







lesson11 Data Block API, genericoptimizer
- 07a_lsuv.ipynb
- 初始化的方式:LSUV
- 08_data_block.ipynb
- 09_optimizers.ipynb
- 09b_learner.ipynb
- 09c_add_progress_bar.ipynb
- 10_augmentation.ipynb
- 10b_mixup_label_smoothing.ipynb
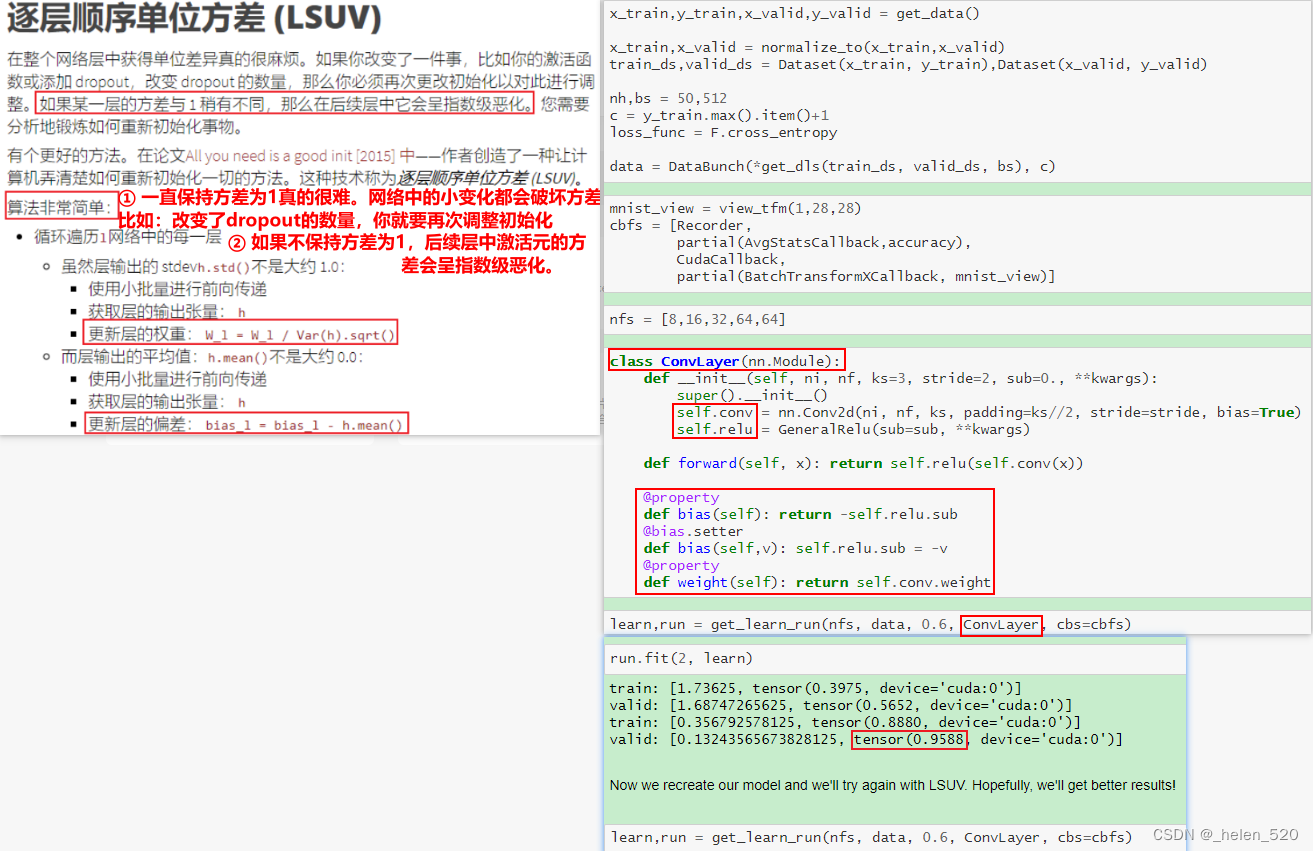
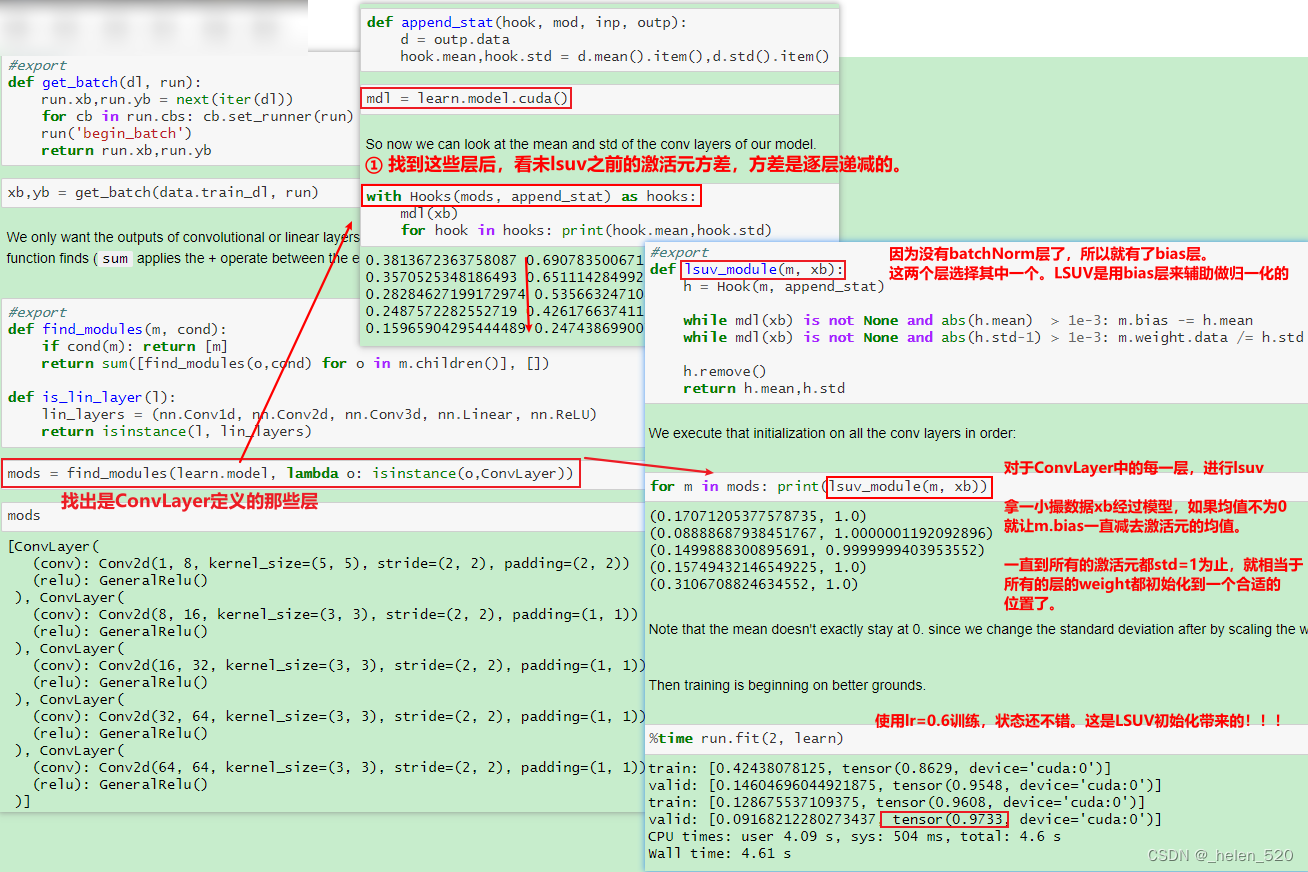
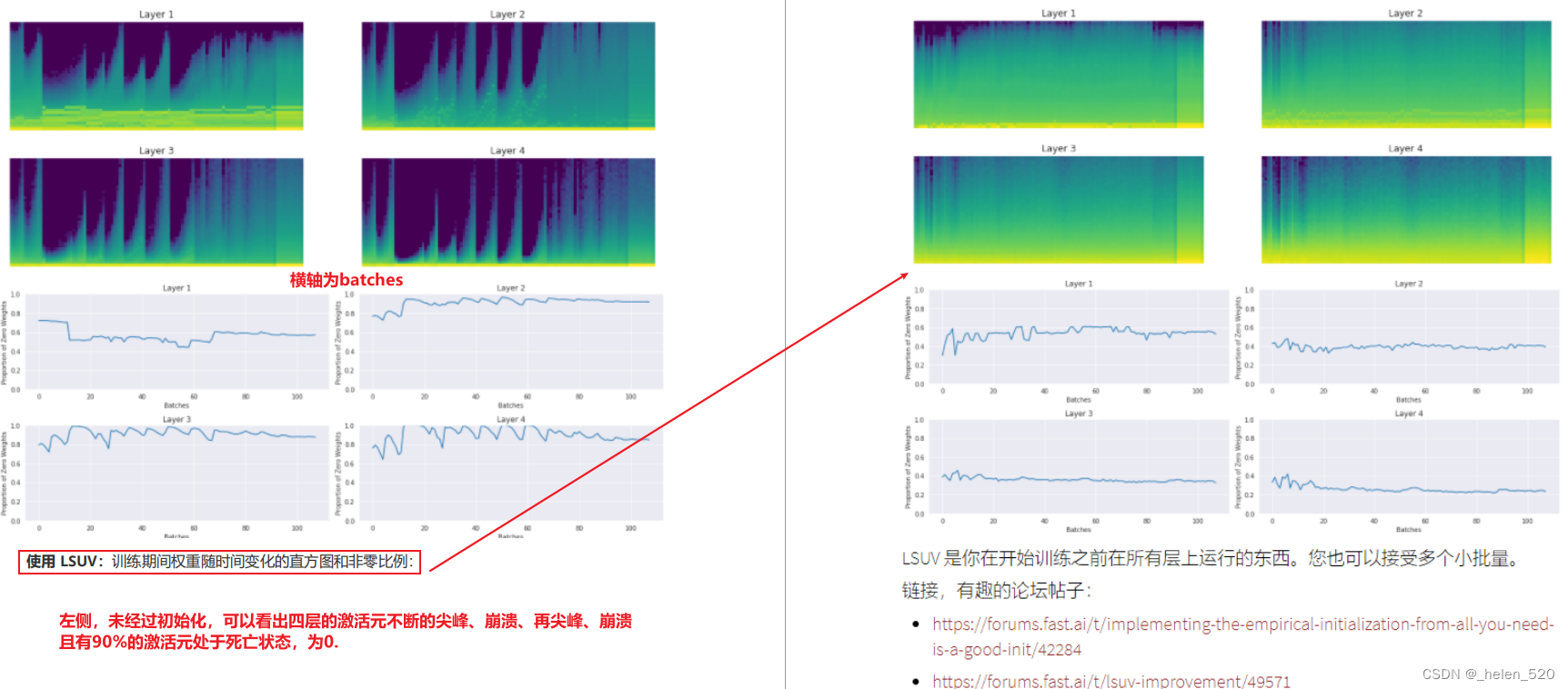
1. LSUV 另一种初始化技术:逐层序列化单位方差
- 这种初始化的好处:可以不假思索的初始化任何神经网络,不用考虑是否有ReLU或者dropout。我们可以很轻松的对复杂和特别深层的网络架构训练。这是fastai初始化你的神经网络的方法,这不是数学,不需要思考,只需要一直while循环。
2. DataBlock API
(一)fastai1.0.61库 debug & datablock API 数据接口__helen_520的博客-CSDN博客_fastai库 中针对DataBlock已经有过介绍了。
3. 新的CNN模型
5个epoch训练后,imagenette的valid_acc=73.6%,官网上显示为85% best。还可以再进一步优化。
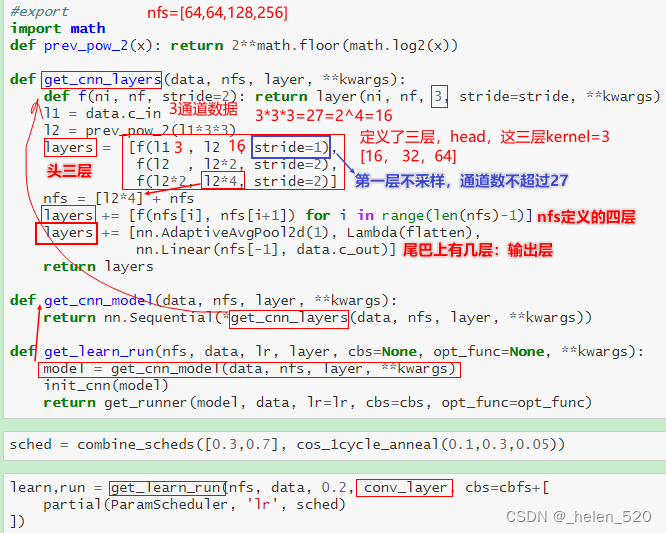
4. Optimizer 优化
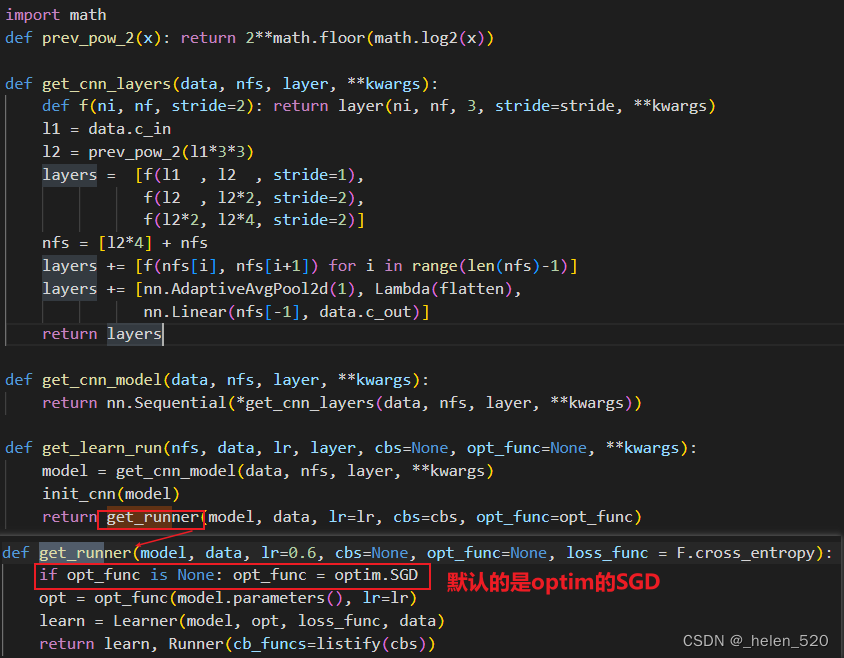
Optimizer初始化 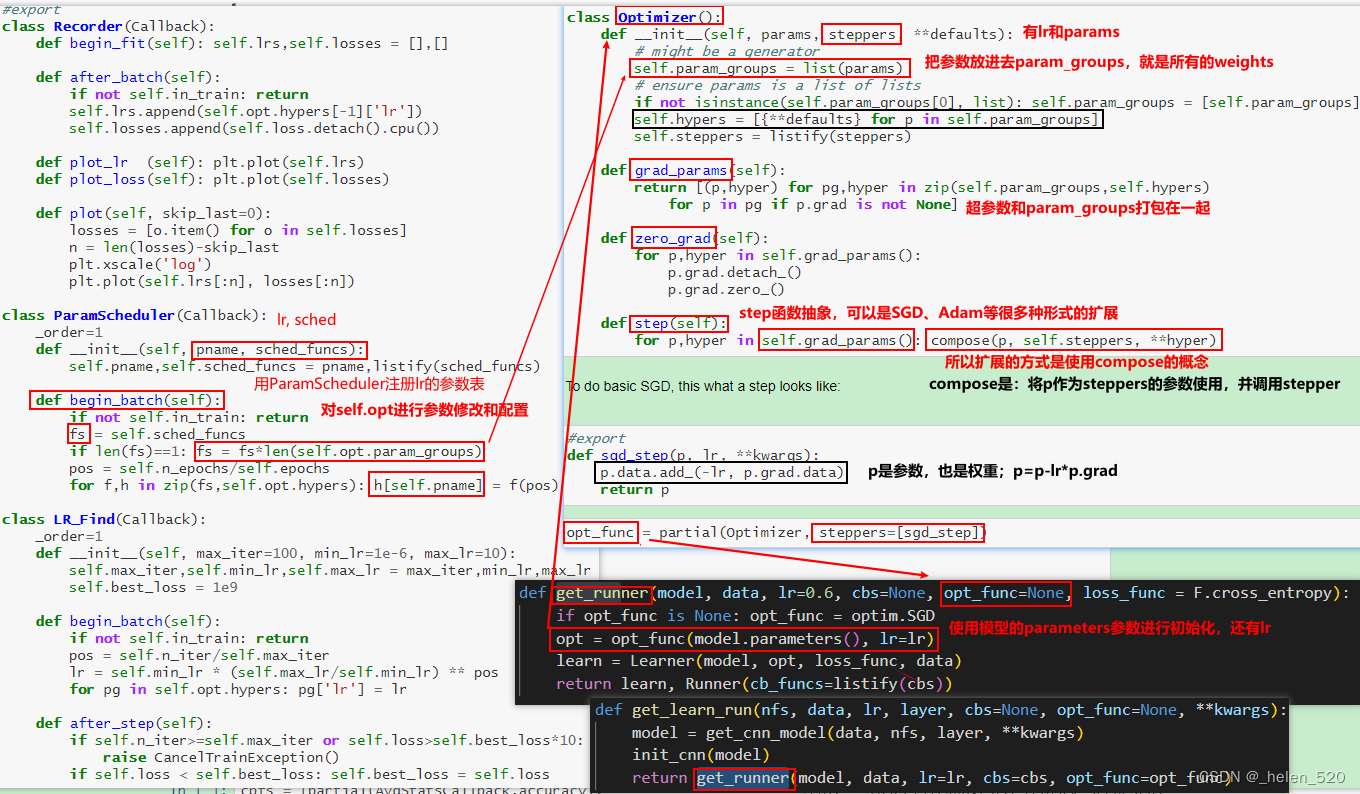
5. Weight decay 权重衰减
与l2正则化相关:KCF原理学习__helen_520的博客-CSDN博客
- 挑选数据的PCA的成分最终的方向。自动地进行了模型选择。
- weight decay与l2正则化的区别如下:

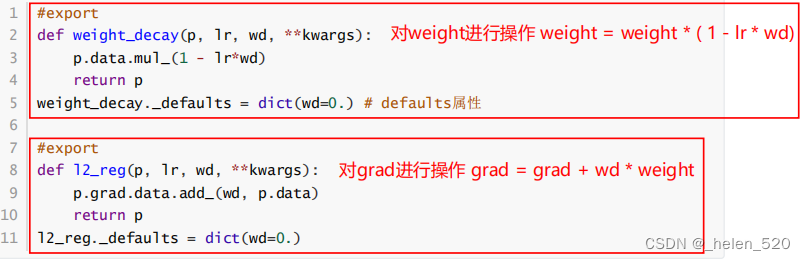
在先做momentum,在做weight decay,会一直多加入一个衰减因子的污染。这个是需要注意的。


Weight decay + Batch Norm的效果:批量归一化+权重衰减
Momentum动量的工作机制

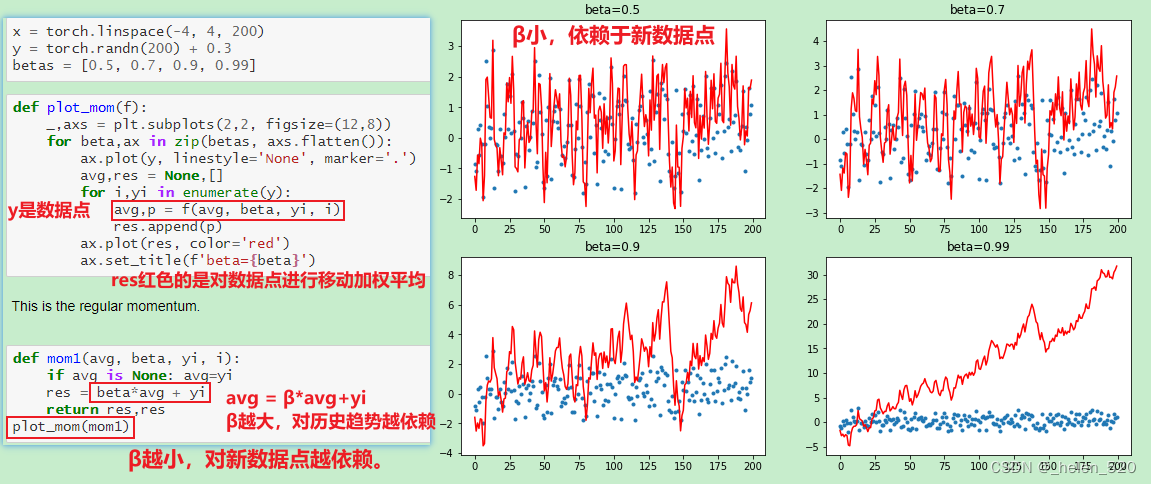
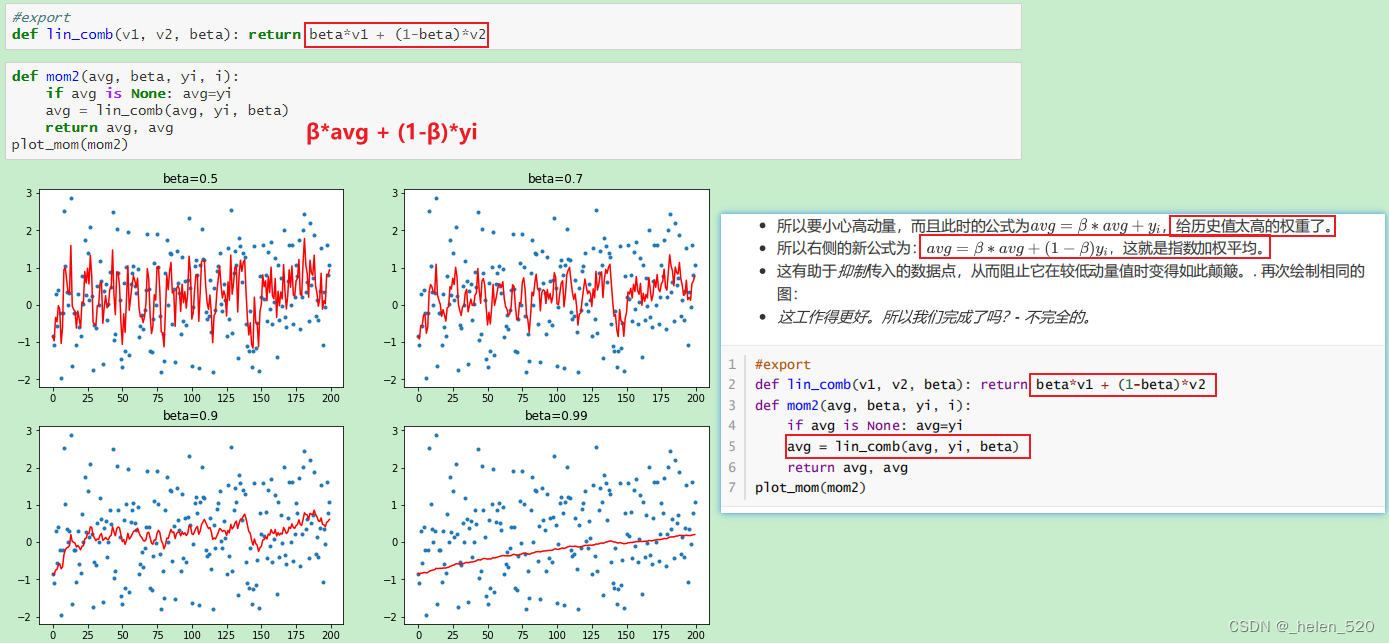
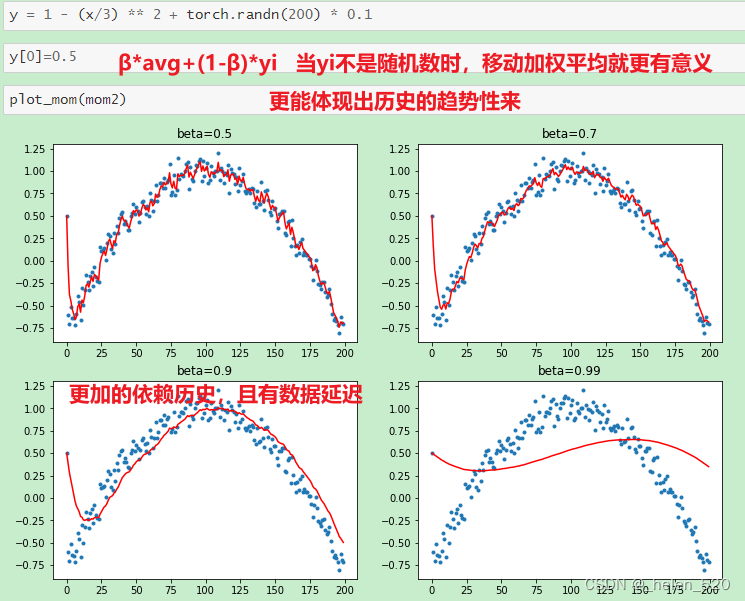
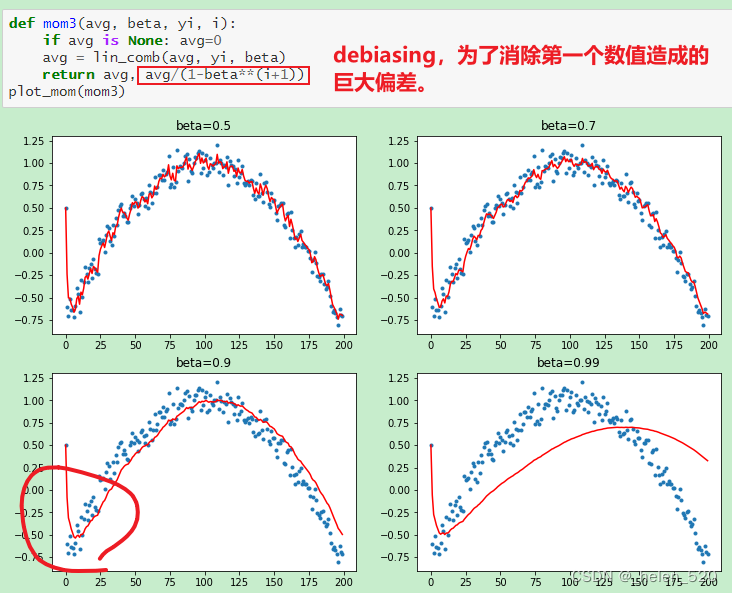
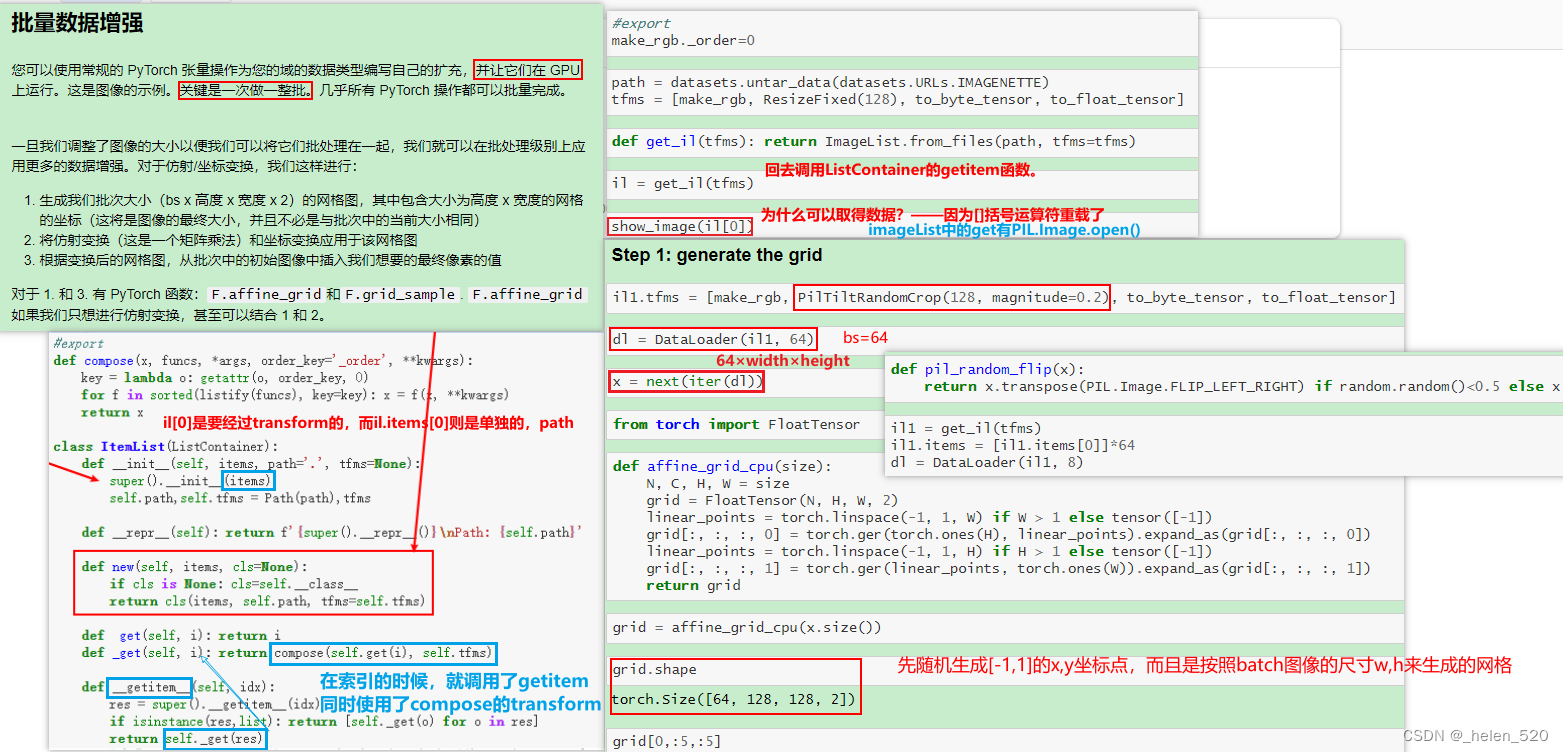
6. Data Augumentation 数据增强
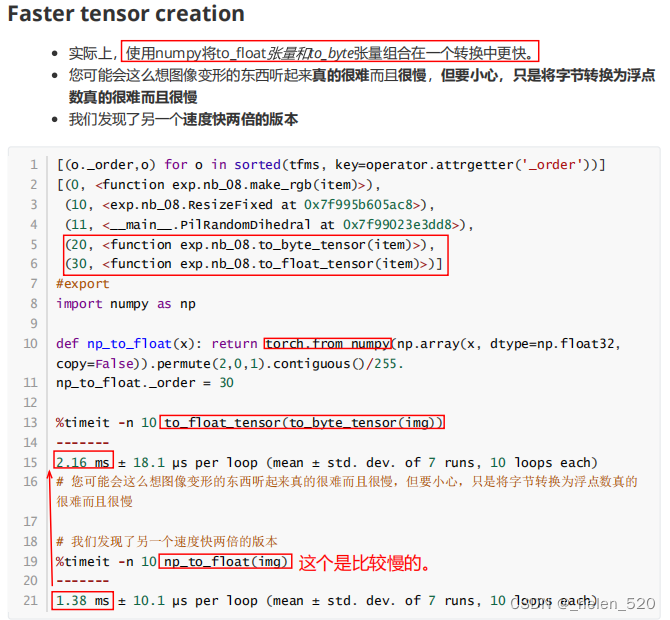
rgb、resize、byte_tensor、float_tensor。
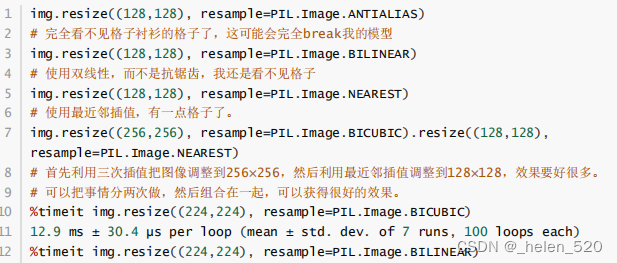
bilinear会丢失纹理。img.resize((), resamplt=PIL.Image.BILINEAR)
-
Reisize method:ANTIALIAS、BILINEAR、NEAREST、BICUBIC
- Flippling, rotate, cropping
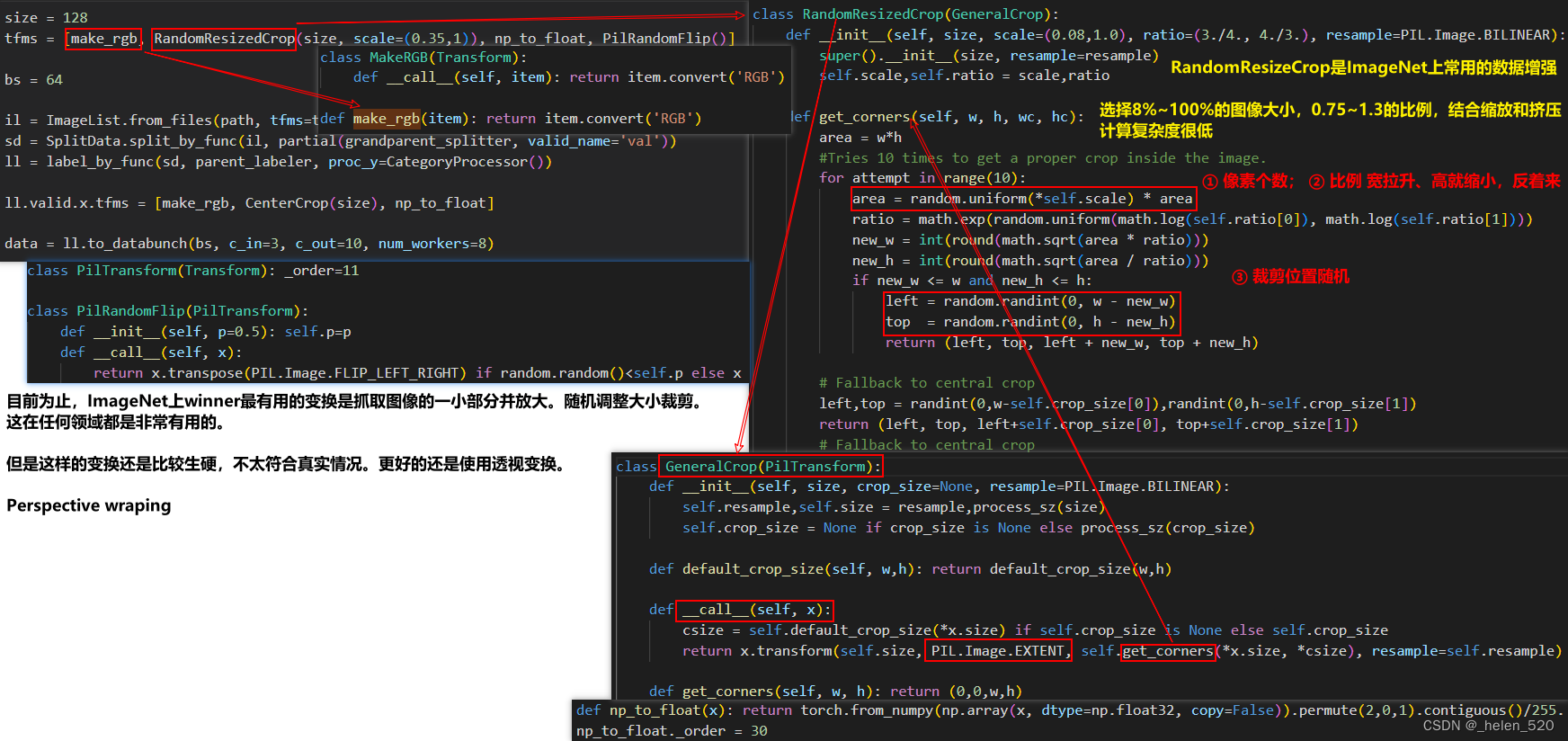
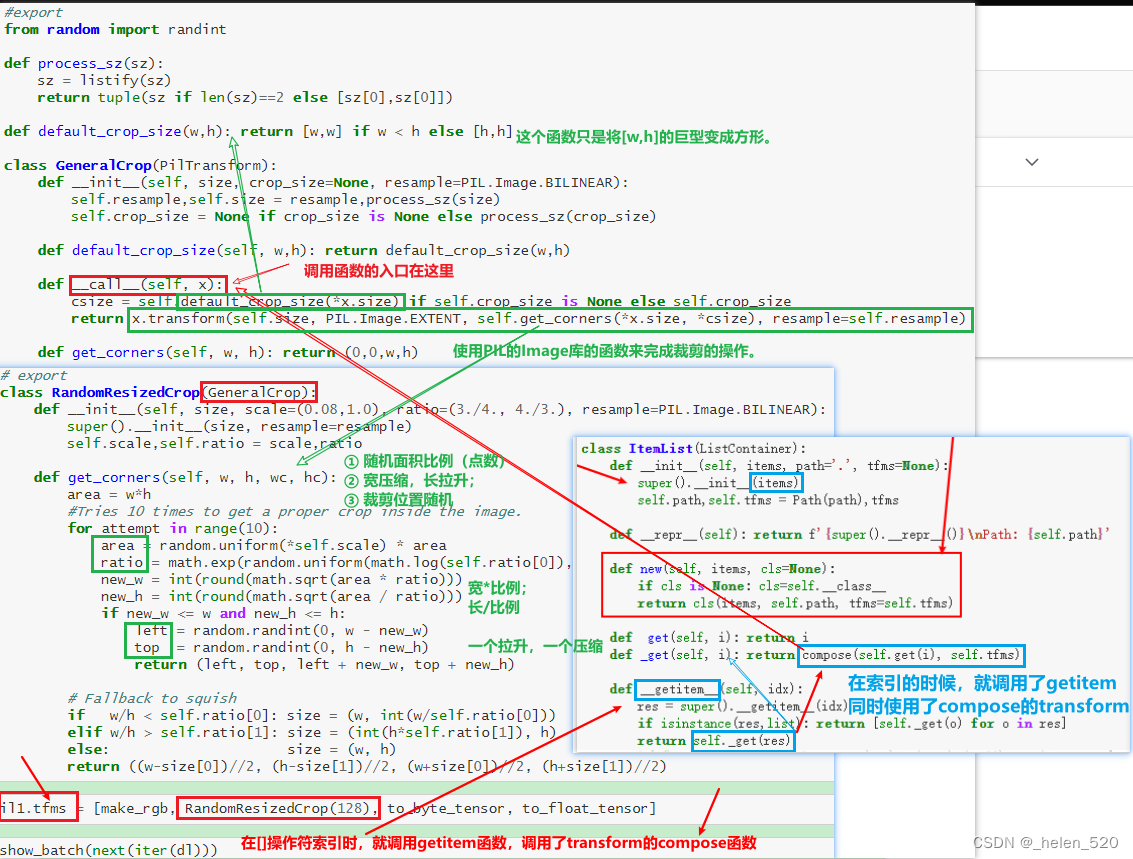
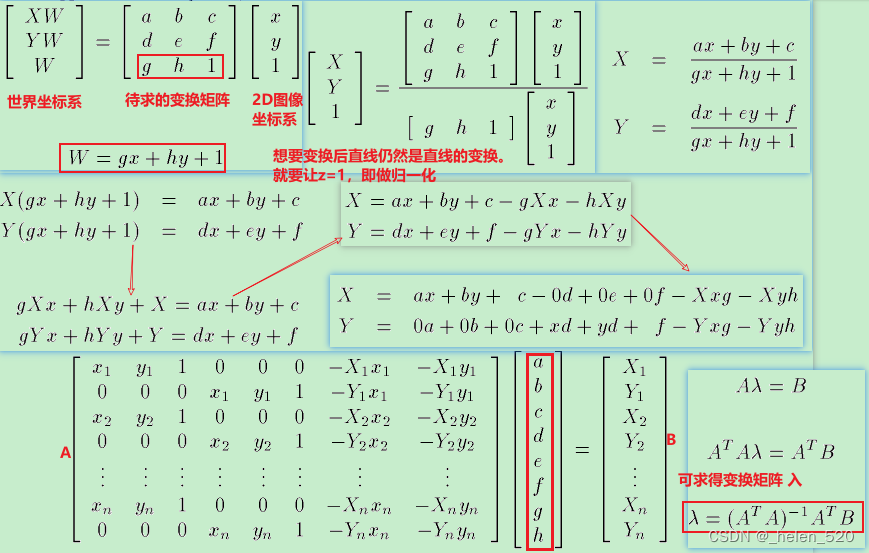
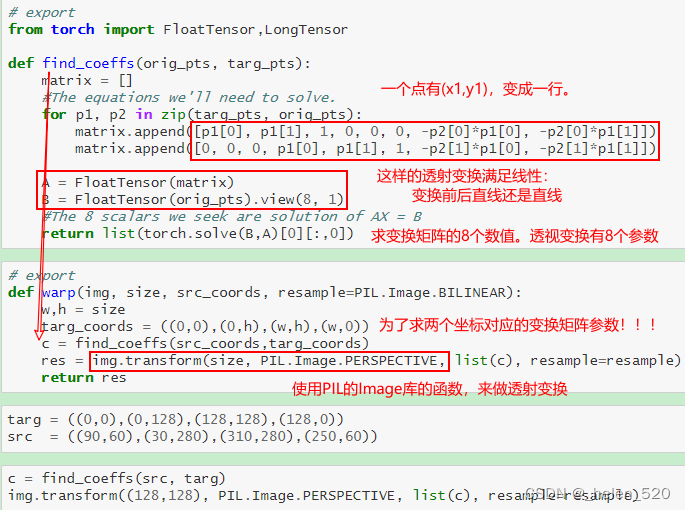
透视变换
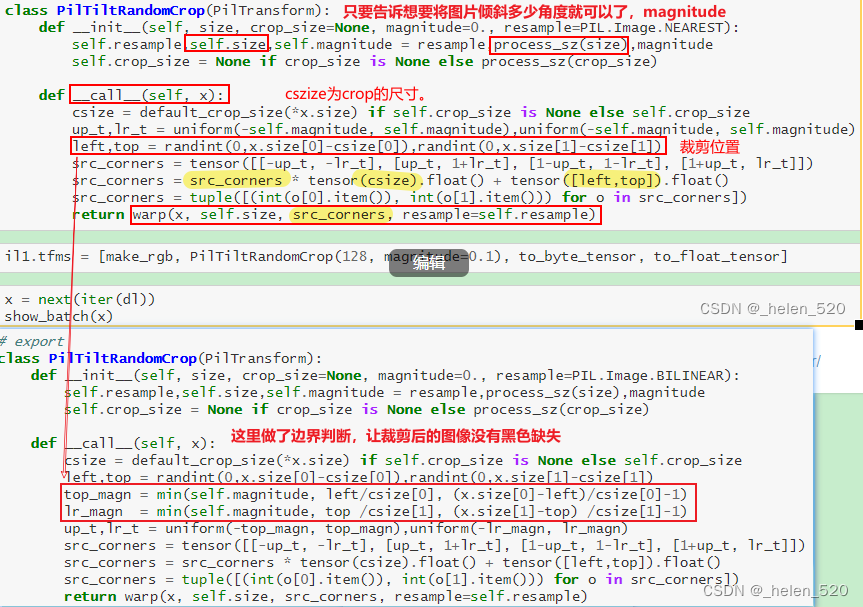
透视变换的计算公式的网站:https://web.archive.org/web/20150222120106/xenia.media.mit.edu/~cwren/interpolator/
批量做数据增强:Batch data augmentation
在GPU上对图像进行任意的仿射变换,如旋转、缩放、移位、变形等。pytorch可以实现。
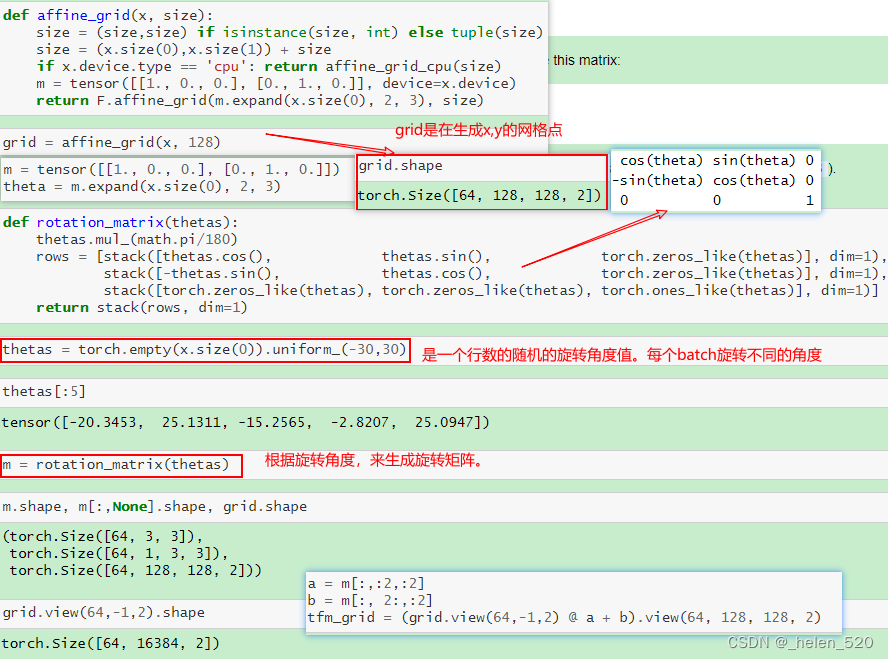
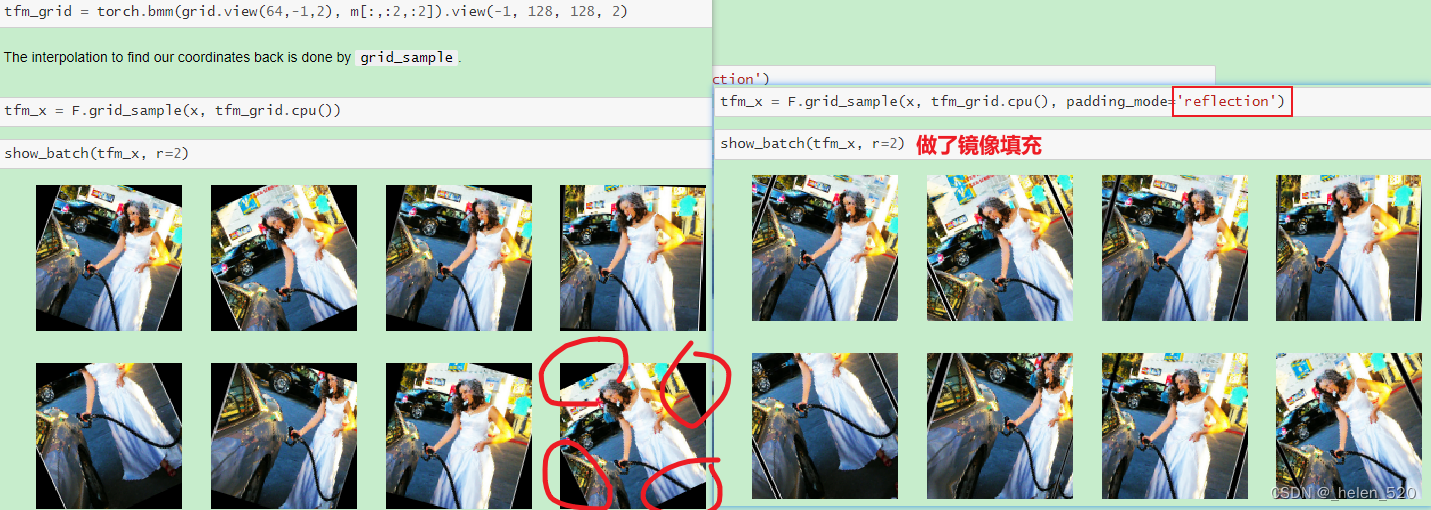
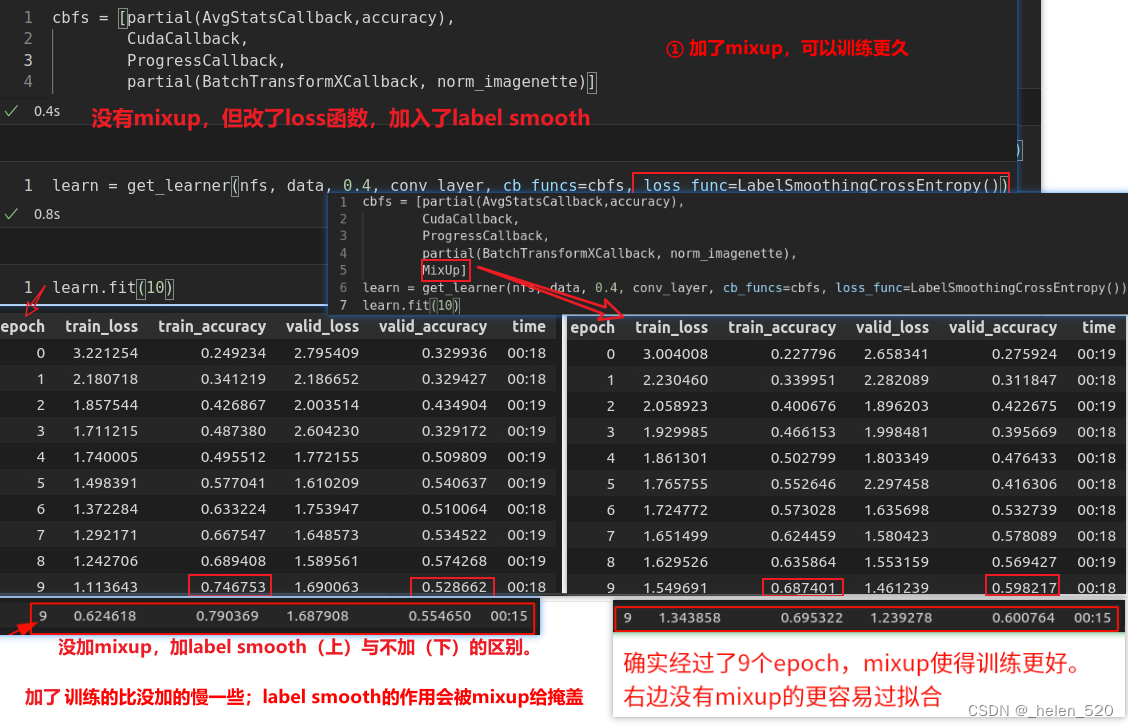
7. mixup && labeling smooth 标签平滑
10b_mixup_label_smoothing.ipynb
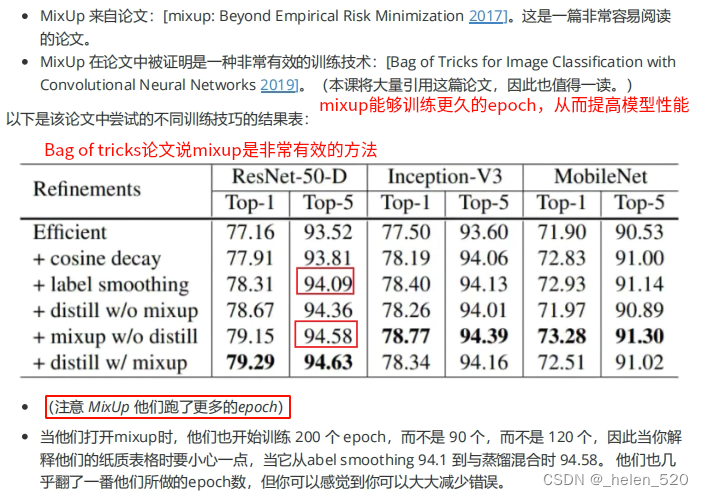
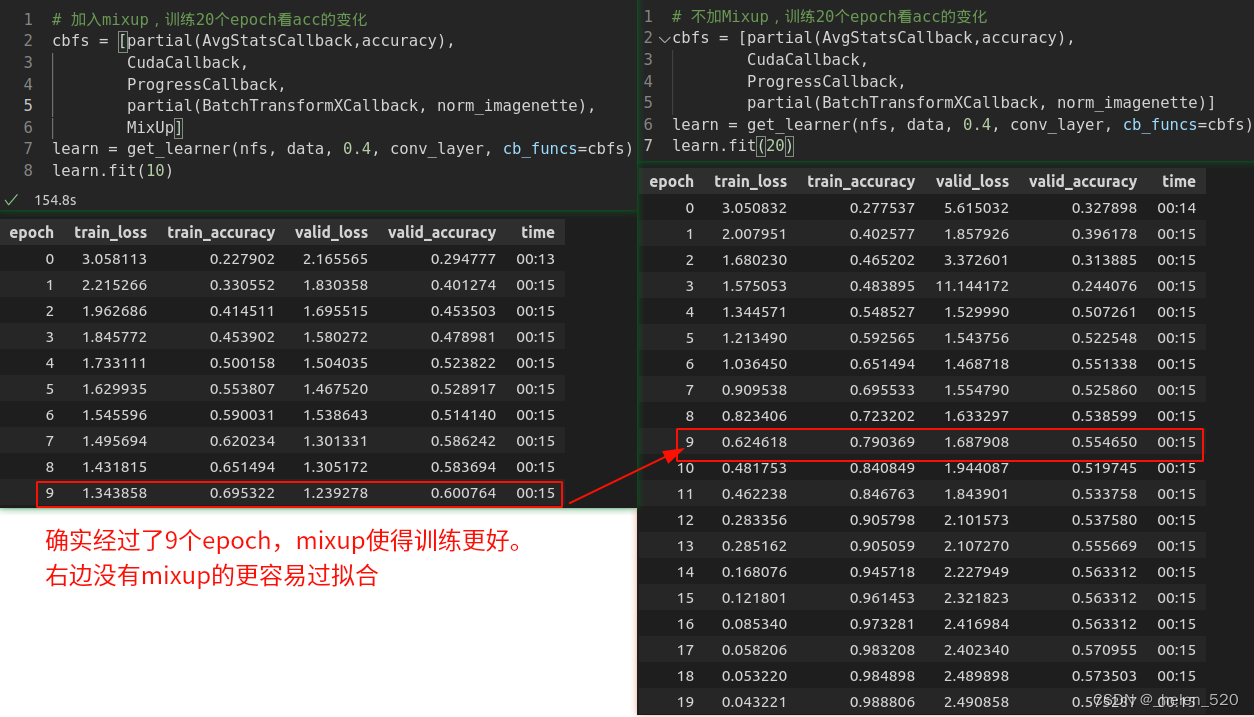
mixup数据增强技术可显著改善结果。特别是当数据较少时,可以让网络训练更长时间。


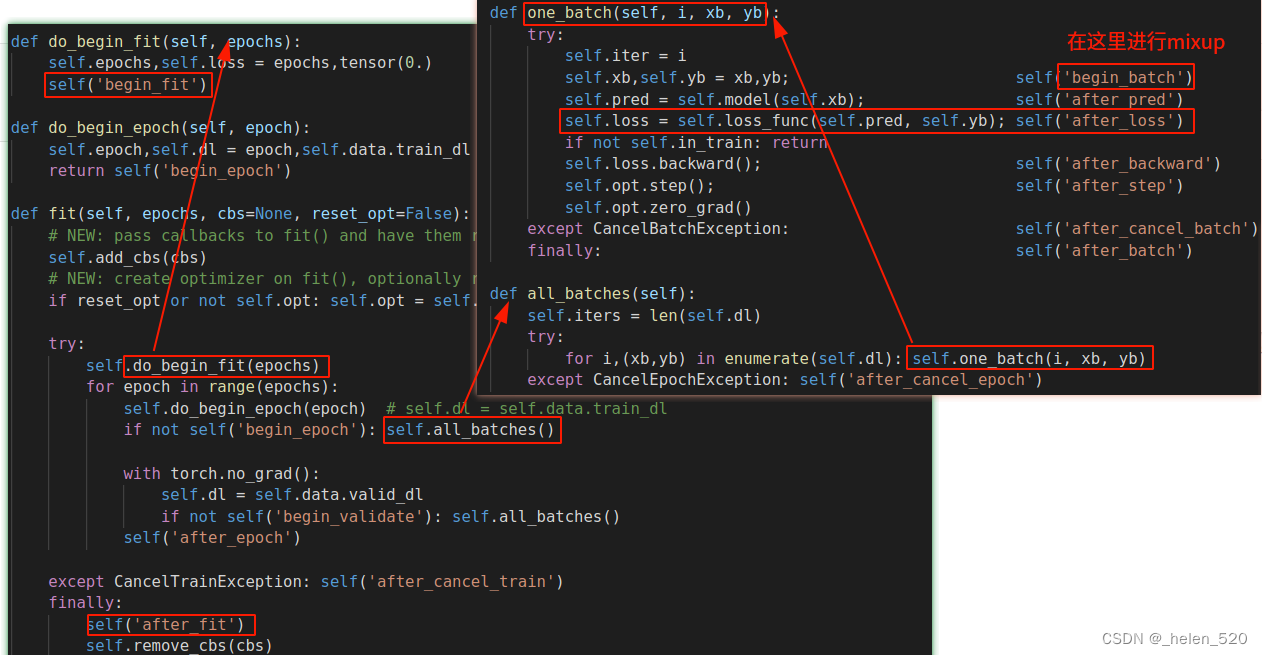
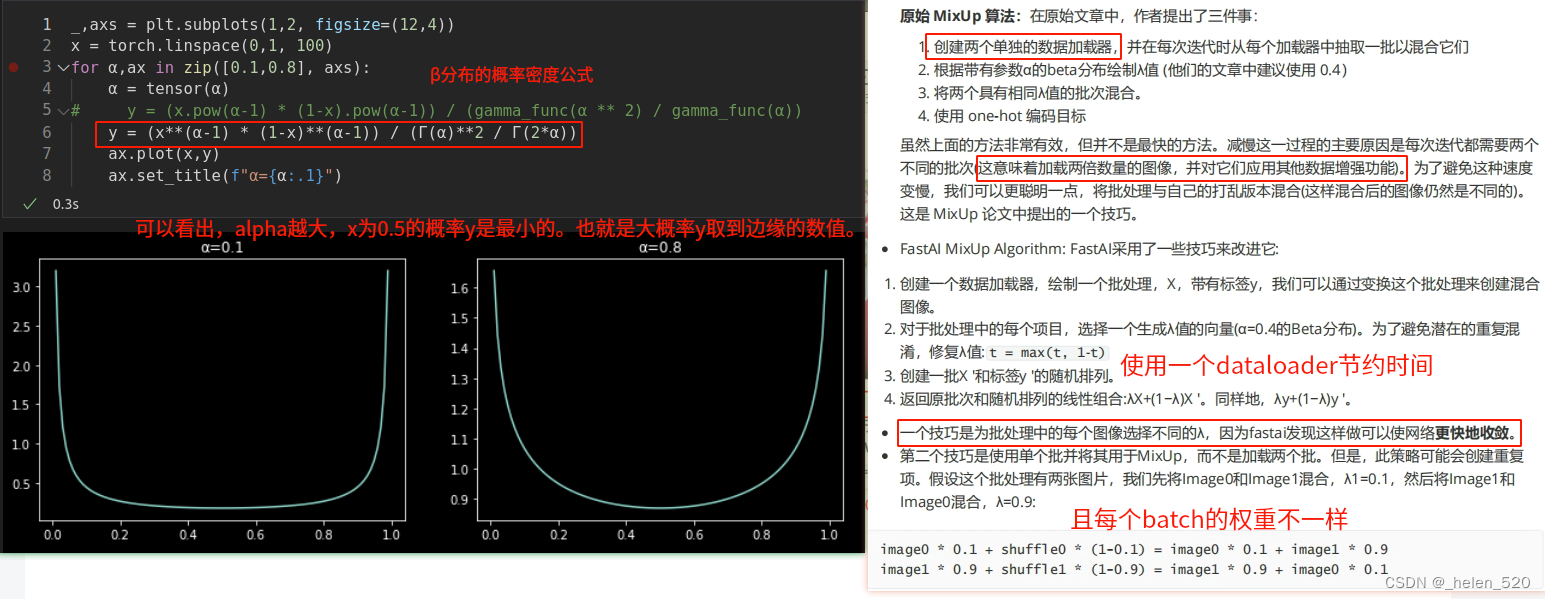 ① 在一个dataloader中,速度快;
① 在一个dataloader中,速度快;
② 使用max(t, 1-t)可以避免重复
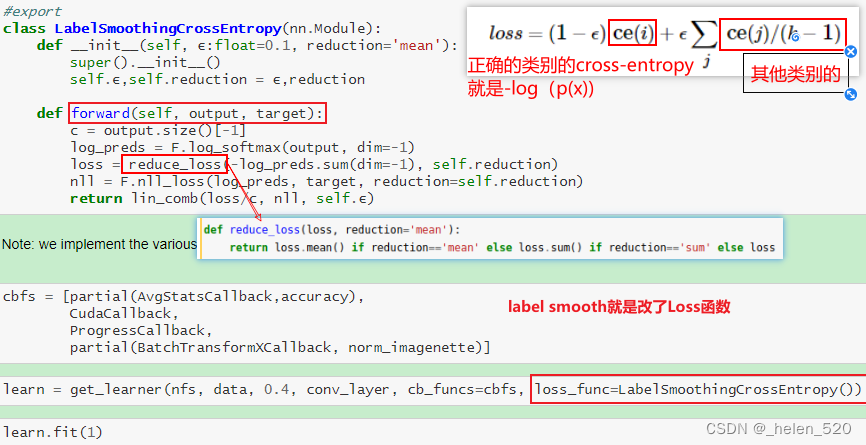
③ loss上面进行修改
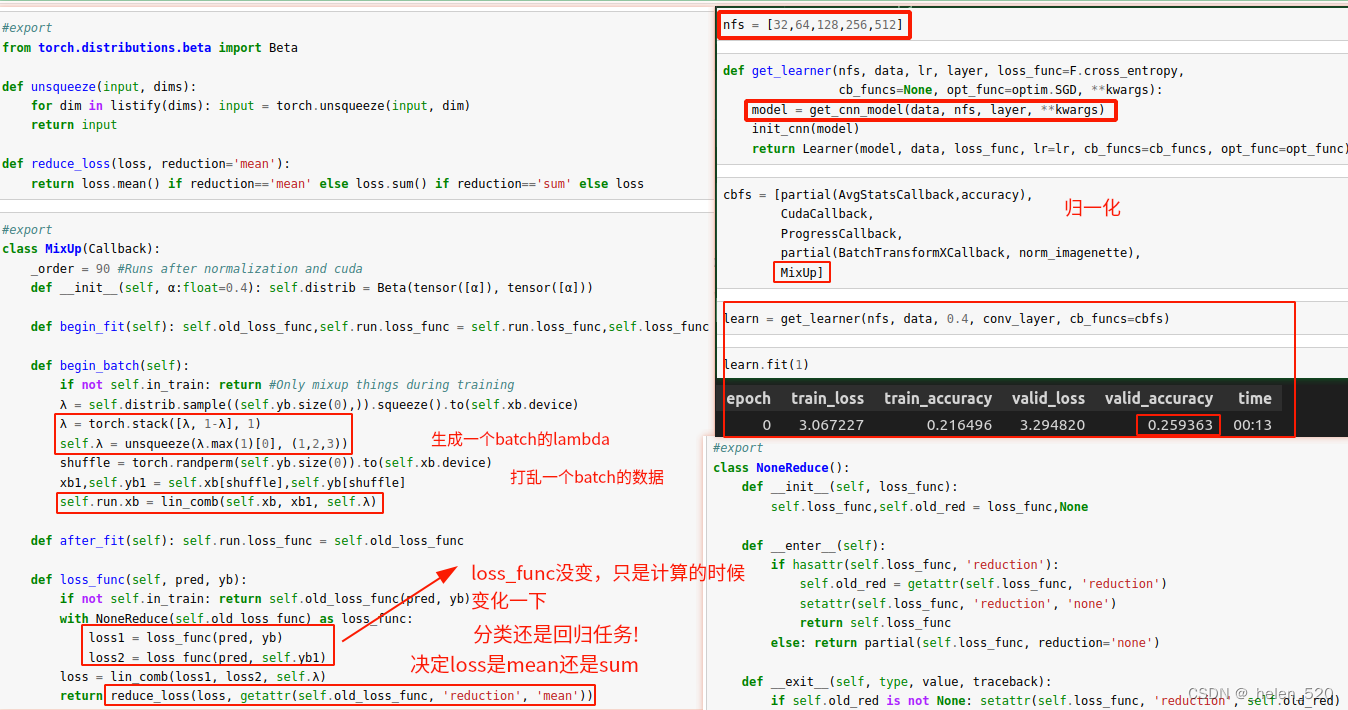
使用reduction,是因为pytorch的nn.crossEntropy函数中有一个reduction属性,来指定是计算单个损失,还是计算整个batch的损失(mean or sum)。
这里希望先进行线性计算,再进行batch求和。所以在计算线性计算的时候,要关闭reduction。即,loss1和loss2计算的时候要NoneReduce,就将reduction的属性设置为none了。并将原来的reduction状态保存在self.old中。
然后整个batch的reduction再使用reduction的mean属性来完成。
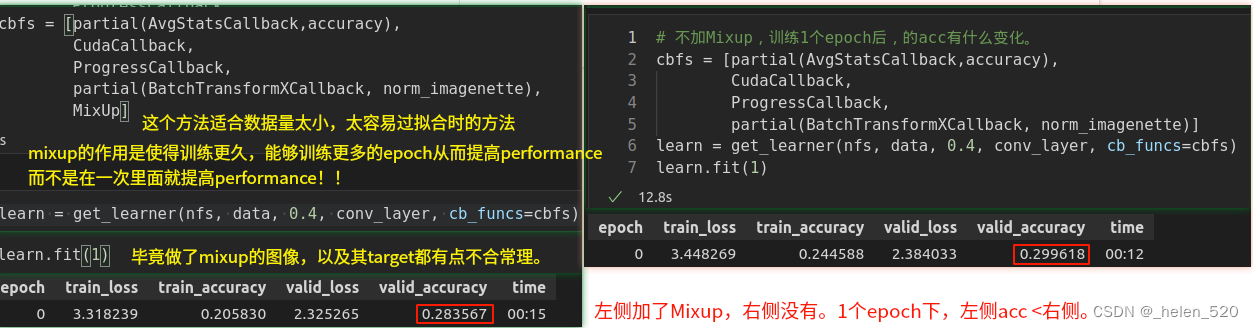
mixup有利于训练更稳定:可以认为,样本的mixup加入了更多的背景因素。使得训练更加鲁棒。右边比较早的开始过拟合了。
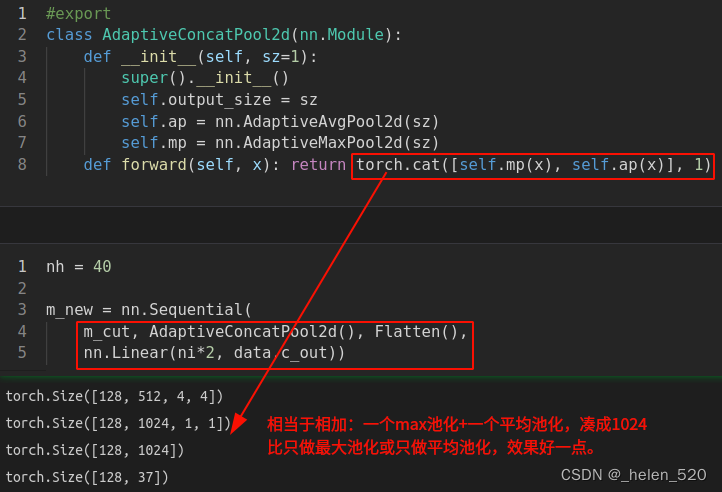
网络架构如下:
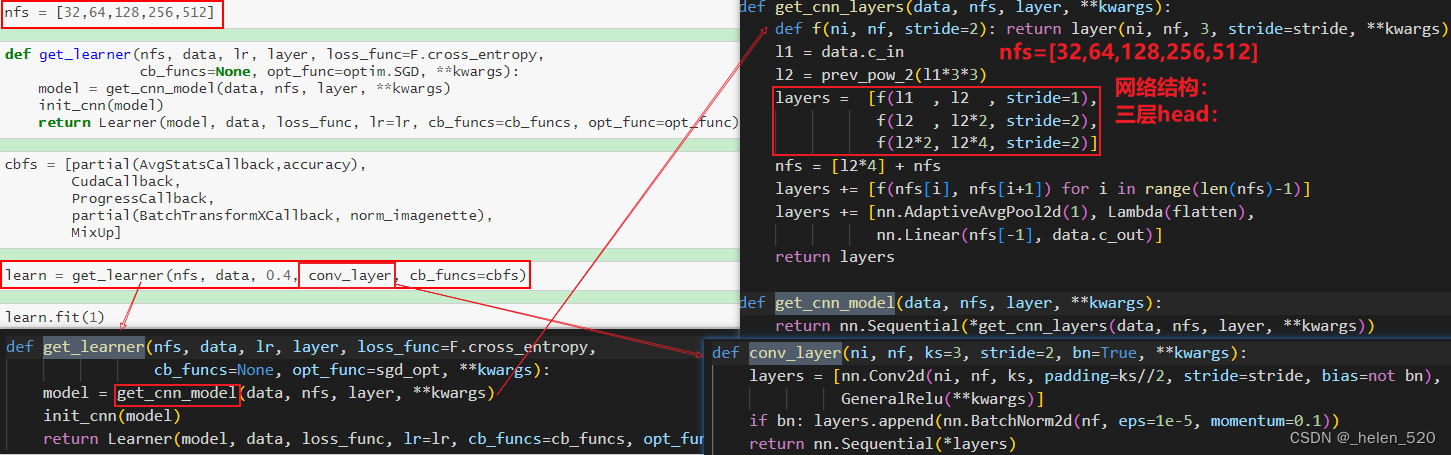
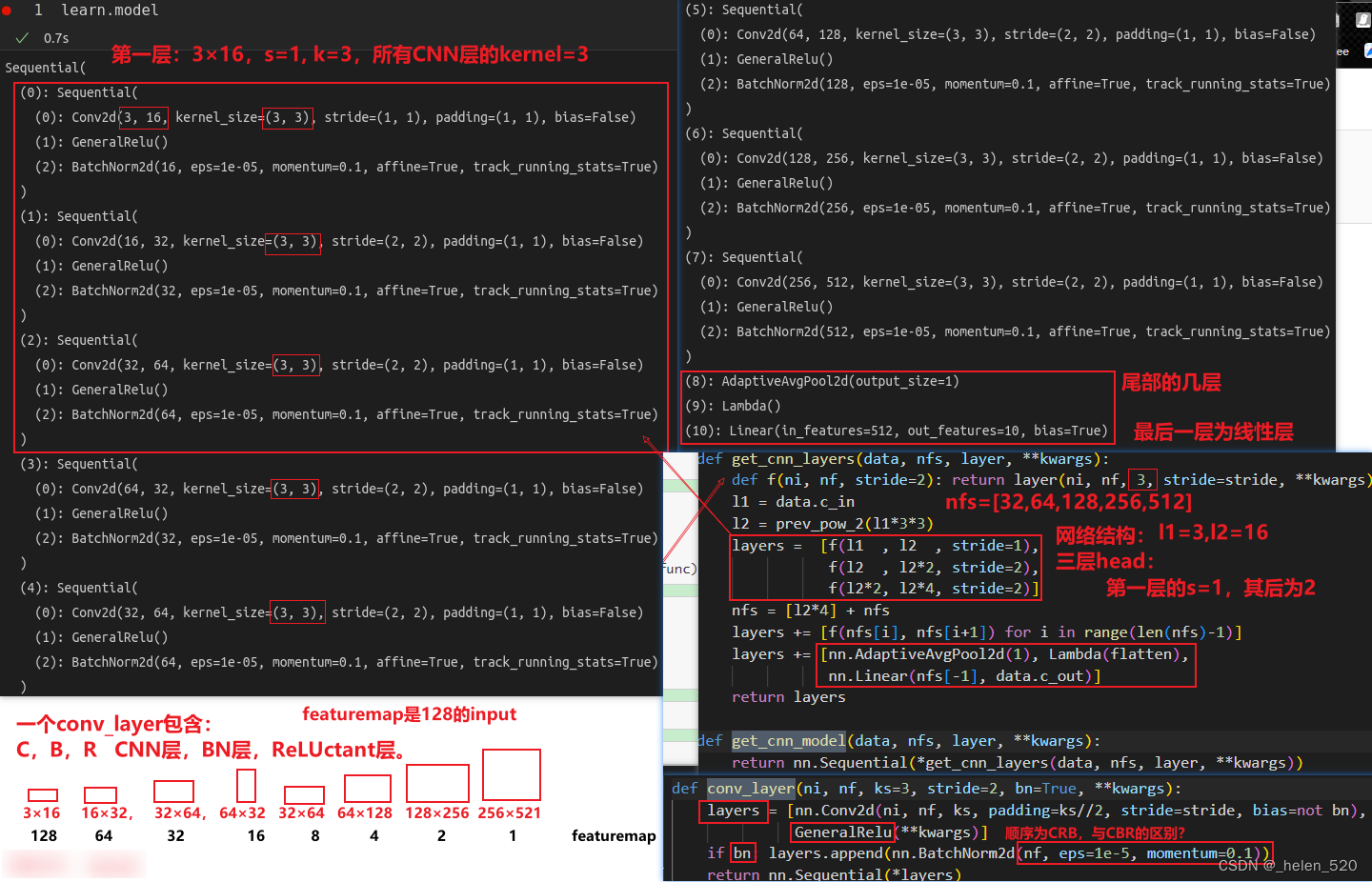
model的网络结构如下:
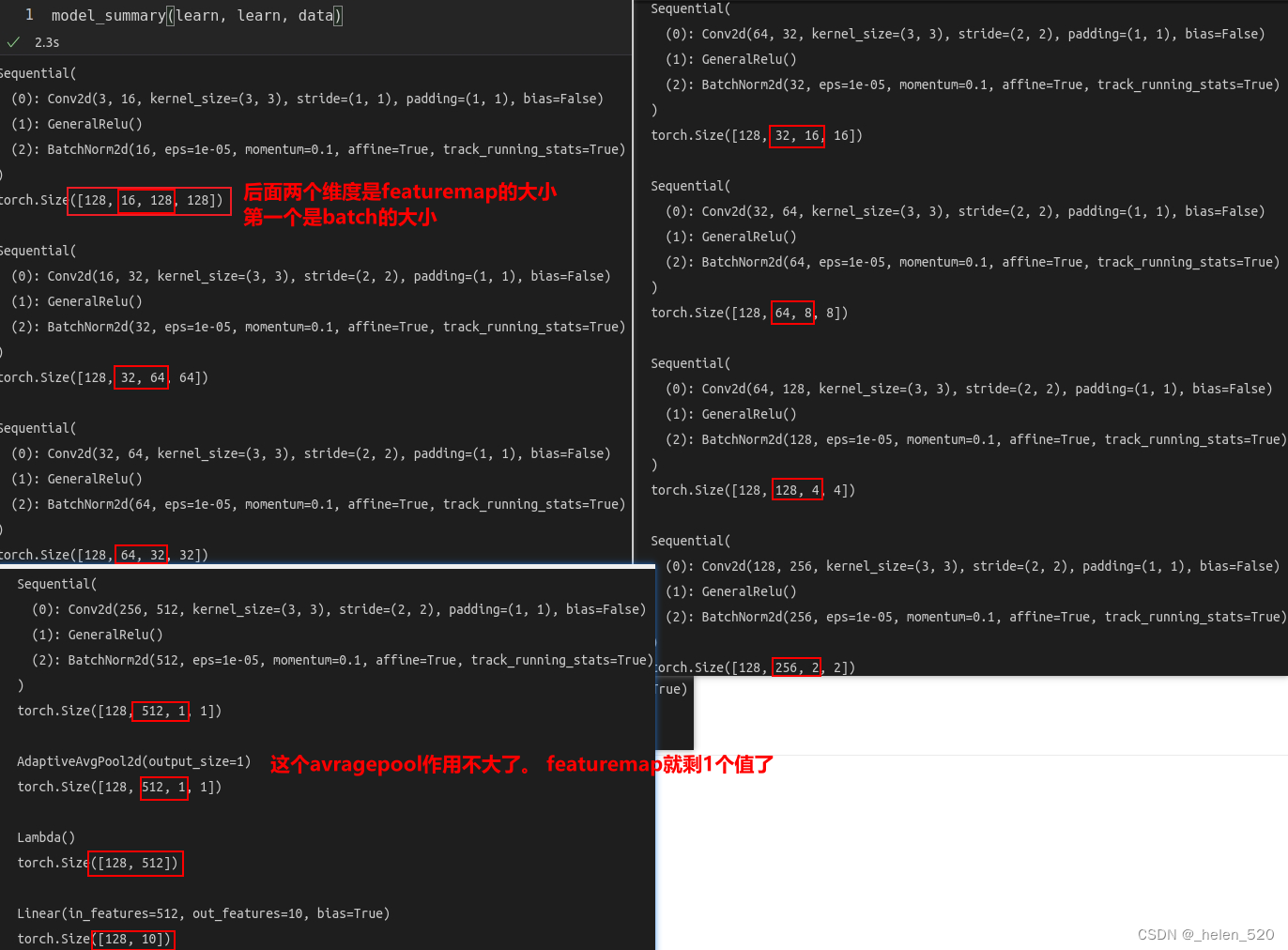
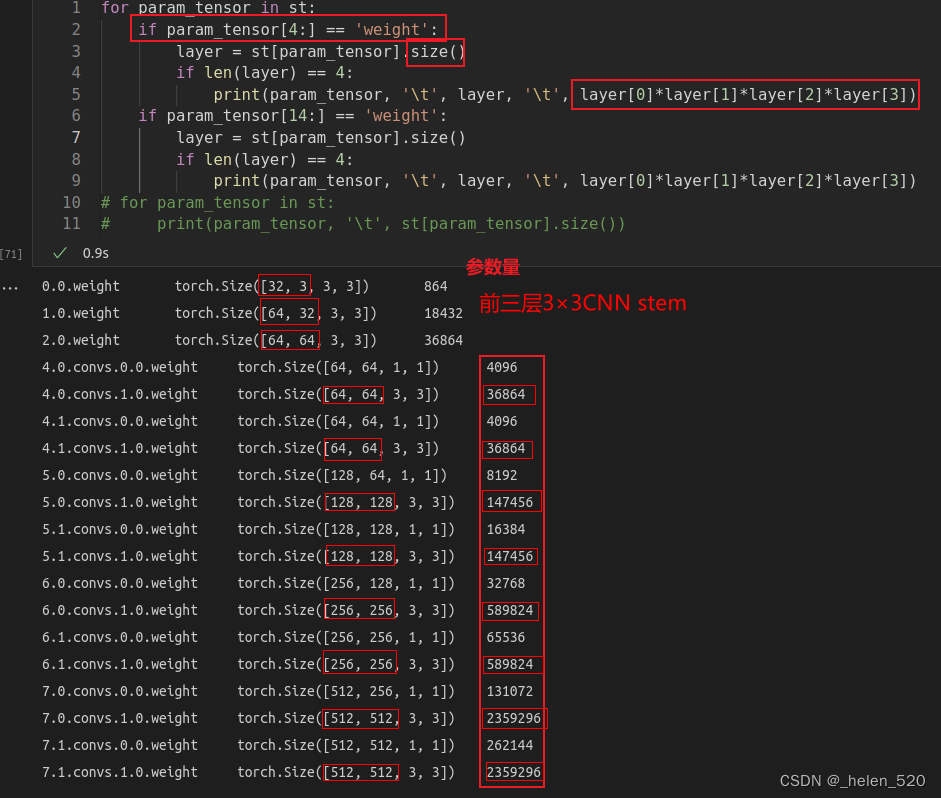
featuremap经过每一层的情况:(之前有一个模型参数量计算的)
model_summary在nb_08.py中
Label Smooth 标签平滑——经常用于分类的正则化技术
- 这是处理数据中标签的噪声的一种非常简单,但非常有效的办法。标签中可能会存在噪声。
- 即使数据中有50%的标签都是错的,这样训练出的结果依然可以很鲁棒。
- 在花费大量时间清理数据之前,我们依然可以较快的进行训练,从而来检测一些手段是否有效。
- 什么是label smooth?——故意为标签引入噪声。通过改变target的标签,使得模型的决策不是100% asure,而是带有一定概率。
效果对比:

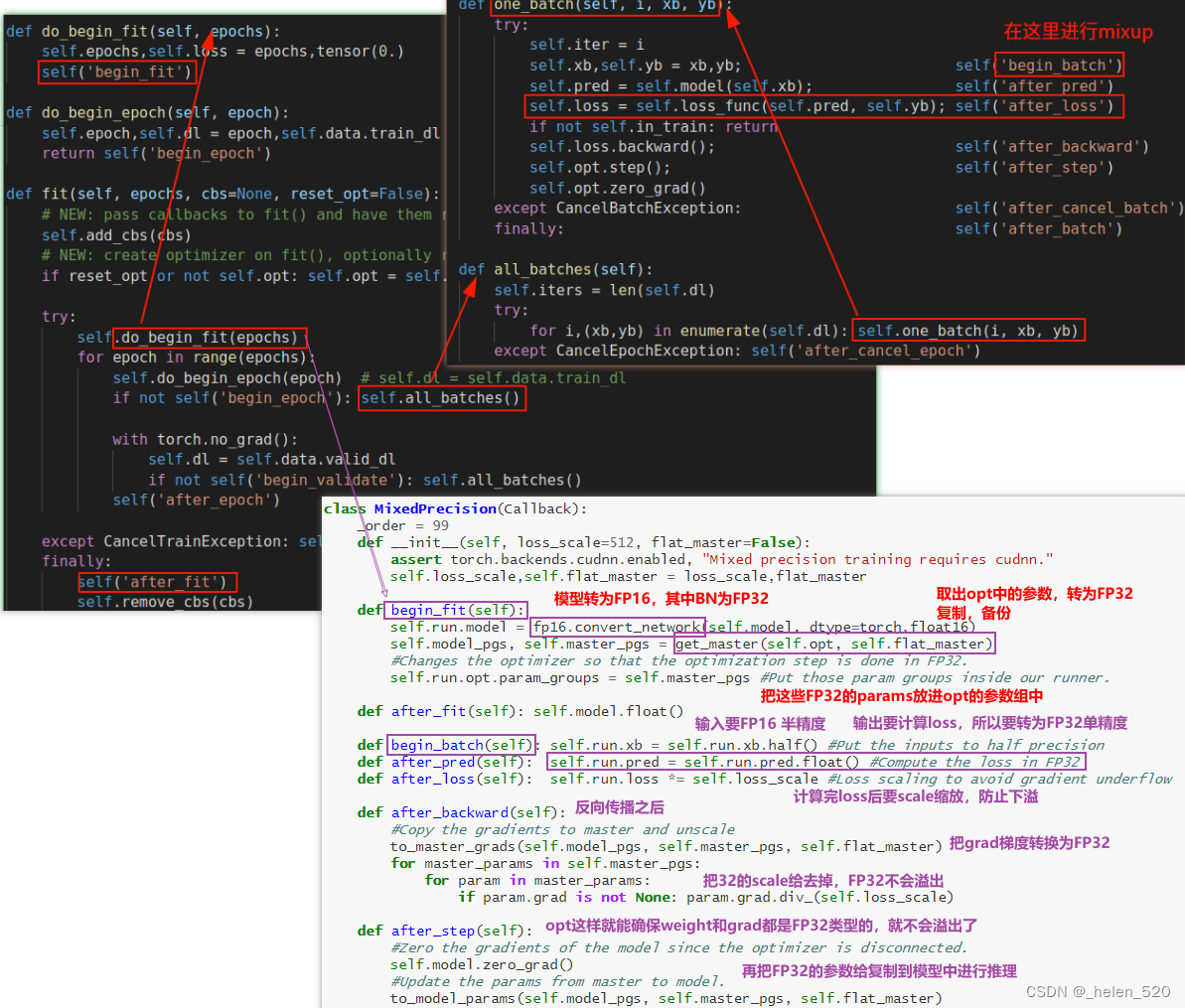
lesson12 Advanced training techniques
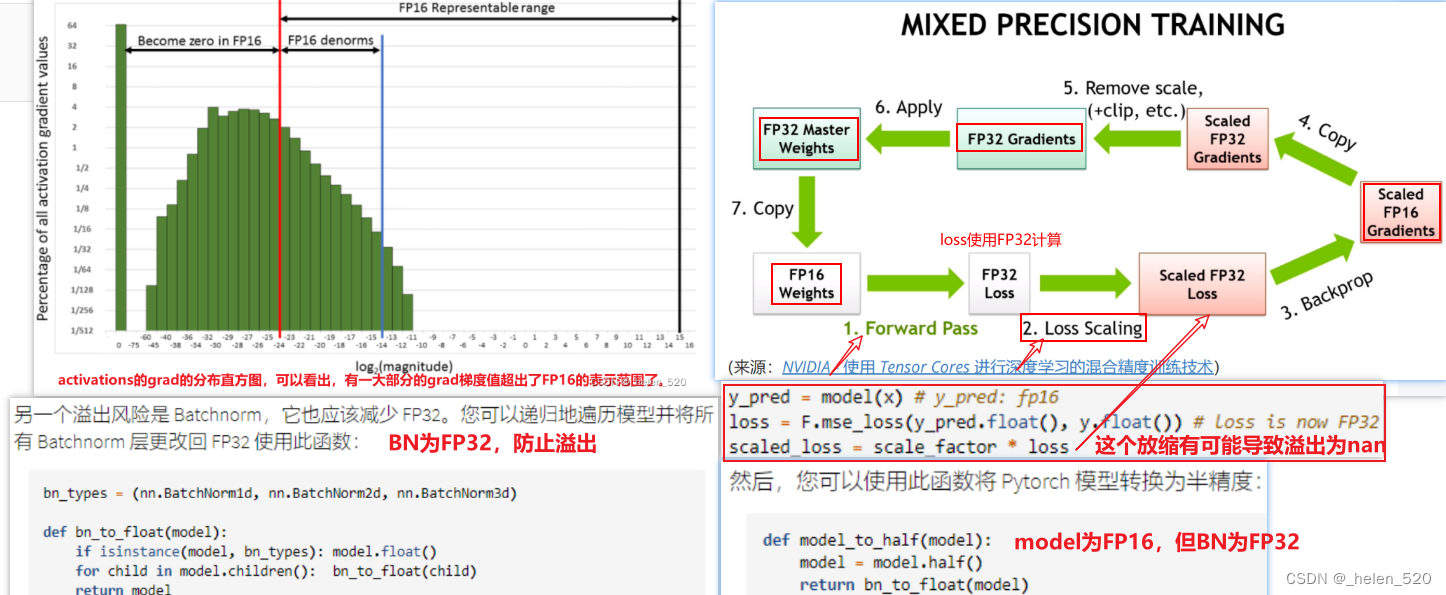
Trainging in mixed precision 混合精度训练
- FP32,小数位精度6~7位。
- FP16,小数位精度4~5位。
- 所以在权重更新过程中:w=w-lr*grad,其中grad可能就是很小。因为activations们遵循N(0,1),其梯度值就更小了。所以很可能出现权重的梯度是值很小的值,在FP16时就会被四舍五入掉。导致精度下降。
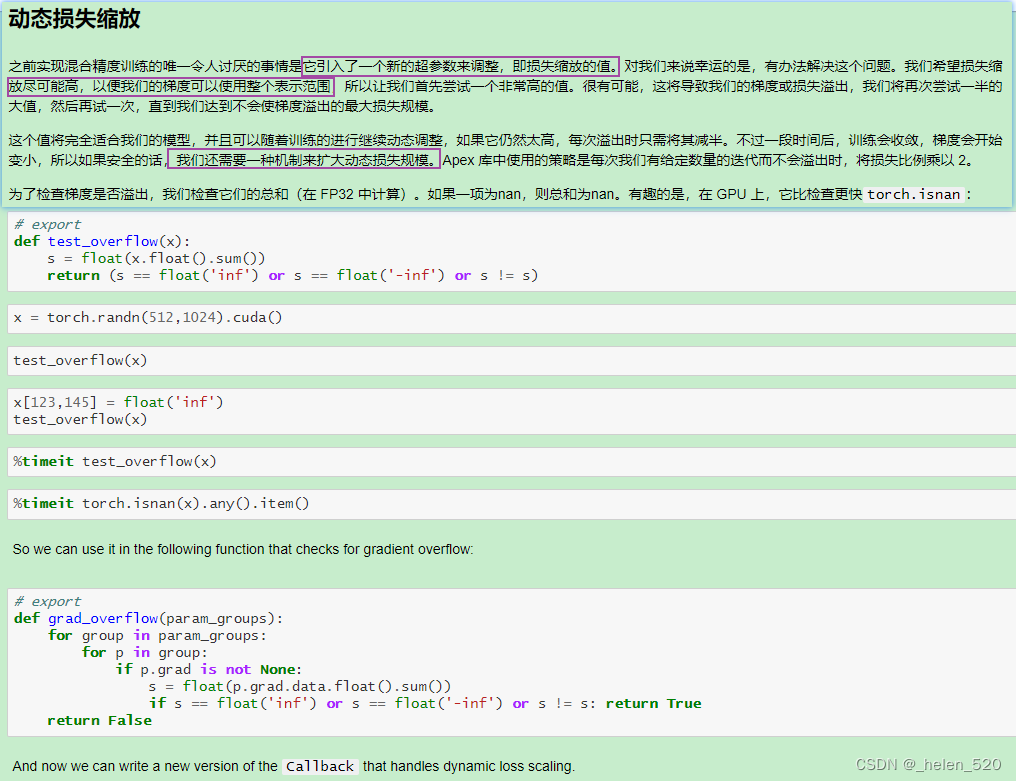
- grad可能下溢,FP16如果梯度下溢,那么grad就变成了0。
- 同时在FP16中,也更可能上溢,变成nan。训练更容易发散,不收敛了。
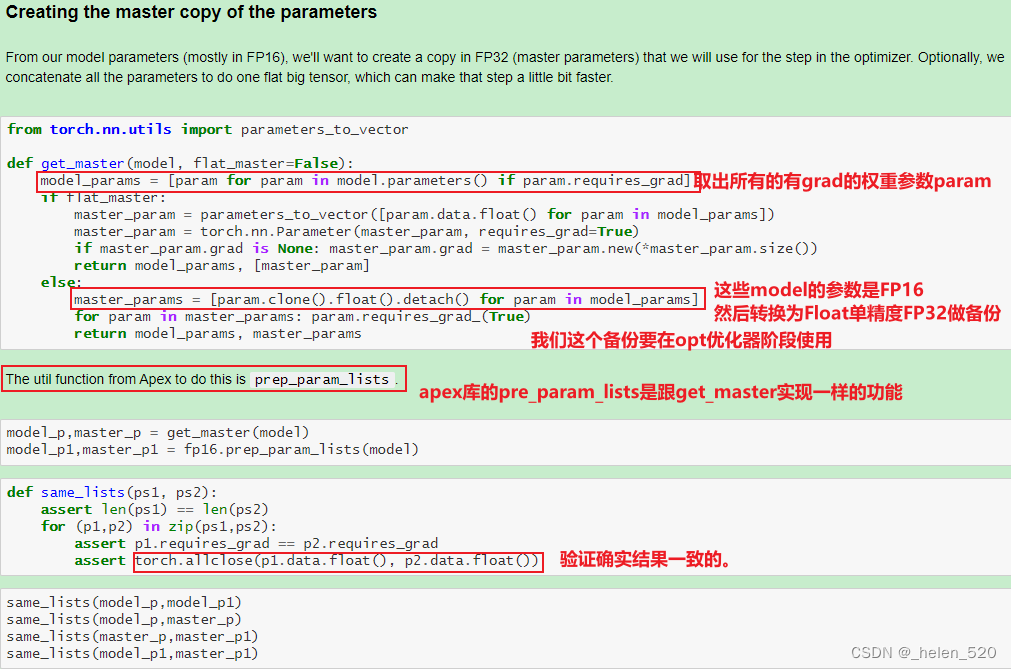
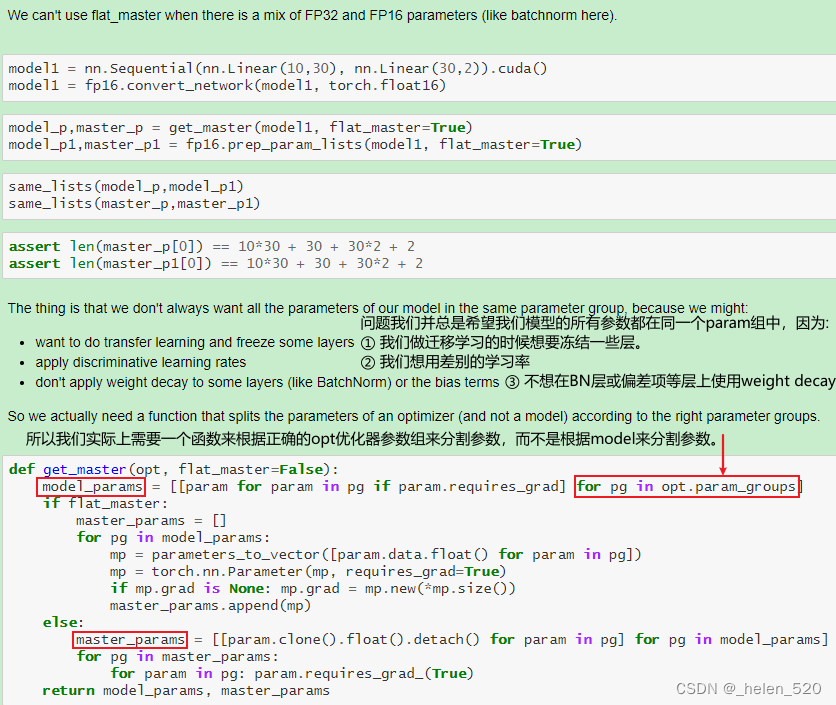
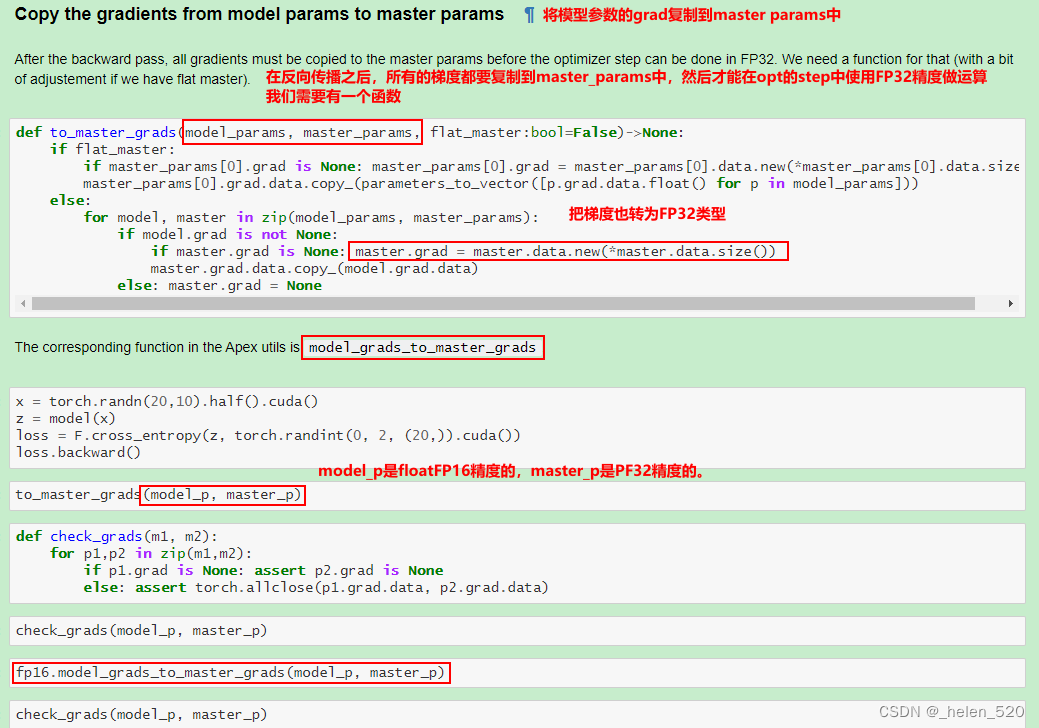
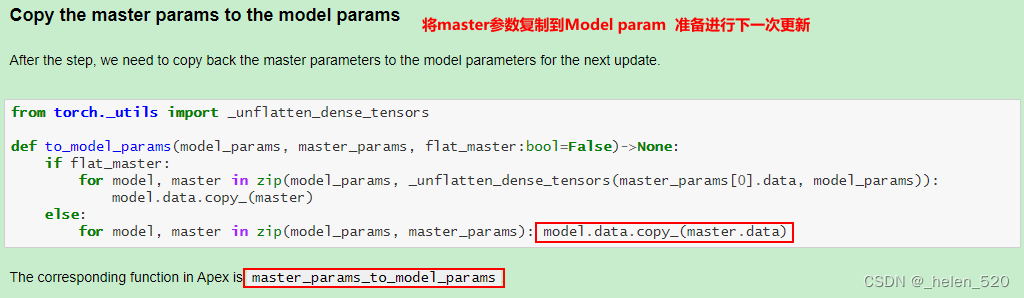
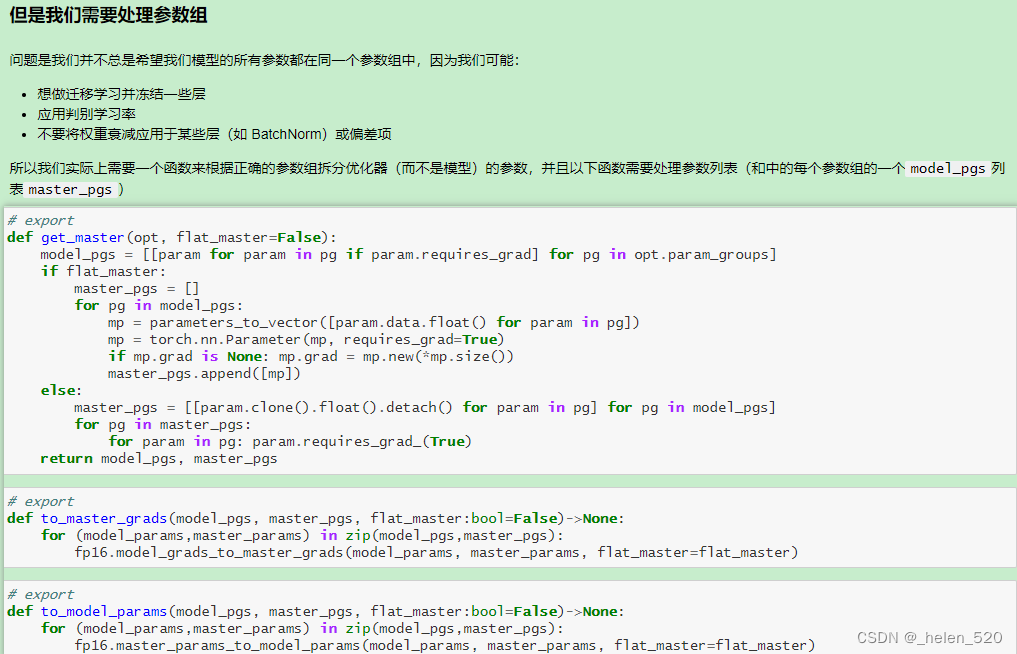
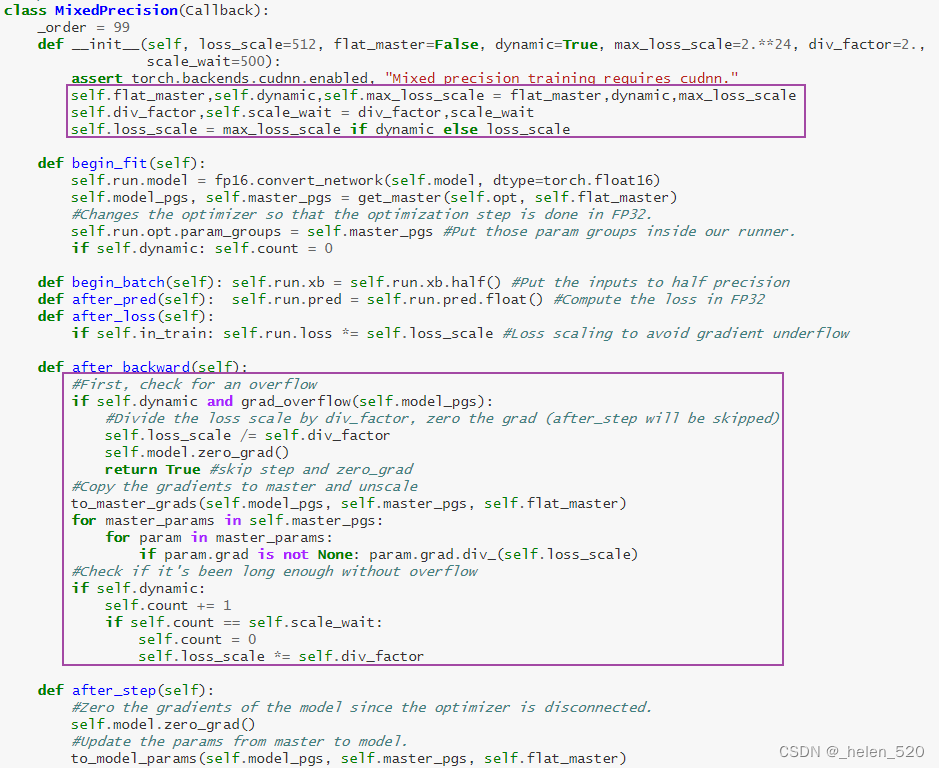
- 怎么办呢?——混合精度训练。在前向传播和传播的过程中使用FP32.
- ① 权重更新不精确,grad下溢
- ② grad下溢——乘以一个比例因子,scale,进行放大。
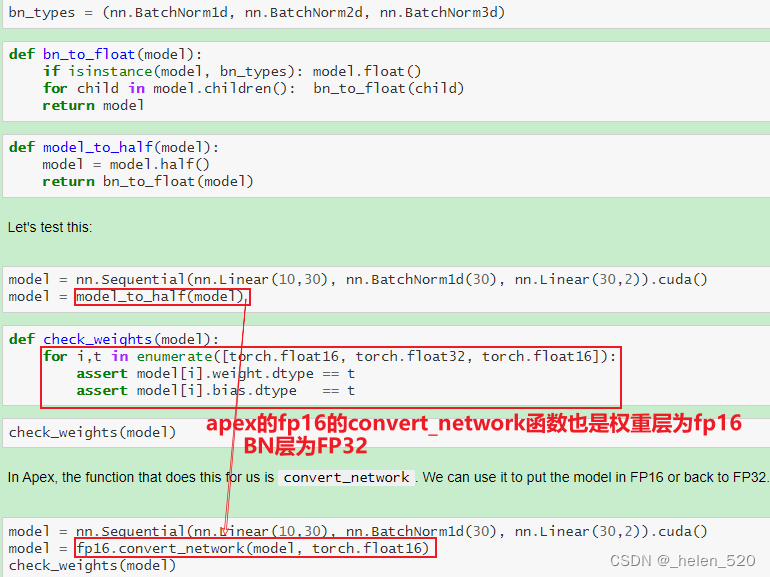
- ③ 激活元或者Loss溢出;上溢出nan,或者下溢出。——Nvidia是将batchnorm层保留为单精度FP32,BN层没有多少权重,所以内存不会占多少,并计算FP32的损失。


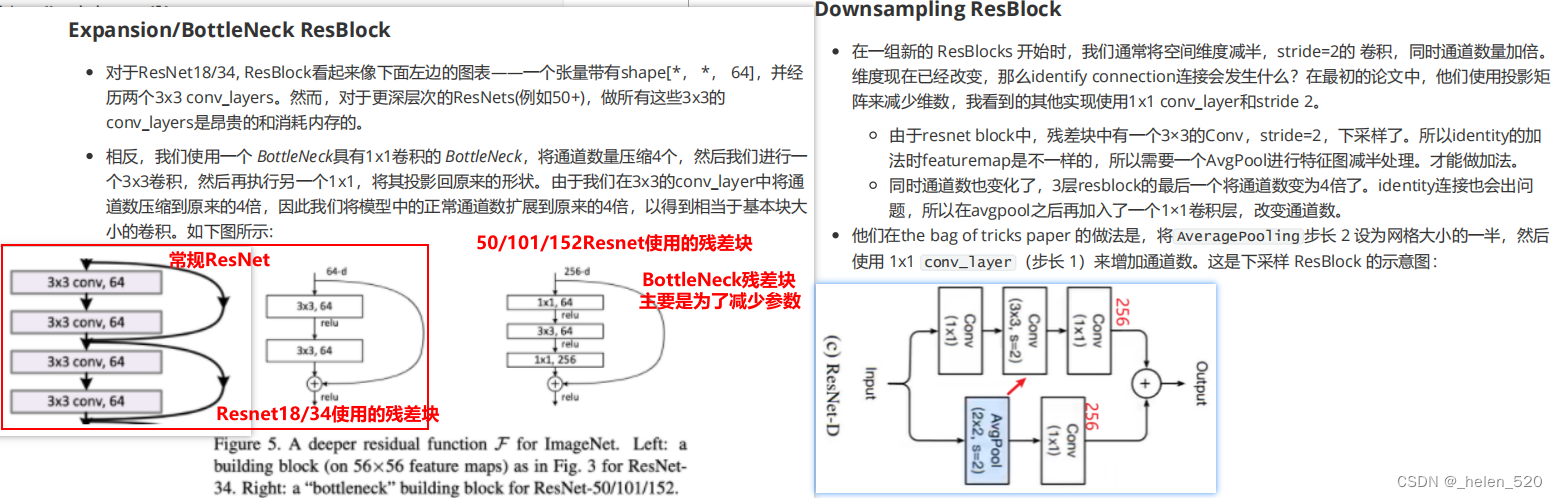
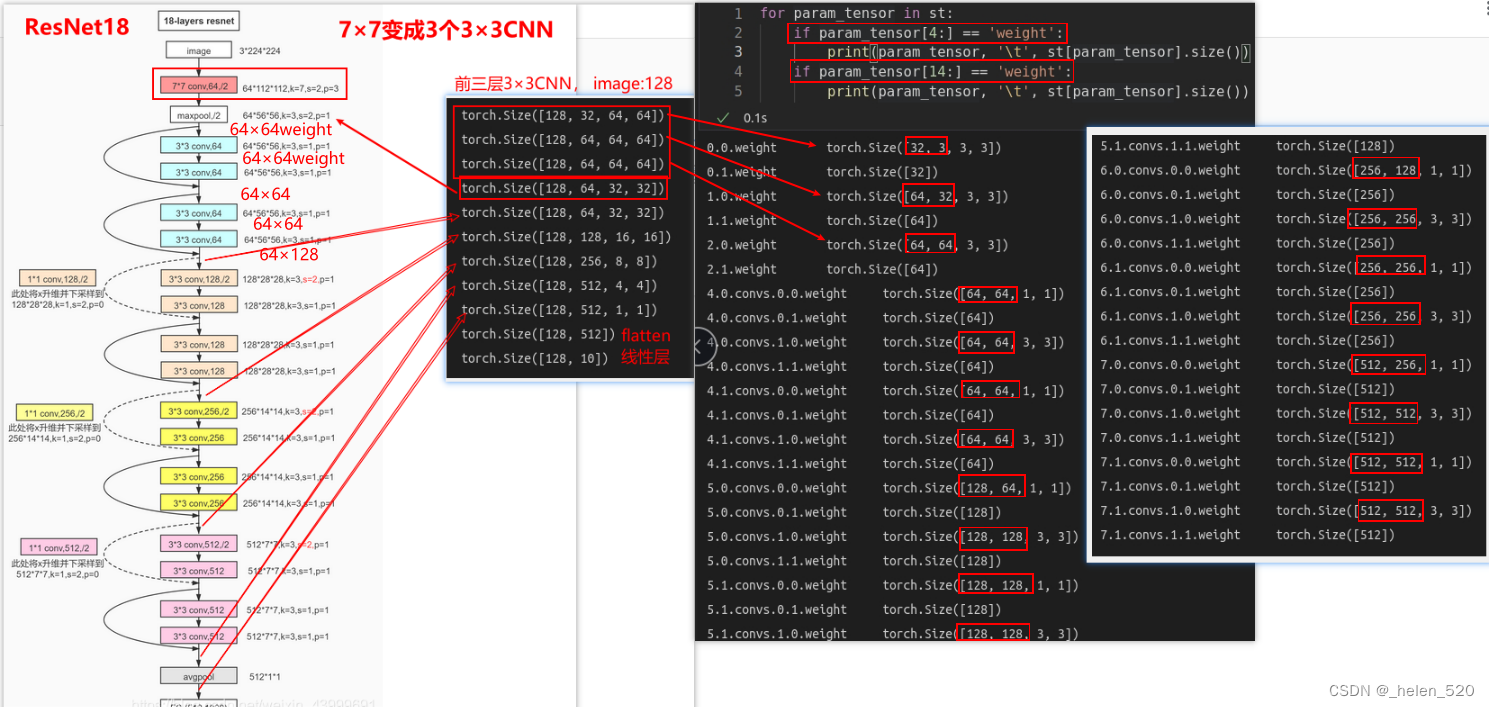
XResNet
所以,一开始不做7×7的大卷积核。
ResNetC的第一个修改:1层7×7改为3个3×3,同时有加法的网络。 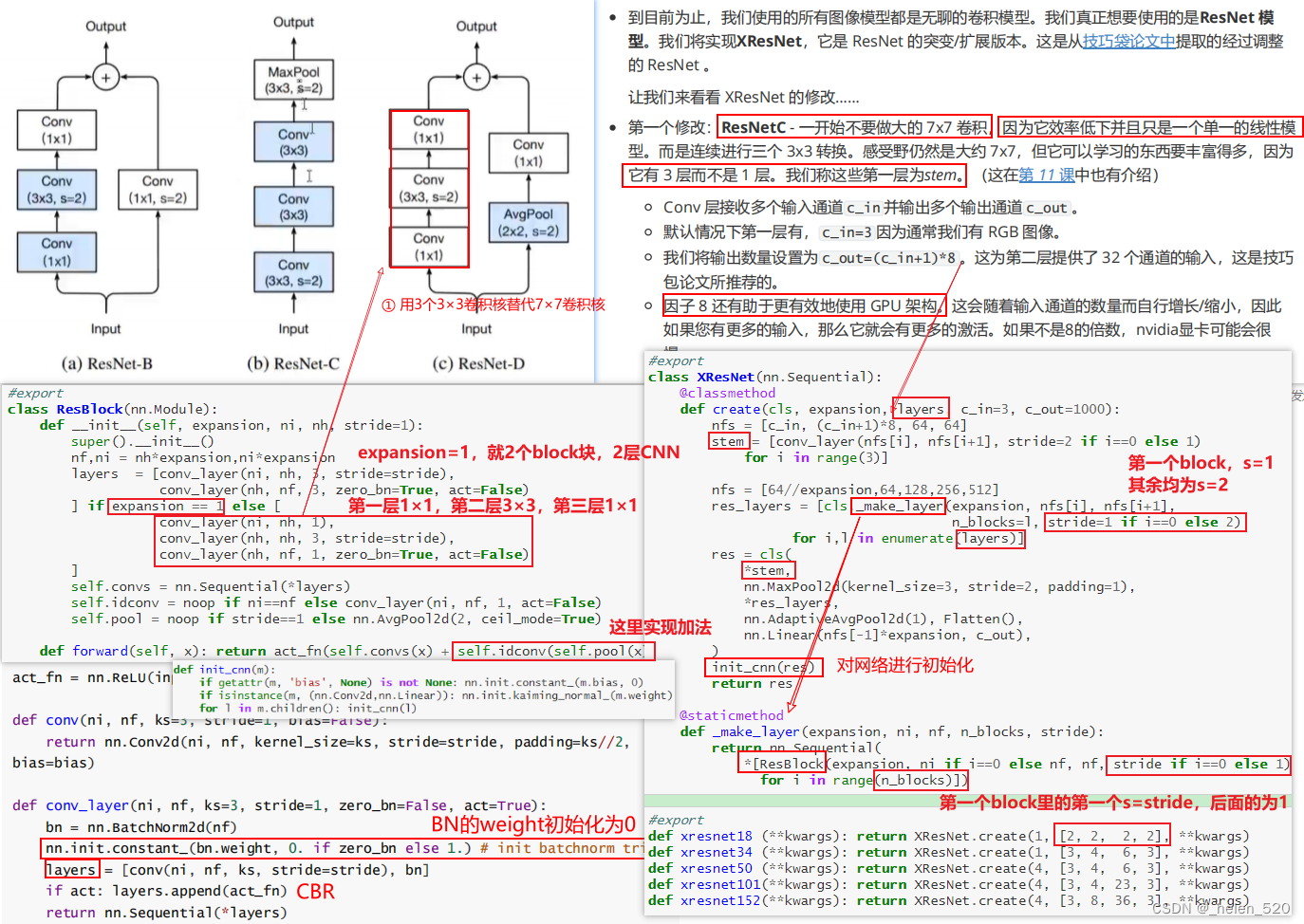
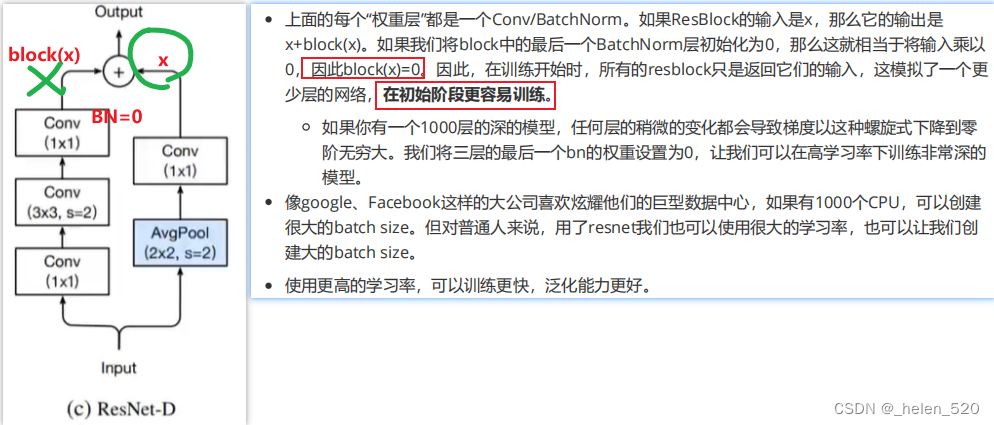
关于BatchNorm的初始化的技巧:
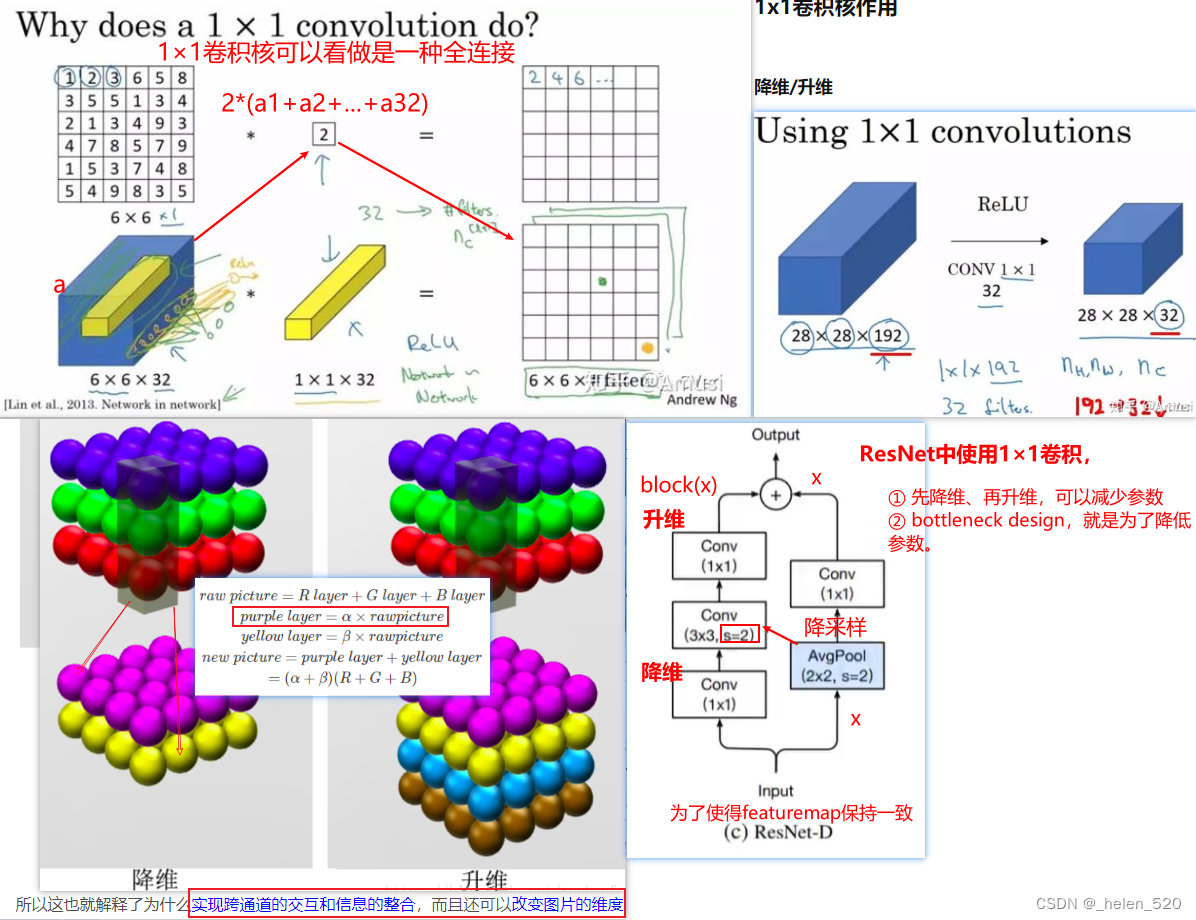
为什么要使用1×1卷积?
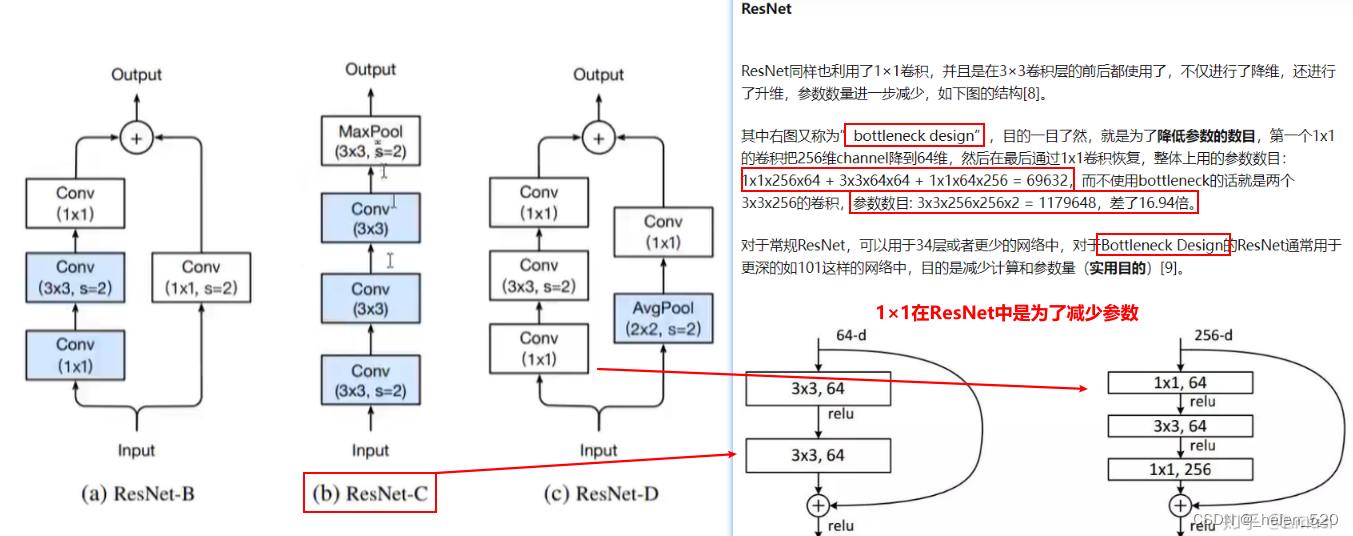

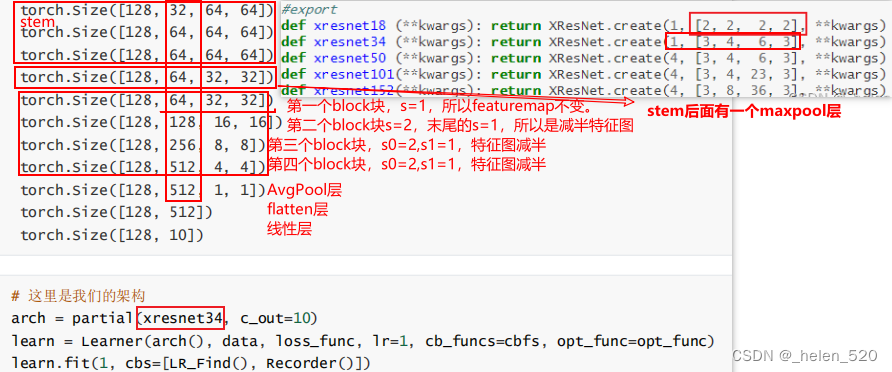
resnet34的网络构成如下图所示:
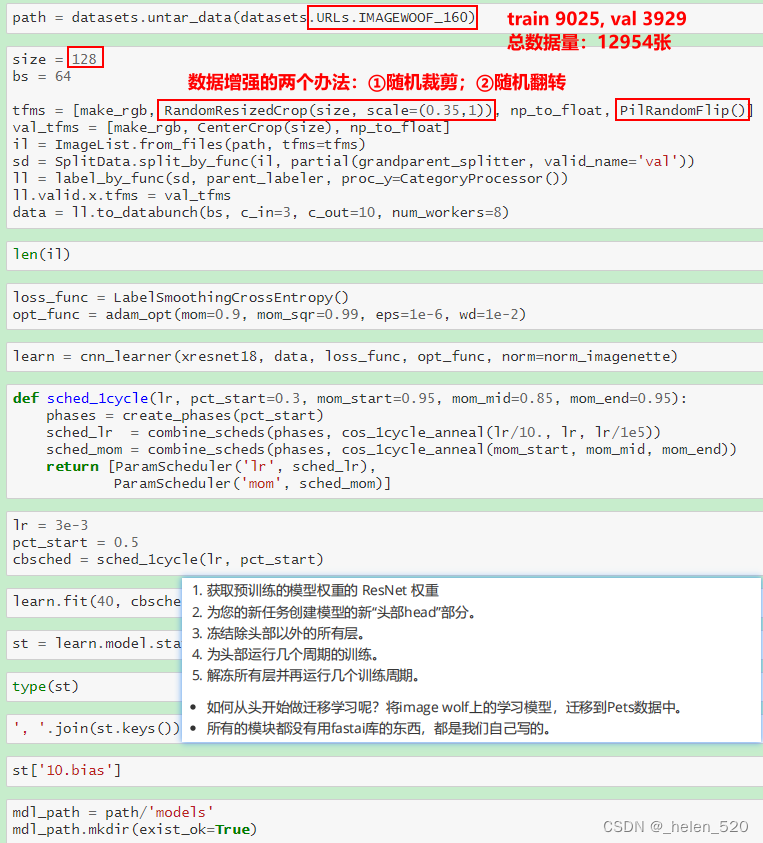
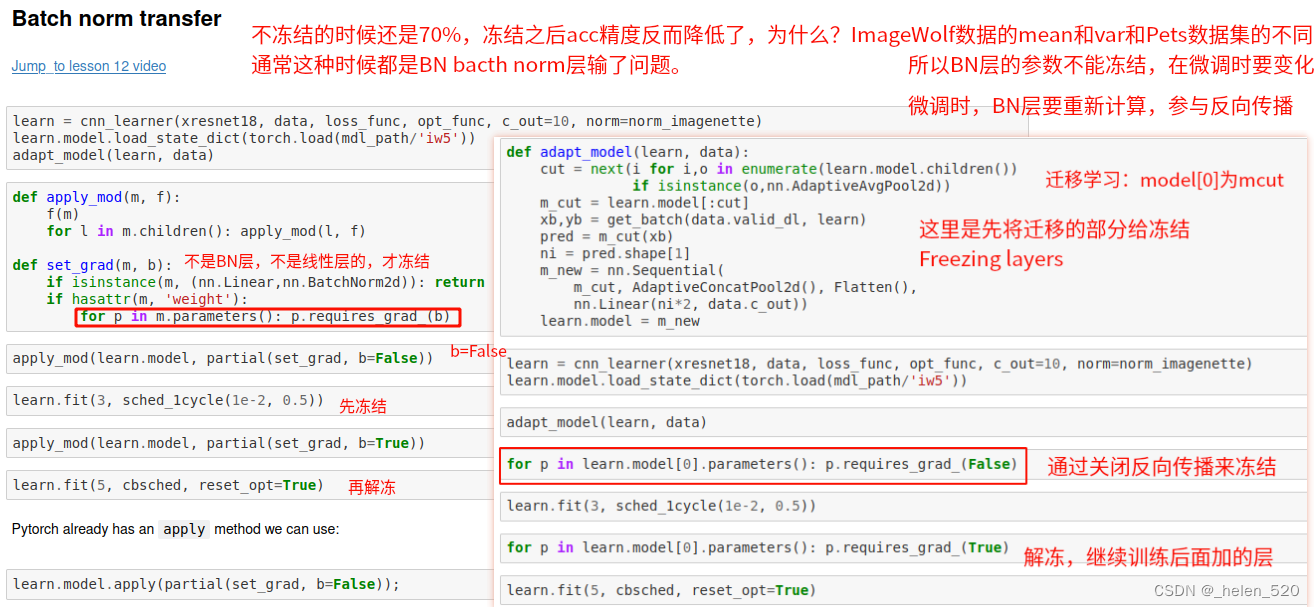
迁移学习 Transform learning和微调fine tune
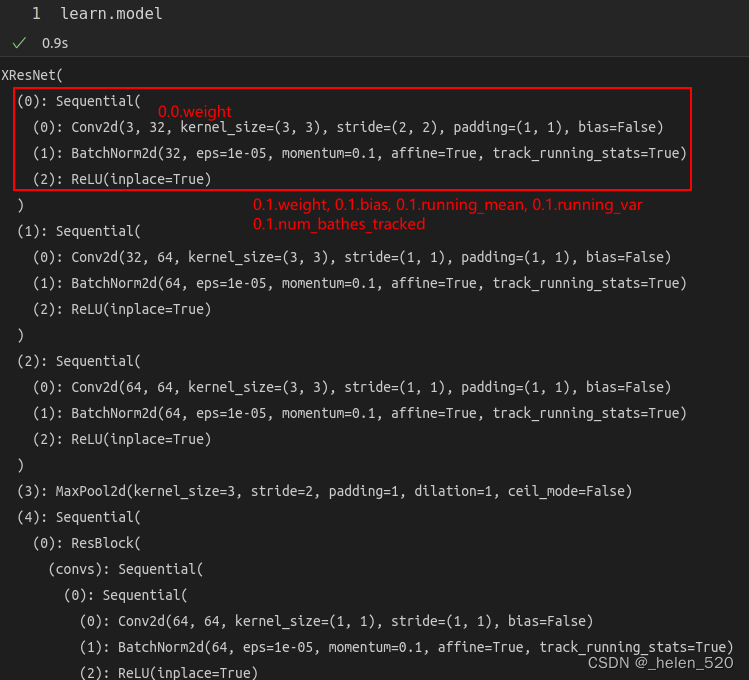
- ① learn.model到底保留了哪些parameters的值,这些都是训练得到的权重值。
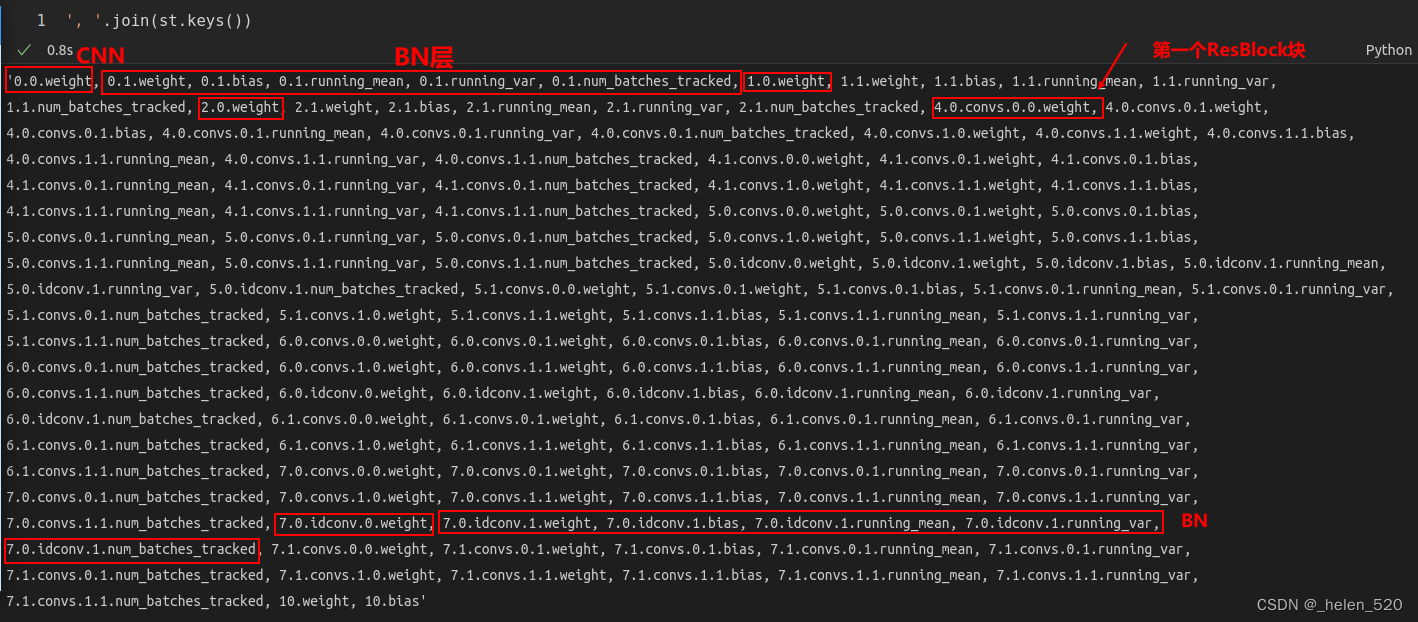
使用的网络时xResNet18。BN对训练的影响是很大的,能够使训练更加的稳定,参考右侧文章的《第6节 BatchNormalization 小批量归一化 》(三)fastai 2019 lesson10 Wrapping up our CNN 重构CNN__helen_520的博客-CSDN博客
- ② 看各个权重的size
参考教程:【PyTorch】state_dict详解_颜丑文良777的博客-CSDN博客_.state_dict
#encoding:utf-8
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import numpy as mp
import matplotlib.pyplot as plt
import torch.nn.functional as F
#define model
class TheModelClass(nn.Module):
def __init__(self):
super(TheModelClass,self).__init__()
self.conv1=nn.Conv2d(3,6,5)
self.pool=nn.MaxPool2d(2,2)
self.conv2=nn.Conv2d(6,16,5)
self.fc1=nn.Linear(16*5*5,120)
self.fc2=nn.Linear(120,84)
self.fc3=nn.Linear(84,10)
def forward(self,x):
x=self.pool(F.relu(self.conv1(x)))
x=self.pool(F.relu(self.conv2(x)))
x=x.view(-1,16*5*5)
x=F.relu(self.fc1(x))
x=F.relu(self.fc2(x))
x=self.fc3(x)
return x
def main():
# Initialize model
model = TheModelClass()
#Initialize optimizer
optimizer=optim.SGD(model.parameters(),lr=0.001,momentum=0.9)
#print model's state_dict
print('Model.state_dict:')
for param_tensor in model.state_dict():
#打印 key value字典
print(param_tensor,'\t',model.state_dict()[param_tensor].size())
#print optimizer's state_dict
print('Optimizer,s state_dict:')
for var_name in optimizer.state_dict():
print(var_name,'\t',optimizer.state_dict()[var_name])
if __name__=='__main__':
main()
















 980
980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









