5.89, 520, 630, 860, 550, 370, 835,
400, 480, 540, 705, 845, 510, 425, 635, 505, 420, 535, 530, 415, 500, 655]
annual_revenues = [296, 228, 279, 226, 283, 247, 434, 297, 418, 213, 252, 231, 283, 228, 275, 252, 428, 258, 251,
256, 213, 227, 236, 218, 308, 344, 304, 251, 284, 386, 491, 871, 478, 484, 496, 561, 449, 407,
611, 495, 486, 420, 500, 580, 536, 435, 493, 487, 521, 592, 549, 425, 556, 404, 429, 424, 390,
516, 422, 455, 489, 132, 152, 123, 138, 180, 170, 214, 134, 104, 97, 135, 125, 195, 229, 108,
116, 157, 159, 133, 186, 156, 94, 191, 184, 144, 286, 364, 388, 266, 394, 396, 259, 283, 555,
492, 341, 263, 255, 245, 218, 441, 376, 220, 434, 247, 314, 249, 267, 281, 289, 253, 406, 516,
702, 41, 53, 82, 45, 27, 80, 40, 36, 23, 67, 105, 36, 30, 59, 43, 33, 27, 37, 40, 32, 51]在这三列数据的基础上,计算每支球队的冠军数、市值和年营销收入在其所属联盟中分别占据的比例,由此新增Proportion(Titles), Proportion(Team Value), Proportion(Annual Revenue) 三个字段。
球队的成功指数由上述三个字段的数据计算得出。为了更加客观地确定这三种因素在成功指数评价中的权重,我采用了问卷调查的方式,收集到了62份有效答案。根据问卷结果,得到了如下的球队成功指数计算公式:Success Index = 0.4595 x Proportion-Titles + 0.3181 x Proportion-Team Value + 0.2224 x Proportion-Annual Revenue。利用此公式得到Success Index字段。

最终team_data.csv所含字段如下(此处以Dallas Mavericks为样例):
![]()
3.2.2 构建拥有五大联盟球队的城市数据集
第二张数据集为拥有五大联盟球队的城市数据集,命名为selected_city_data.csv。
首先由team_data.csv的City字段经过去重得到selected_city_data.csv的City字段,其中包含了目前拥有五大联盟球队的所有57座城市。
selected_city_data = (team_data['City']).to_frame()
selected_city_data = selected_city_data.drop_duplicates()
selected_city_data = selected_city_data.reset_index(drop=True)从US_2020_census_by_city_density.csv的state, pop_density_km字段中,取City字段中的城市的对应数据,得到State, City Population Density字段。
从US_2020_census_by_state.csv的state_code, 2020_census字段中,取State字段中的州的对应数据,得到State Code, State Population字段。
从US_2020_census_by_city_location.csv的Longitude, Latitude, Population字段中,取City字段中的城市的对应数据,得到Longitude, Latitude, City Population字段。
从US_2019_GDP_by_state.csv的2019字段中,取State字段中的州的对应数据,得到State GDP字段。
为了得到城市人口占所在州总人口的比例的数据,将City Population字段除以State Population字段,得到Population Proportion(City in State) 字段,并将单位转换为百分比。
为了得到所在州人均GDP的数据,将State GDP字段除以State Population字段,得到State GDP Per Capita字段,并将单位由百万美元转换为千美元。
为了得到每座城市拥有五大联盟球队的数量情况,利用team_data.csv中的Team, League, City字段,得到NBA Team, NFL Team, NHL Team, MLB Team, MLS Team字段。
最后为了得到城市的成功指数(此处以Dallas(TX)为样例),采用的计算方法是对该城市拥有的所有球队的成功指数取平均。它的值越高,表明在此处创建球队越有可能获得成功。
dallas_team_data = team_data[(team_data['City'] == 'Dallas')]
dallas_success_index = dallas_team_data['Success Index'].mean()最终selected_city_data.csv所含字段如下(此处以Dallas(TX)为样例):
![]()
3.2.3 构建所有城市数据集(不完整版)
第三张数据集为所有城市数据集,命名为all_city_data.csv。
取US_2020_census_by_city_density.csv的City字段作为all_city_data.csv的City字段,其中包含326座城市(其余城市因缺少数据而不被包括在内)。
补全城市信息的过程与3.2.2中类似,但暂时无法得到城市的成功指数,因此在这一阶段得到的all_city_data.csv是不完整的。
最终all_city_data.csv(incomplete)所含字段如下(此处以Yonkers(NY)为样例):
![]()
3.3 模型构建
本实验中选择训练三次多项式回归模型,在训练过程中,将城市成功指数作为标签,将经度、纬度、城市人口密度、城市人口占所在州总人口的比例、所在州人均GDP这五组数据作为特征。
X = np.array(selected_city_data.loc[:, ['Longitude', 'Latitude', 'City Population Density',
'Population Proportion(City in State)', 'State GDP Per Capita']].values)
y = np.array(selected_city_data.loc[:, ['Success Index']].values)def polynomial_regression_model(X_train, X_test, y_train, y_test):
poly_reg = PolynomialFeatures(degree=3)
poly_X_train = poly_reg.fit_transform(X_train)
poly_X_test = poly_reg.transform(X_test)
model = LinearRegression()
model.fit(poly_X_train, y_train)
y_test_pred = model.predict(poly_X_test)在模型评估方面,均采用两种评价指标:利用mean_squared_error() 函数计算均方误差(MSE),输出值范围为0~+∞ ,越接近0说明模型预测越准确;利用模型自带的评估函数输出评估结果,输出值范围为0~1 ,越接近1说明模型性能越佳。模型评估结果如下:
![]()
可以看出,三次多项式回归模型拟合效果非常理想,所以接下来选择此模型作为预测模型。
3.4 模型预测
3.4.1 补全所有城市数据集
首先将all_city_data.csv中的Longitude, Latitude, City Population Density, Population Proportion(City in State), State GDP Per Capita字段作为特征数据,利用预测模型得到城市成功指数的预测结果。
X = np.array(all_city_data.loc[:, ['Longitude', 'Latitude', 'City Population Density',
'Population Proportion(City in State)', 'State GDP Per Capita']].values)
poly_reg = PolynomialFeatures(degree=3)
poly_X = poly_reg.fit_transform(X)
y_pred = model.predict(poly_X)通过查看预测结果得知:预测结果中含有负数,为了方便后续的数据可视化与数据分析,需对预测结果进行最大最小归一化处理,处理后统一乘以10;Anchorage(AK)这座城市的预测成功指数过偏,对最大最小归一化处理有较大的不良影响,所以去除这个城市。
all_city_data.drop(all_city_data[(all_city_data['City'] == 'Anchorage')].index, inplace=True)
all_city_data = all_city_data.reset_index(drop=True)min_max_scaler = MinMaxScaler()
predicted_success_index = min_max_scaler.fit_transform(y_pred)
all_city_data['Predicted Success Index'] = predicted_success_index * 10在补全Predicted Success Index字段后,得到了完整的all_city_data.csv。all_city_data.csv所含字段如下(此处以Yonkers(NY)为样例):
![]()
3.4.2 分析大卫·贝克汉姆的决策
实验引言中曾提到,2018年,大卫·贝克汉姆在迈阿密创建了国际迈阿密足球俱乐部,球队于2020年正式加入美国职业足球大联盟。可以利用预测模型对此决策进行分析。
首先在还未拥有MLS球队的城市中,查看迈阿密的排名。
test_1 = all_city_data.drop(all_city_data[(all_city_data['MLS Team'] > 0)].index)
test_1 = test_1.reset_index(drop=True)
print("%d/%d" % (test_1[test_1['City'] == 'Miami'].index.tolist()[0] + 1, test_1.shape[0]))输出结果为:128/303。
再在还未拥有MLS球队且人口超过40万的城市中,查看迈阿密的排名。
test_2 = test_1.drop(test_1[(test_1['City Population'] < 400000)].index)
test_2 = test_2.reset_index(drop=True)
print("%d/%d" % (test_2[test_2['City'] == 'Miami'].index.tolist()[0] + 1, test_2.shape[0]))输出结果为:14/33。
根据预测模型,无论是在还未拥有MLS球队的所有城市中,还是在还未拥有MLS球队的大型城市中,迈阿密都排名较为靠前,所以在迈阿密创建一支MLS球队是中上等的决策。
3.4.3 分析勒布朗·詹姆斯的决策
实验引言中也曾提到,勒布朗·詹姆斯在未来想要拥有一支位于拉斯维加斯的NBA球队。同样可以利用预测模型对此决策进行分析。
首先在还未拥有NBA球队的城市中,查看拉斯维加斯的排名。
test_3 = all_city_data.drop(all_city_data[(all_city_data['NBA Team'] > 0)].index)
test_3 = test_3.reset_index(drop=True)
print("%d/%d" % (test_3[test_3['City'] == 'Las Vegas'].index.tolist()[0] + 1, test_3.shape[0]))输出结果为:135/297。
再在还未拥有NBA球队且人口超过40万的城市中,查看拉斯维加斯的排名。
test_4 = test_3.drop(test_3[(test_3['City Population'] < 400000)].index)
test_4 = test_4.reset_index(drop=True)
print("%d/%d" % (test_4[test_4['City'] == 'Las Vegas'].index.tolist()[0] + 1, test_4.shape[0]))输出结果为:15/25。
根据预测模型,无论是在还未拥有NBA球队的所有城市中,还是在还未拥有NBA球队的大型城市中,拉斯维加斯都排名较为靠前,并且考虑到拉斯维加斯目前仅拥有一支五大联盟球队,所以在拉斯维加斯创建一支NBA球队是中上等的决策。
3.5 数据可视化与数据分析
在构建了team_data.csv, selected_city_data.csv, all_city_data.csv这三张数据集后,我基于DataEase开源数据可视化分析工具进行了数据可视化与数据分析,并制作了仪表板(包含Web端和移动端)。
仪表板共享链接地址:http://student.dataease.fit2cloud.com/link/KBQ5sdjj。
仪表板演示视频网址:https://www.bilibili.com/video/BV1Bb4y1P7LB。
3.5.1 仪表板总览
Web端:
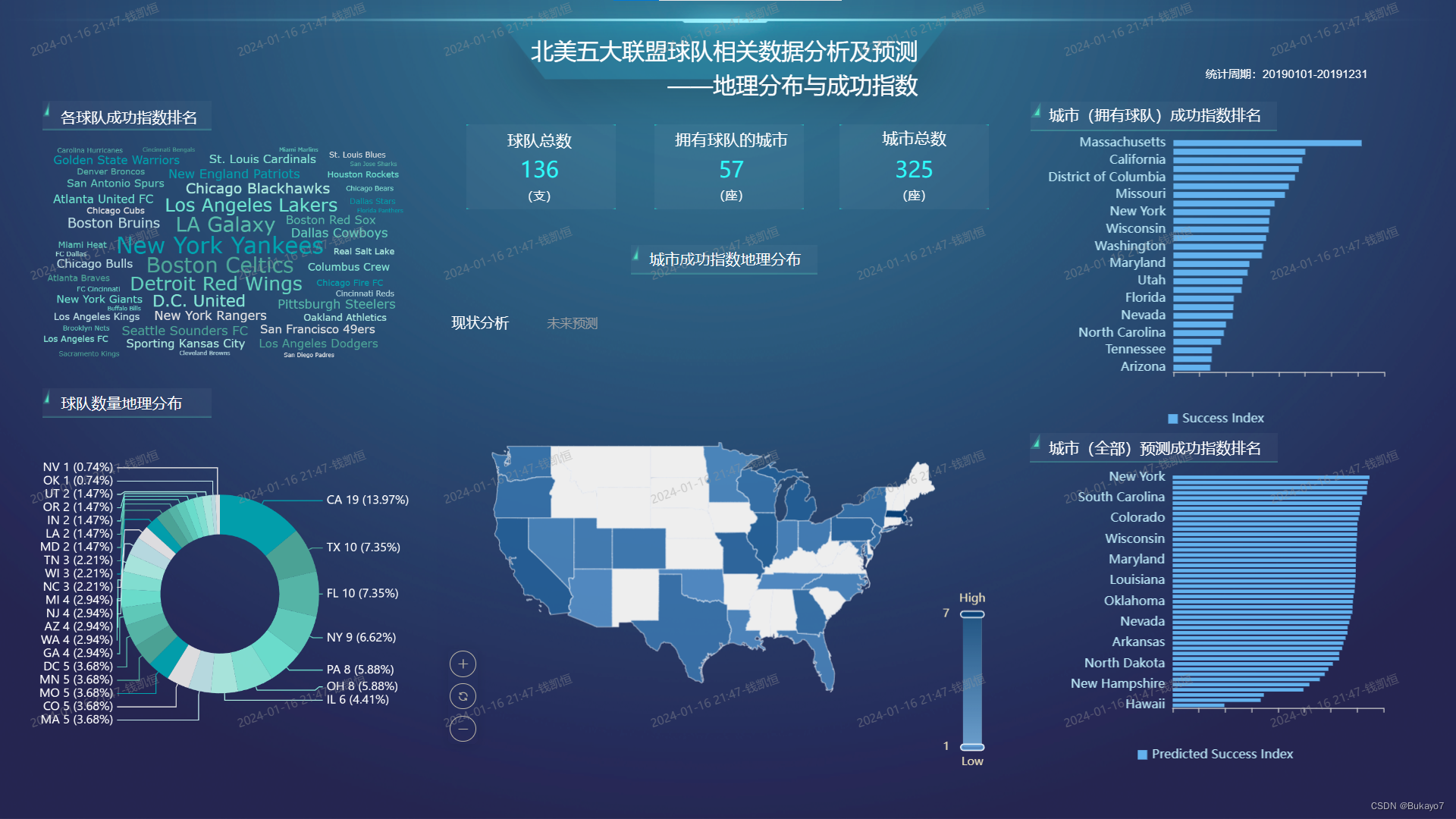
移动端:

3.5.2 视图一:各球队成功指数排名
利用team_data.csv,将Team字段作为维度,Success Index字段作为指标,调用AntV图库绘制各球队成功指数排名的词云图。在词云图中,球队的成功指数越高,其球队名显示的字体就越大。

根据词云图可以直观地看出,New York Yankees, Boston Celtics, LA Galaxy这三支球队在成功指数层面位居前列。
3.5.3 视图二:球队数量地理分布
利用selected_city_data.csv,将State Code字段作为维度,Team Number字段作为指标,调用AntV图库绘制五大联盟球队地理分布的环形图。指标的汇总方式选择“求和”,排序选择“降序”,这样可以使得环形图看上去更加整齐。由于City字段可以看作State字段的子字段,所以可以在原有基础上从州层级钻取到城市层级。应用了钻取技术后,当用户点击环形的某一个部分(对应一个州,如左图),视图会切换到更低层级,展示该州对应的所有城市的相关数据(如右图);如果想返回更高层级,仅需点击左下方的“全部”字样。在环形图中,州/城市拥有的五大联盟球队数量越多,其所占部分的角度就越大,标签上展示的占比也会越大。
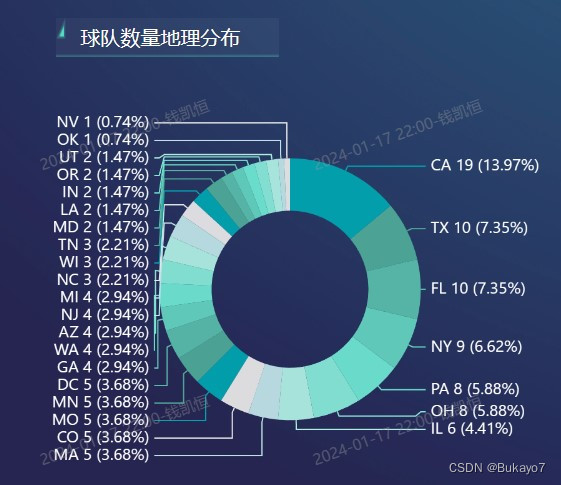
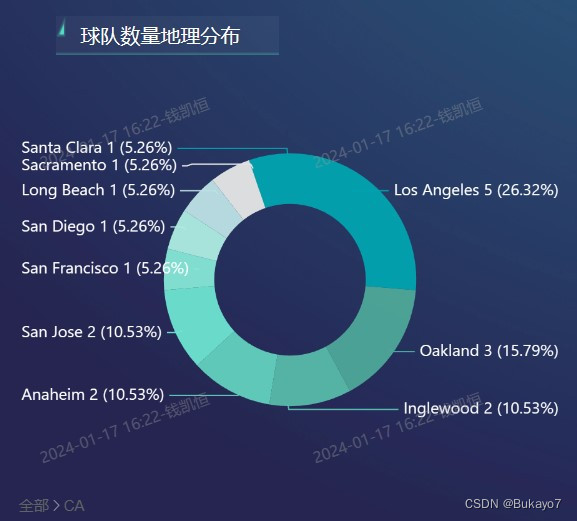
根据环形图可以直观地看出,California(CA)州拥有的五大联盟球队数量最多;以California(CA)州为例,Los Angeles、Oakland这两座城市拥有的五大联盟球队数量最多。
3.5.4 视图三:城市(拥有球队)成功指数地理分布
利用selected_city_data.csv,将State字段作为维度,Success Index字段作为指标,调用ECharts图库绘制城市(拥有球队)成功指数地理分布的地图。指标的汇总方式选择“求平均值”。在地图中,州的成功指数越高,其对应区域的颜色越深。(由于DataEase提供的气泡地图无法根据经纬度绘制气泡,也未提供美国各州的地图,所以此处实际上是以州为单位比较成功指数)
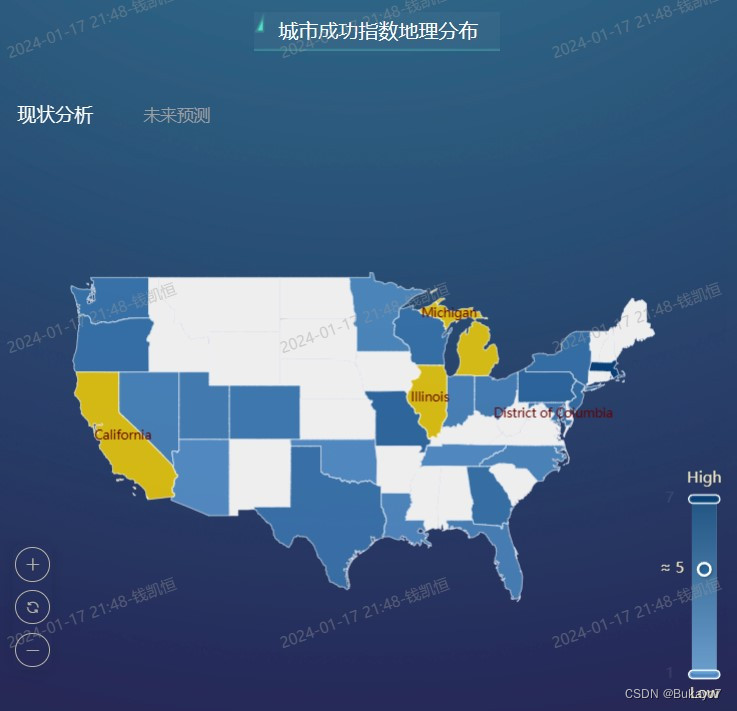
根据地图可以直观地看出,在城市成功指数层面,东北部大西洋沿岸城市群、五大湖地区、加利福尼亚州等地位居前列;西北部、得克萨斯州也拥有不少高成功指数的城市;中部和东南部地区排名靠后;城市成功指数的地理分布总体呈现加州、得州、东北部地区“三足鼎立”的状态。
3.5.5 视图四:城市(全部)预测成功指数地理分布
利用all_city_data.csv,将State字段作为维度,Predicted Success Index字段作为指标,调用ECharts图库绘制城市(全部)预测成功指数地理分布的地图。指标的汇总方式选择“求平均值”。在地图中,州的预测成功指数越高,其对应区域的颜色越深。(由于DataEase提供的气泡地图无法根据经纬度绘制气泡,也未提供美国各州的地图,所以此处实际上是以州为单位比较预测成功指数)
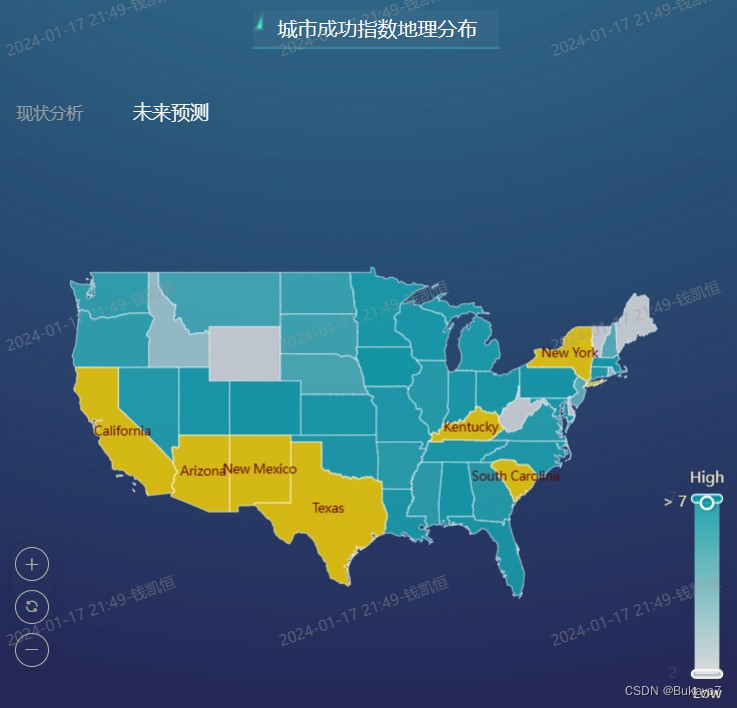
根据地图可以直观地看出,在城市预测成功指数层面,东北部大西洋沿岸城市群、西南部、肯塔基州、南卡罗莱纳州位于第一梯队;中部偏南地区、东南部位于第二梯队;现状良好的五大湖地区的大部分城市排名中游,预计未来发展潜力不足;西北部、中部偏北地区排名靠后,尚处于“体育荒漠”之中,有待开发。
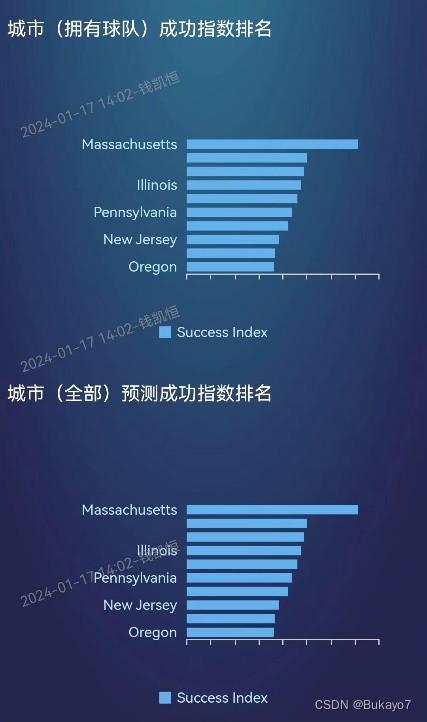
3.5.6 视图五:城市(拥有球队)成功指数排名
利用selected_city_data.csv,将State字段作为维度,Success Index字段作为指标,调用ECharts图库绘制城市(拥有球队)成功指数排名的横向柱状图。指标的汇总方式选择“求平均值”,排序选择“降序”,结果展示选择展示10条数据,这样可以只显示成功指数排名前十的州/城市(这些是用户重点关注的对象),并且使得横向柱状图看上去更加清晰。由于City字段可以看作State字段的子字段,所以可以在原有基础上从州层级钻取到城市层级。应用了钻取技术后,当用户点击某一个柱体(对应一个州,如左图),视图会切换到更低层级,展示该州对应的所有城市的相关数据(如右图);如果想返回更高层级,仅需点击左下方的“全部”字样。在横向柱状图中,州/城市的成功指数越高,其对应柱体越长。
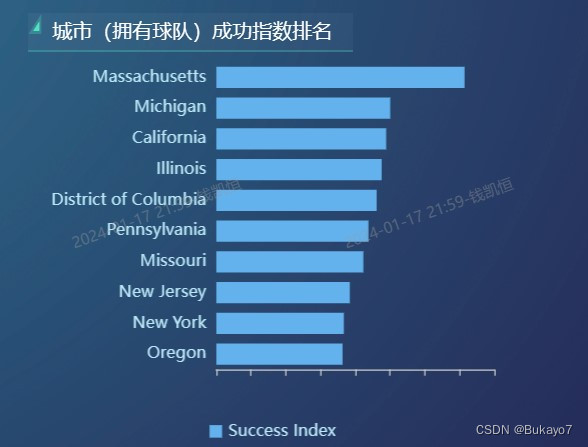
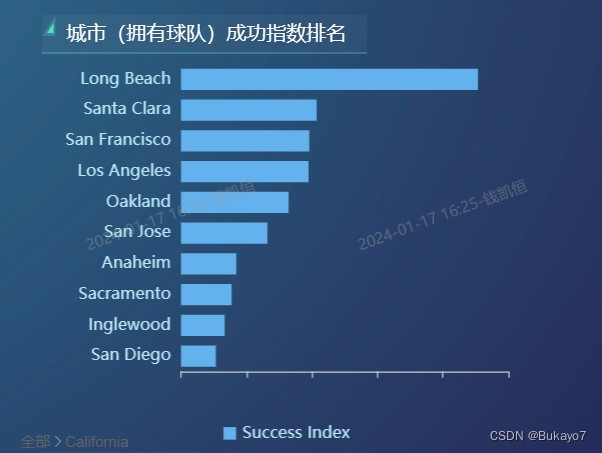
根据横向柱状图可以直观地看出,在城市成功指数层面,马萨诸塞州、密歇根州、加利福尼亚州等地位居前列;伊利诺伊州、哥伦比亚特区、宾夕法尼亚州等地也拥有不少高成功指数的城市;以加利福尼亚州为例,Long Beach、Santa Clara、San Francisco、Los Angeles等城市的成功指数较高。
3.5.7 视图六:城市(全部)预测成功指数排名
利用all_city_data.csv,将State字段作为维度,Predicted Success Index字段作为指标,调用ECharts图库绘制城市(全部)预测成功指数排名的横向柱状图。指标的汇总方式选择“求平均值”,排序选择“降序”,结果展示选择展示10条数据,这样可以只显示成功指数排名前十的州/城市(这些是用户重点关注的对象),并且使得横向柱状图看上去更加清晰。由于City字段可以看作State字段的子字段,所以可以在原有基础上从州层级钻取到城市层级。应用了钻取技术后,当用户点击某一个柱体(对应一个州,如左图),视图会切换到更低层级,展示该州对应的所有城市的相关数据(如右图);如果想返回更高层级,仅需点击左下方的“全部”字样。在横向柱状图中,州/城市的预测成功指数越高,其对应柱体越长。

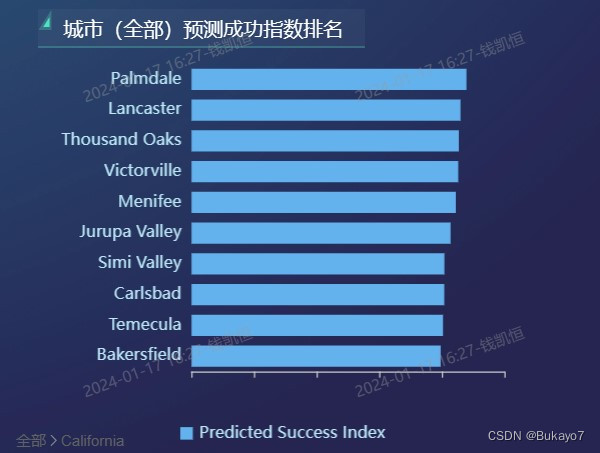
根据横向柱状图可以直观地看出,在城市预测成功指数层面,纽约州、肯塔基州、新墨西哥州、加利福尼亚州等地位居前列;南卡罗莱纳州、得克萨斯州、亚利桑那州等地也拥有不少高成功指数的城市;以加利福尼亚州为例,Palmdale、Lancaster、Thousand Oaks、Victorville等城市的预测成功指数较高。
3.5.8 选项卡(Tab组件)
Tab组件支持放置视图,可以通过设置多个Tab以展示多个视图,并且可以通过启用轮播功能定时切换当前播放Tab。在仪表板中使用Tab组件将相似或相关联的视图划分到不同的Tab,不仅可以节省大量空间,还能使得仪表板的组织结构清晰,提升用户体验。
当用户点击“现状分析”字样,将可以查看城市(拥有球队)成功指数地理分布的地图(如左图);当用户点击“未来预测”字样,将可以查看城市(全部)预测成功指数地理分布的地图(如右图)。
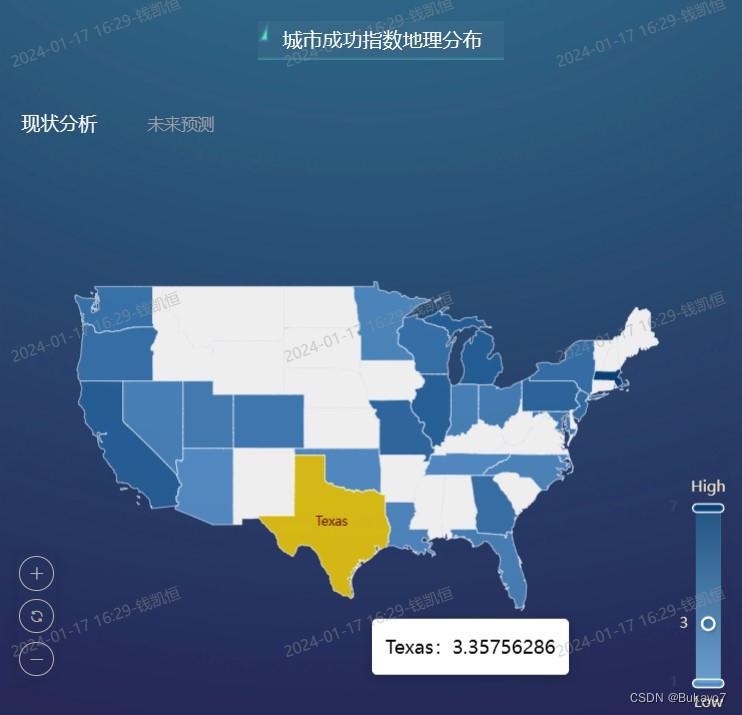
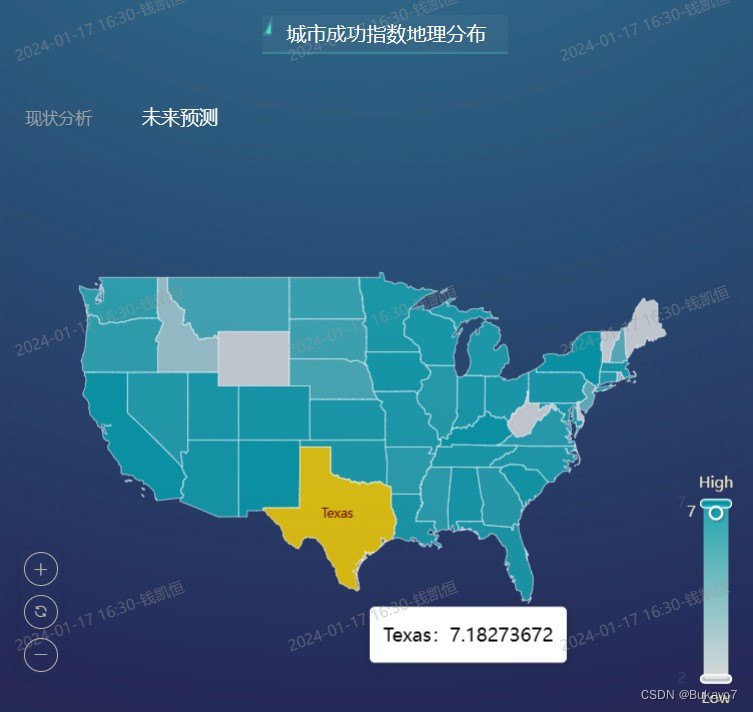
4. 实验评价
4.1 优点和创新点
4.1.1 数据来源产生时间的统一程度高
在数据采集时我非常关注数据来源的产生时间。由于受到疫情影响,本实验中需要用到的许多数据从2020年开始显示出异常波动,其中球队有关数据尤为明显。所以我在采集球队有关数据时统一采用2019年度数据,州GDP数据也来自2019年度;因数据来源有限,人口有关数据统一采用2020年度数据,并且在实验中采用取占比的方法来最小化异常影响。这样的数据采集标准对于训练出更适用于后疫情时代的预测模型具有重要意义。
4.1.2 仪表板数据可视化分析的效果好
本实验中采用仪表板的形式实现数据可视化分析,使用了DataEase这个强大的开源数据可视化分析工具来制作仪表板。仪表板具有实时性、直观性、交互性等特点,将多个数据源或多个关键指标集中展示在一个页面上,支持多维度的数据分析,允许用户实时监控数据的变化,并提供用户交互功能,从而帮助用户更好地理解数据、发现趋势、做出决策。DataEase提供了丰富的视图组件和样式组件,并提供了数据钻取等功能,同时支持Web端和移动端,大幅提升了数据可视化分析的效果。
4.1.3 实验过程及方法的可迁移性强
本实验中研究的地理区域为美国,球队来自五大联盟,但实验过程及方法对于全世界其他地区和当地球队的研究同样具有借鉴意义。在将本实验的实验过程及方法迁移到其他地区时,可以根据所研究地区的具体情况,对地理信息中的地理影响因子进行相应修改,构建更加适应当地情况的预测模型。
4.2 缺点和不足
4.2.1 地理影响因子的选择不够全面
由于数据来源有限,本实验中选取了以下五个地理影响因子:经度、纬度、城市人口密度(人/平方千米)、城市人口占所在州总人口的比例、所在州人均GDP(千美元)。这些地理影响因子都具有很强的代表性,但仍然不够全面。若能采集到有关数据,以下几个地理影响因子同样值得考虑:城市体育产业规模、城市人口中五大联盟相关人员(从业者、球迷)所占比例、城市高校体育发展情况等。
4.2.2 数据可视化效果仍有提升空间
DataEase目前在ECharts图库中提供了气泡地图,但却无法根据经纬度绘制气泡,只能根据单一维度(如城市)绘制气泡。同时,在与开发人员交流尝试后,选择上传的美国地图是以州为单位的GeoJson数据,因为若上传以城市为单位的GeoJson数据,会导致地图区域分割得过于细密且无法处于视图正中位置,严重影响观感。所以目前无法根据单一的城市维度绘制气泡,因此我只好放弃使用气泡地图,转而使用地图。仪表板中绘制的两幅地图实际上均是在州的层级上比较(预测)成功指数,这其实就导致数据并没有完全深入地被利用,也没有取得在城市的层级上比较(预测)成功指数的预期效果。
5. 后续工作
5.1 提升数据可视化效果
为了取得在城市的层级上比较(预测)成功指数的预期效果,主要有两种方法。
第一种是在气泡地图中提供根据经纬度绘制气泡的功能,这非常依赖ECharts的特性,如果ECharts并未提供相关功能,那么开发人员也爱莫能助。
第二种是在现有基础上继续上传美国每个州各自以城市为单位的GeoJson数据,这样就能支持数据钻取,此时仅需选择绘制地图,预期效果如下图所示(图片源自官方示例):

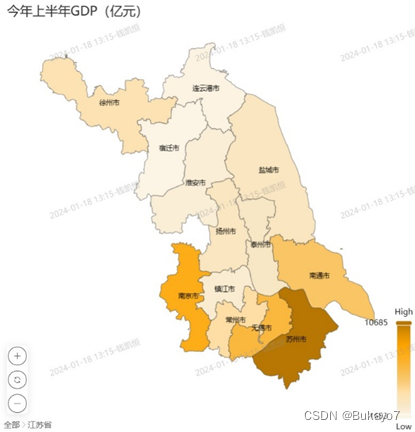
但通过比较可以发现,如果两种方法均可行的话,第一种方法更优,因为可以提供全国城市比较的直观效果,而第二种方法只能提供全国州比较和州内城市比较的欠直观效果。
5.2 研究世界其他地区和当地球队
在研究对象的选择上,转向世界其他地区和当地球队。可以直接将本实验的实验过程及方法进行迁移,并根据所研究地区的具体情况,进行相应修改,构建更加适应当地情况的预测模型。
例如中国就是非常适合开展类似实验研究的地区。中国拥有中国足球协会超级联赛、中国男子篮球职业联赛、中国排球超级联赛、中国乒乓球俱乐部超级联赛、中国羽毛球俱乐部超级联赛等职业体育联赛,参赛球队众多,遍布全国各地。在地理区划的选择上,可以采用地级市、地区、自治州、盟这些行政地位相同的区划。然后采用类似的实验过程及方法,构建预测模型,得到预测结果。这样的实验研究对于中国体育产业的发展具有一定意义。
6. 实验总结
6.1 实验结论
根据本实验中构建的预测模型对于未来美国城市的成功指数的预测结果,可以在球队选址的决策方面,向未来潜在的五大联盟球队创建者提出以下几点建议:
- Yonkers (NY), Palmdale (CA), Albuquerque (NM)这三座城市是首选项;
- 东北部大西洋沿岸城市群、西南部、肯塔基州、南卡罗莱纳州位于第一梯队;
- 中部偏南地区、东南部位于第二梯队;
- 现状良好的五大湖地区的大部分城市排名中游,预计未来发展潜力不足;
- 西北部、中部偏北地区排名靠后,尚处于“体育荒漠”之中,有待开发。
6.2 版本管理
我使用git作为版本管理工具,方便回溯到项目的任何历史版本,使得项目进展更加容易和高效。
GitHub仓库链接:https://github.com/KaihengQian/Cloud-Computing.git。
6.3 技术分享
我已公开仪表板并将其演示视频发布在B站上,在3.5节中也已提到。
仪表板共享链接地址:http://student.dataease.fit2cloud.com/link/KBQ5sdjj。
仪表板演示视频网址:https://www.bilibili.com/video/BV1Bb4y1P7LB。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









