



 该博客使用Python对Kaggle上的video游戏销售数据进行分析,通过折线图展示了不同地区的销售量随年份变化,利用柱形图对比了游戏类型、出版商和游玩平台的全球销量,并通过饼图呈现了游戏类型的销售比例。数据指标包括销售排名、游戏名称、平台、年份、类型、出版商和各地区销量等。
该博客使用Python对Kaggle上的video游戏销售数据进行分析,通过折线图展示了不同地区的销售量随年份变化,利用柱形图对比了游戏类型、出版商和游玩平台的全球销量,并通过饼图呈现了游戏类型的销售比例。数据指标包括销售排名、游戏名称、平台、年份、类型、出版商和各地区销量等。
python数据分析可视化项目——video游戏销售量
数据来源
本项目数据来源于kaggle数据集,地址https://www.kaggle.com/datasets/gregorut/videogamesales, 大小390kb。
- 数据指标包括:
- Rank - 销售量排名
- Name - 游戏名称
- Platform - 游玩平台
- Year - 发行年份
- Genre - 游戏类型
- Publisher - 出版商
- NA_Sales - 北美销售量millions
- EU_Sales - 欧洲销售量millions
- JP_Sales - 日本销售量millions
- Other_Sales - 其他地区销售量millions
- Global_Sales - 总销售量
可视化
数据准备
import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv('data\\vgsales.csv',)
print(data.columns)
print(data.head(5))
游戏出版年份和销量统计——折线图
# 按年份分组、排序
data = data.groupby("Year")
data = data.sum().sort_values("Year",ascending=False)
print(data.head(5))
fig = plt.figure()
ax1 = fig.add_subplot(111)
ax1.plot(data.index,data["Global_Sales"],color="black",label="Global_Sales")
ax1.plot(data.index,data["NA_Sales"],color="blue",alpha=0.9,label="NA_Sales")#透明度
ax1.plot(data.index,data["EU_Sales"],color="yellow",label='EU_Sales')
ax1.plot(data.index,data["JP_Sales"],color="pink",label="JP_Sales")
ax1.set_xlabel("发行年份")
ax1.set_ylabel("销售量")
ax1.legend()
plt.savefig('image/mplot.png')
plt.show()

lst_genre = list(set(data["Genre"].values))
print(lst_genre)
data = data.groupby(["Year","Genre"]).sum()
print(type(data))
print(data.head(5))
data = data.reset_index()
fig, axrr = plt.subplots(3,4)
ax1 = axrr[0][0]
print(type(ax1))
print(data.head(50))
for i in range(3):
for j in range(4):
ax = axrr[i][j]
ax.plot(data[data["Genre"]==lst_genre[i+j]]["Year"],
data[data["Genre"]==lst_genre[i+j]]["Global_Sales"],
label=lst_genre[i+j])
ax.set_xlabel("Year")
ax.set_ylabel("Global_Sales")
ax.legend(loc='upper left')
fig.suptitle("游戏类型的销售量时间曲线")
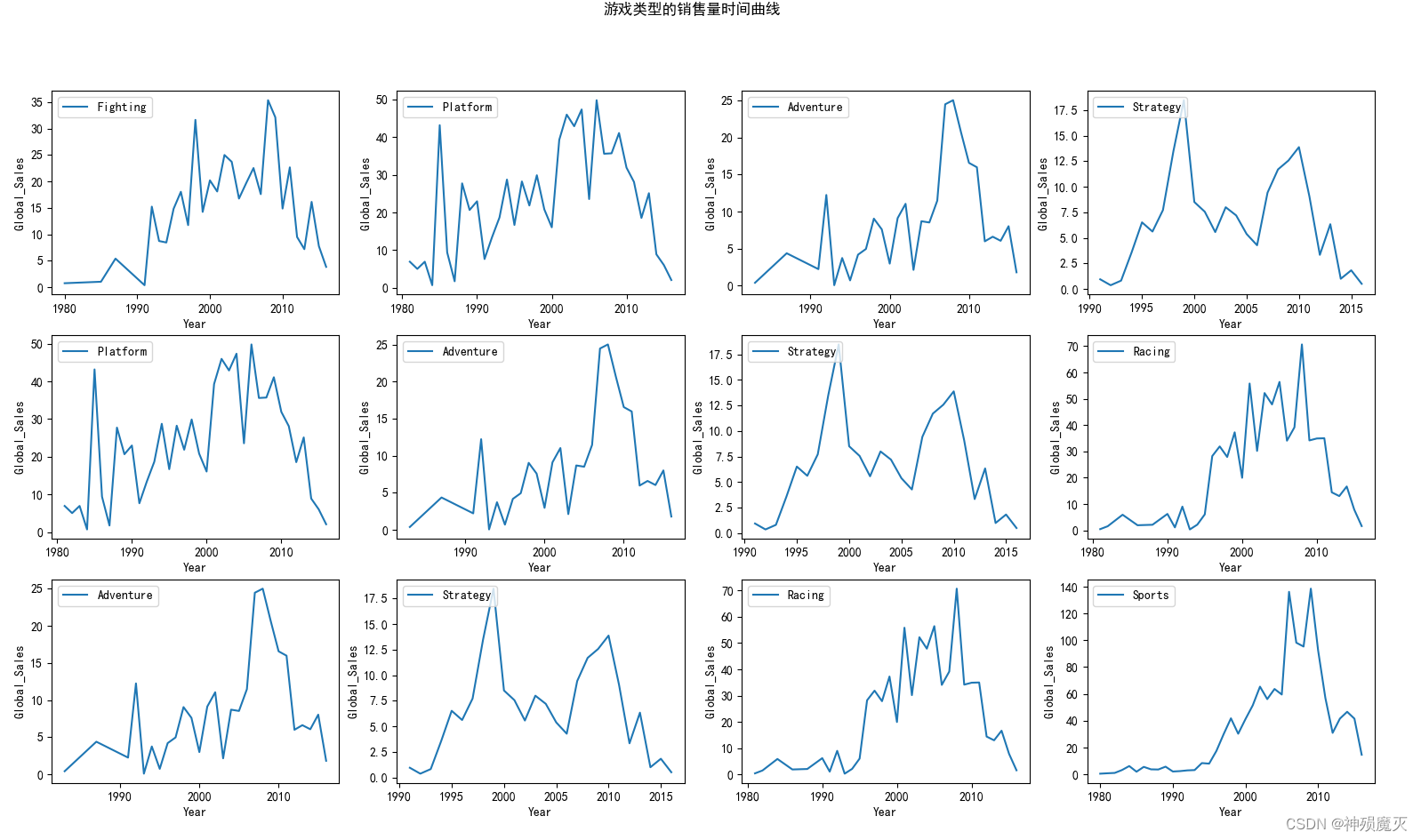
游戏类型、出版商、游玩平台销量统计——柱形图
dataPla = data.groupby("Platform")
dataPla = dataPla.sum().sort_values("Global_Sales",ascending=False)
# dataPla = dataPla[dataPla['Global_Sales']>100]
dataPla = dataPla[:10]
dataPub = data.groupby("Publisher")
dataPub = dataPub.sum().sort_values("Global_Sales",ascending=False)
dataPub = dataPub[dataPub['Global_Sales']>100]
dataPub = dataPub[:10]
dataGen = data.groupby("Genre")
dataGen = dataGen.sum().sort_values("Global_Sales",ascending=False)
dataGen = dataGen[:10]
print(data.head(5))
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
fig = plt.figure()
ax1 = fig.add_subplot(311)
ax2 = fig.add_subplot(312)
ax3 = fig.add_subplot(313)
ax1.bar(dataPla.index,dataPla['Global_Sales'])
ax2.bar(dataPub.index,dataPub['Global_Sales'])
ax3.bar(dataGen.index,dataGen['Global_Sales'])

游戏类型比例——饼图
plt.pie(dataGen['Global_Sales'],labels=dataGen.index,autopct="%.3f%%")
plt.savefig('image/mpie.png')

先做这些 ——2022.6.11

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









