






2023-09-01周五 更新:revisit
- 为什么loss下降的不多了,后面的epoch中(当然了,6个样本,指望loss怎么工作?),但是神奇的是:acc在valid上是怎么增加的??
- 是不是网络的loss虽然在微调,样本太少导致的,但是实际上还是在向有利的acc上前进!
- 那么此时调整的最后的分类器,还是特征提取呢?
- 会不会是在调整分类器呢?毕竟只有6个训练样本
VGG+Imagenette预训练+迁移学习,6个训练样本
kaggle的dogs vs cats数据集:
- 博客:https://medium.com/@radekosmulski/can-we-beat-the-state-of-the-art-from-2013-with-only-0-046-of-training-examples-yes-we-can-18be24b8615f
- 代码:GitHub - radekosmulski/dogs_vs_cats
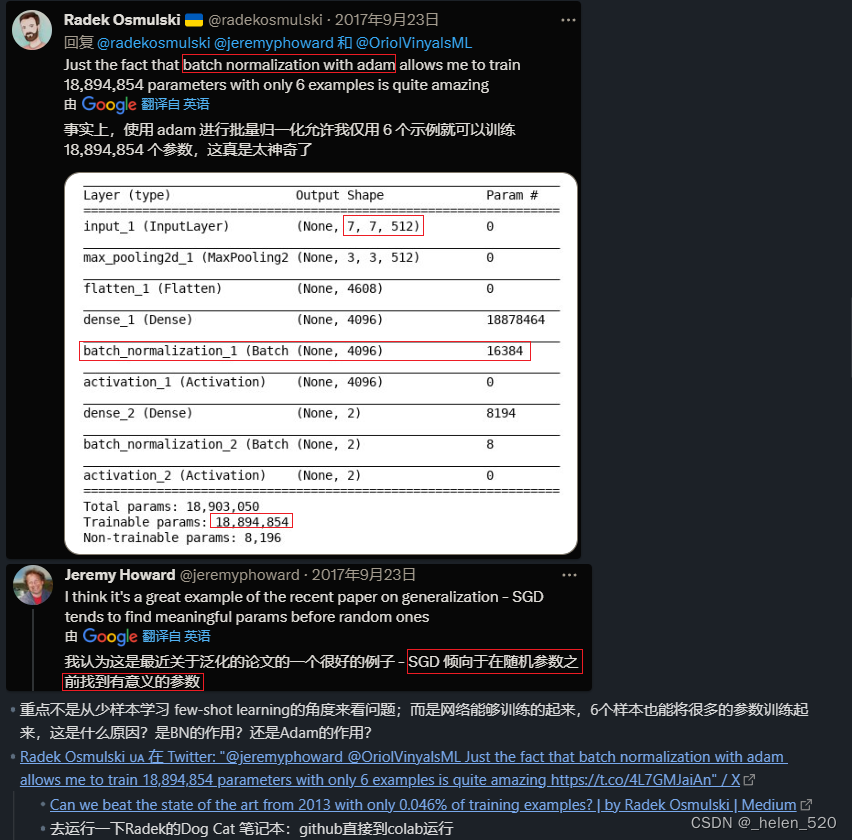
结论:6个样本作为训练,就可以训练1800W个参数
- VGG16 lr=1e-4, Adam优化器:从头开始训练,训练所有参数
- 很快train-loss=0,acc比乱猜还差;乱猜也有50%的概率撒。
- 肯定啊:就6个样本,学习个毛线啊!!!那么多参数,6个样本学习1亿个参数,咋个可能呢!!
- VGG16-Radek's net:7*7的max pool层,减少了大部分的全连接的参数量;模型减小到了65M;loss不会到0了,但是网络基本不动了!!
loss到0和不到0,两回事哦! - 加入imagenette的预训练权重:loss开在0.384不动了,但是acc基本80%
- 把feature层,也就是VGG backbone给冻住:只训练后面的分类层,acc明显增加了好多!但loss还在没动。
- Radek源代码使用keras做的,然后默认的keras设置进行训练的:loss一直在下降,acc的状态跟我的差不都!!
- 不知道他的loss怎么一直保持下降的?有什么秘诀呢?
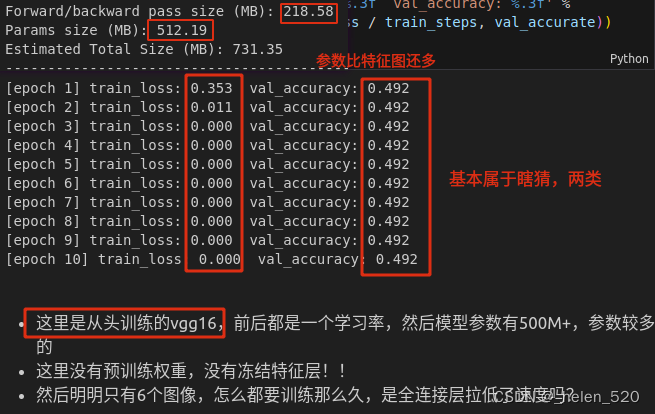

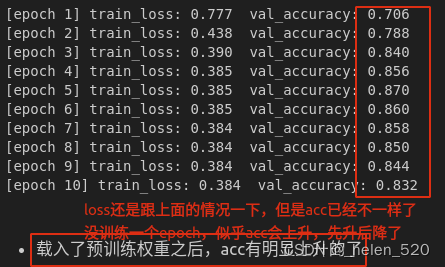
迁移学习的巨大作用

小样本6个:如何做到小样本学习的?
- 网络如何能正常工作?不过拟合?loss会不会继续下降?验证集acc怎么样?
- 应该是得益于迁移学习,才能够在极少的样本小,acc还能达到80~90%的,数据基本一致!
- 那也就是其他情况下,如果迁移做的不好的话,应该是数据不适配!















 492
492











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









