







fastai论坛中的目标检测内容:
- Search results for 'object detection' - fast.ai Course Forums
- Part 2 Lesson 9 wiki - Part 2 & Alumni (2018) - fast.ai Course Forums 2018 lesson9 wiki
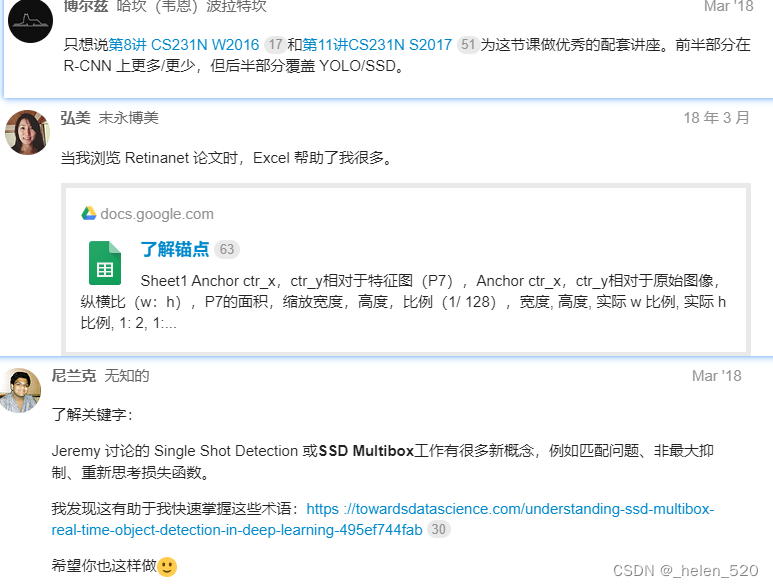
- Overwhelmed by the sheer number of posts and replies. What can I do?
- focus on lectures and a project that is based off the lecture。论坛是一个很好的资源,但它们只有在您解决自己的问题时才会有所帮助。阅读长线程中的每条消息并不重要,而是使用右上角的搜索功能来查找对您有帮助的信息。
- Don’t treat the forum like your ‘Facebook’ feed by routinely scroll through the posts and replies 不要像读社交软件的推送一样来阅读forum。
- I am not too sure if this is a symptom of FOMO (Fear Of Missing Out) 害怕错过些啥的心理。我认为有一些做法可以帮助我们克服 FOMO。
- I learn to navigate the forum from noise-to-signal. I think there are many redundant threads and threads that are supposed to be in a better category.
- 学会从noise-to-signal来导航论坛上的内容。论坛上还有很多冗余的threads,以及有些线程应该在别的更好的分类中。
- 也许 Summarize This Topic会有用。
- https://forums.fast.ai/t/whoah-what-happened-to-these-forums/6906
- radek的帖子:
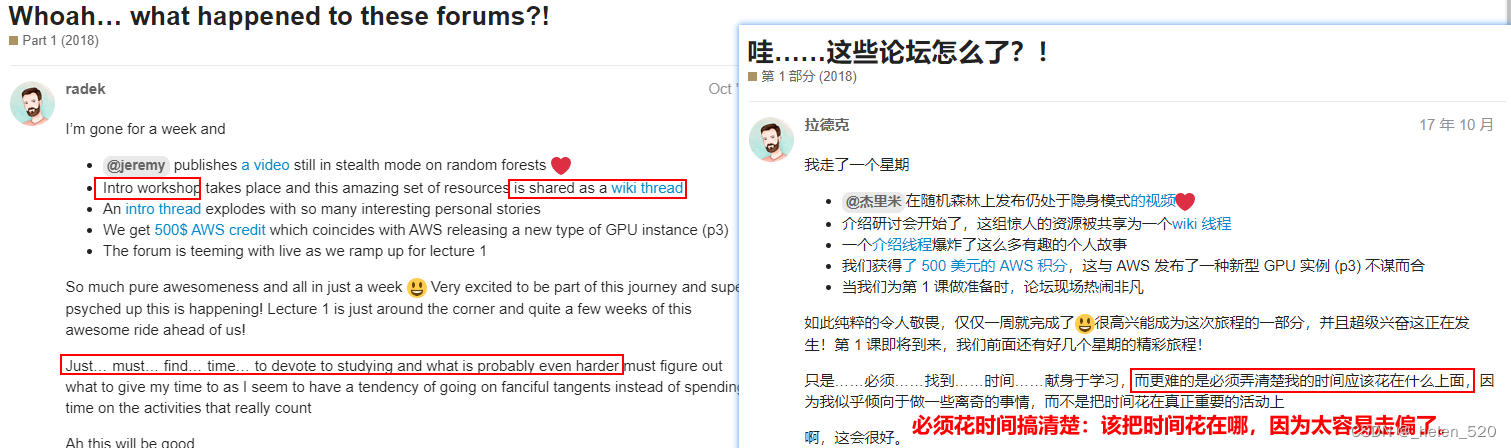


- John von Neumann allegedly once said "Young man, in mathematics you don't understand things. You just get used to them." I
- 冯诺依曼说:你根本不懂数学,你只是习惯了。(颢语录)
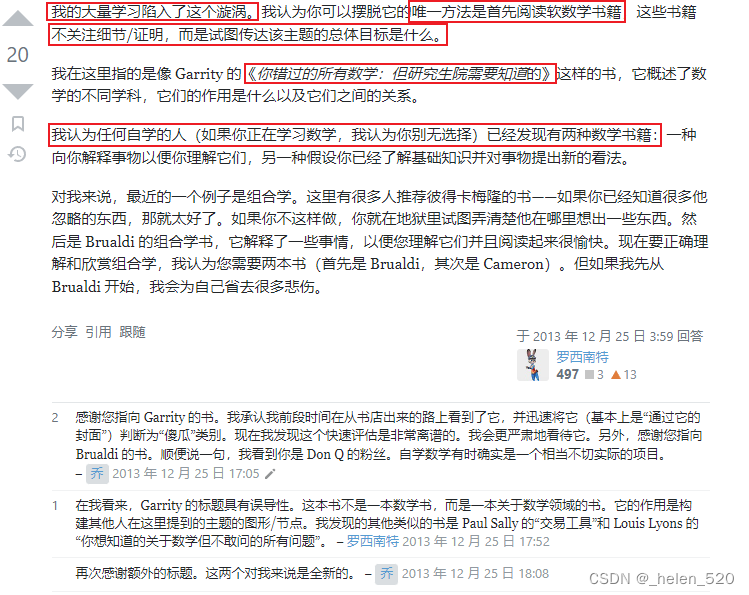
- 关于兔子洞问题的讨论:





一、fastai计算mAP值的程序段
def nms(boxes, scores, overlap=0.5, top_k=100):
keep = scores.new(scores.size(0)).zero_().long()
if boxes.numel() == 0: return keep
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
area = torch.mul(x2 - x1, y2 - y1)
v, idx = scores.sort(0) # sort in ascending order
idx = idx[-top_k:] # indices of the top-k largest vals
xx1 = boxes.new()
yy1 = boxes.new()
xx2 = boxes.new()
yy2 = boxes.new()
w = boxes.new()
h = boxes.new()
count = 0
while idx.numel() > 0:
i = idx[-1] # index of current largest val
keep[count] = i
count += 1
if idx.size(0) == 1: break
idx = idx[:-1] # remove kept element from view
# load bboxes of next highest vals
# import pdb
# pdb.set_trace()
# https://blog.csdn.net/TonG_L/article/details/115239156 解决此处的报错问题
# torch.index_select(x1, 0, idx, out=xx1)
# torch.index_select(y1, 0, idx, out=yy1)
# torch.index_select(x2, 0, idx, out=xx2)
# torch.index_select(y2, 0, idx, out=yy2)
xx1 = torch.index_select(x1, 0, idx)
yy1 = torch.index_select(y1, 0, idx)
xx2 = torch.index_select(x2, 0, idx)
yy2 = torch.index_select(y2, 0, idx)
# store element-wise max with next highest score
xx1 = torch.clamp(xx1, min=x1[i])
yy1 = torch.clamp(yy1, min=y1[i])
xx2 = torch.clamp(xx2, max=x2[i])
yy2 = torch.clamp(yy2, max=y2[i])
w.resize_as_(xx2)
h.resize_as_(yy2)
w = xx2 - xx1
h = yy2 - yy1
# check sizes of xx1 and xx2.. after each iteration
w = torch.clamp(w, min=0.0)
h = torch.clamp(h, min=0.0)
inter = w*h
# IoU = i / (area(a) + area(b) - i)
rem_areas = torch.index_select(area, 0, idx) # load remaining areas)
union = (rem_areas - inter) + area[i]
IoU = inter/union # store result in iou
# keep only elements with an IoU <= overlap
idx = idx[IoU.le(overlap)]
return keep, count
import numpy as np
# from fastai import *
# from fastai.callbacks import *
# md model这部分很难弄,所以直接放到代码中去
anchors = anchors.to(device)
size = sz # batch_size
id2cats=['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse',
'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']
def get_y(bbox,clas):
bbox = bbox.view(-1,4)/size
bb_keep = ((bbox[:,2] - bbox[:,0])>0.).nonzero()[:,0]
return bbox[bb_keep], clas[bb_keep]
def get1preds(b_clas,b_bb,bbox,clas,thresh=0.25):
bbox,clas = un_pad(bbox, clas)
# import pdb
# pdb.set_trace()
a_ic = act_to_bbox(b_bb, anchors)
clas_pr, clas_ids = b_clas.max(1)
conf_scores = b_clas.sigmoid().t().data
out1,out2,cc = [],[],[]
for cl in range(conf_scores.size(0)-1):
cl_mask = conf_scores[cl] > thresh
if cl_mask.sum() == 0: continue
scores = conf_scores[cl][cl_mask]
l_mask = cl_mask.unsqueeze(1).expand_as(a_ic)
boxes = a_ic[l_mask].view(-1, 4)
ids, count = nms(boxes.data, scores, 0.4, 50)
ids = ids[:count]
out1.append(scores[ids])
out2.append(boxes.data[ids])
cc.append([cl]*count)
cc = T(np.concatenate(cc)) if cc != [] else None
out1 = torch.cat(out1) if out1 != [] else None
out2 = torch.cat(out2) if out2 != [] else None
return out1,out2,cc
def count(L):
result = collections.defaultdict(int)
if L is not None:
for x in L:
result[x] += 1
return result
from ipywidgets import FloatProgress
from IPython.display import display
def multiTPFPFN(md:ImageDataBunch):
n = 40
threshes = np.linspace(.05, 0.95, n, endpoint=True)
tps,fps,fns = np.zeros((n,len(id2cats))),np.zeros((n,len(id2cats))),np.zeros((n,len(id2cats)))
prog = FloatProgress(min=0,max=len(md.valid_dl))
display(prog)
for data in md.valid_dl:
x,y = data
# x,y = V(x),V(y)
pred = learn.model(x)#预测结果
for idx in range(x.size(0)):
bbox,clas = un_pad(y[0][idx],y[1][idx])#unpad the target
# import pdb
# pdb.set_trace()
p_scrs,p_box,p_cls = get1preds(pred[1][idx],pred[0][idx],bbox,clas,threshes[0])
overlaps = to_np(jaccard(p_box,bbox.data))
overlaps = np.where(overlaps > 0.5, overlaps, 0)
# import pdb
# pdb.set_trace()
clas, np_scrs, np_cls = to_np(clas.data),to_np(p_scrs), to_np(p_cls)
for k in range(threshes.shape[0]):
new_tp = collections.defaultdict(int)
for cls in list(set(clas)):
msk_clas = np.bitwise_and((clas == cls)[None,:],(np_cls == cls)[:,None])
ov_clas = np.where(msk_clas,overlaps,0.)
mx_idx = np.argmax(ov_clas,axis=1)
for i in range(0,len(clas)):
if (clas[i] == cls):
keep = np.bitwise_and(np.max(ov_clas,axis=1) > 0.,mx_idx==i)
keep = np.bitwise_and(keep,np_scrs > threshes[k])
if keep.sum() > 0:
new_tp[cls] += 1
count_pred = count(np_cls[np_scrs > threshes[k]])
count_gt = count(clas)
for c in range(len(id2cats)):
tps[k,c] += new_tp[c]
fps[k,c] += count_pred[c] - new_tp[c]
fns[k,c] += count_gt[c] - new_tp[c]
prog.value += 1
return tps, fps, fns
def mAP(md:ImageDataBunch):
tps, fps, fns = multiTPFPFN(md)#先计算各个类别的tp,fp,fn
def plot_prec_recall(clas):
prec = np.where(tps[:,clas] + fps[:,clas] != 0, tps[:,clas]/(tps[:,clas] + fps[:,clas]), 1)
recal = np.where(tps[:,clas] + fns[:,clas] != 0, tps[:,clas]/(tps[:,clas] + fns[:,clas]), 1)
plt.plot(recal,prec)
def avg_prec(clas):
precisions = np.where(tps[:,clas] + fps[:,clas] != 0, tps[:,clas]/(tps[:,clas] + fps[:,clas]), 1)
recalls = np.where(tps[:,clas] + fns[:,clas] != 0, tps[:,clas]/(tps[:,clas] + fns[:,clas]), 1)
prec_at_rec = []
for recall_level in np.linspace(0.0, 1.0, 11):
try:
args = np.argwhere(recalls >= recall_level).flatten()
prec = max(precisions[args])
except ValueError:
prec = 0.0
prec_at_rec.append(prec)
return np.array(prec_at_rec).mean()
S = 0
for i in range(len(id2cats)):
S += avg_prec(i)
return S/len(id2cats)
def intersection(box_a,box_b):
min_xy = torch.max(box_a[:,None,:2],box_b[None,:,:2])
max_xy = torch.min(box_a[:,None,2:],box_b[None,:,2:])
inter = torch.clamp(max_xy-min_xy,min=0)
return inter[:,:,0] * inter[:,:,1]
def get_size(box):
return (box[:,2]-box[:,0]) * (box[:,3] - box[:,1])
def jaccard(box_a,box_b):
inter = intersection(box_a,box_b)
union = get_size(box_a).unsqueeze(1) + get_size(box_b).unsqueeze(0) - inter
return inter/union
def T(a, half=False, cuda=True):
"""
Convert numpy array into a pytorch tensor.
if Cuda is available and USE_GPU=True, store resulting tensor in GPU.
"""
if not torch.is_tensor(a):
a = np.array(np.ascontiguousarray(a))
if a.dtype in (np.int8, np.int16, np.int32, np.int64):
a = torch.LongTensor(a.astype(np.int64))
elif a.dtype in (np.float32, np.float64):
a = to_half(a) if half else torch.FloatTensor(a)
else: raise NotImplementedError(a.dtype)
if cuda:
a = to_gpu(a)
return a
def to_gpu(x, *args, **kwargs):
'''puts pytorch variable to gpu, if cuda is available and USE_GPU is set to true. '''
return x.cuda(*args, **kwargs) if True else x二、VOC数据集
两个文件夹:只有VOC2007的,以及VOC2007&VOC2012(VOCdevkit 开发包)
- PASCAL_VOC里面有json格式的标注文档,分为train, val, test
- pascal_2007里面是5000张图片。

















 2501
2501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









