






论文链接: Right Question is Already Half the Answer: Fully Unsupervised LLM Reasoning Incentivization
一、背景
目前增强LLM推理能力的主要方法是通过RL的监督微调,缺点:严重依赖于外部监督(标记的推理轨迹、验证后的黄金答案和额外与训练好的模型等)——>耗时和expensive。
之前的方法主要是①通过自一致性来构造伪数据且部署微调——>有限且有崩溃的风险;②PFPO(将解决方案的标签框架为针对测试用例的评估,) ——>仍需要指令微调数据和先进LLM的信号初始RL;③使用自生成的数据和强化学习来构建自奖励推理模型——>依赖于ground-truth验证器通过拒绝采样获得自校正推理轨迹。
| 方法 | 核心机制 | 优点 | 局限性 |
| 自一致性+微调 | 通过多次采样选择一致答案,构造伪标签进行微调 | 减少对真实标签的依赖 | 性能提升有限,存在模型崩溃风险 |
| PFPO | 使用测试用例评估答案,结合自一致性和RL优化 | 能利用伪反馈提高性能,适合结构化任务 | 依赖指令微调数据和先进LLM信号,计算成本高 |
| 自奖励+拒绝采样 | 使用测试用例评估答案,结合自一致性和RL优化 | 支持自校正推理,性能较强 | 依赖指令微调数据和先进LLM信号,计算成本高 |
能否设计一种机制,以完全无监督的方式,有效激发和提升 LLM 内在的推理能力?
二、贡献
- 熵最小化策略优化(EMPO),实现了无监督的LLM推理增强
- 使用语义熵作为内在信号知道LLM推理,证明了语义上和模型准确率的负相关性
- 证明了EMPO有效性的原理(源于在预训练中学习到的持续选择和优先考虑强大的、预先存在的推理途径的增强能力,而不是灌输基本的新推理技能)
三、主要方法
EMPO 的核心思想是利用模型输出的语义一致性作为内在的学习信号 具体来说,通过持续最小化 LLM 在处理无标签用户查询时,其生成响应在潜在语义空间中的预测熵,来引导模型优化。其基本直觉是:一个推理能力强的模型,对于同一个问题,其多次生成的答案在语义层面上应当高度一致,表现为较低的语义熵。
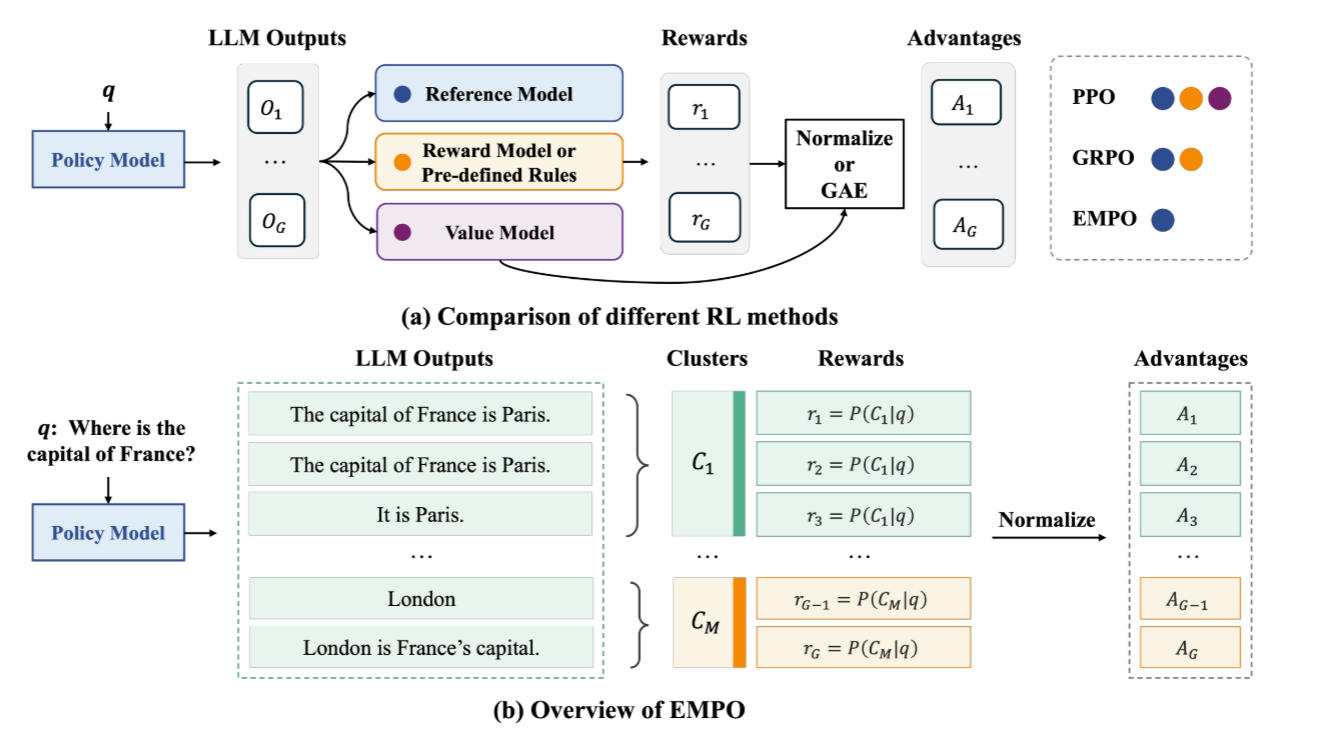
摆脱了GRPO建立在能够获得可靠的、基于外部监督(标准答案 a)的奖励 r_i 之上的依赖。
3.1 语义熵
语义熵主要步骤:①采样②语义聚类③概论估计④熵计算
其中语义聚类如何判断等价(数学推理任务: 使用正则表达式精确提取最终答案;自由形式推理任务: 使用一个小型验证模型判断两个输出的最终答案是否“双向蕴含”(即语义等价));
概率估计采用采样结果中的频率近似;
熵值计算:语义簇概率分布的香农熵
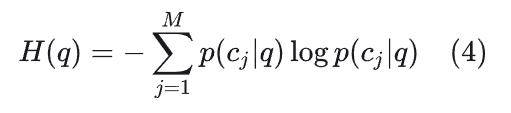
3.2 EMPO:熵最小化策略优化
EMPO 的关键创新在于其奖励 r_i 的定义。不同于 GRPO 依赖外部验证,EMPO 将第 i 个输出 o_i 的奖励 r_i 定义为其所属语义簇 c_j 的估计概率 (似然度),如果输出o_i属于更高频的表明更高的奖励。
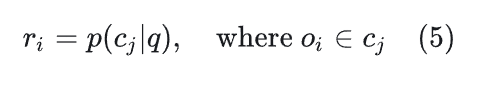
优化目标:引入熵阈值过滤,提高稳定性(KL散度可能会限制模型探索更优的输出空间)。(1) 维持探索和多样性;(2) 避免Reward Hacking(避免LLM通过生成简单和重复答案获得低熵)
KL散度通常用于确保策略更新不会偏离参考策略太远,从而避免训练过程中的不稳定性或过拟合。
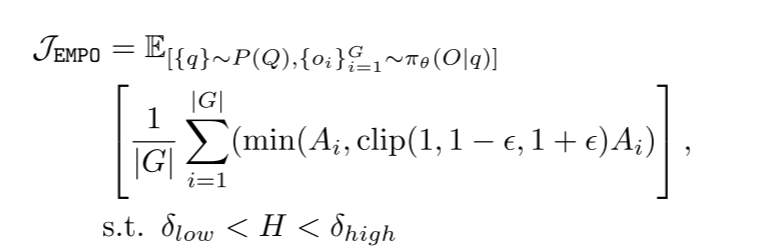
其中Ai为优势,计算方法如下:
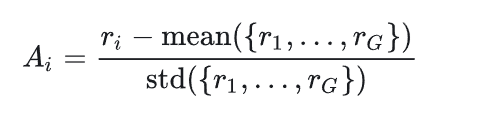
四、实验与实验分析
4.1 实验设置
评估:所有模型均被要求进行逐步推理、基于零样本提示和贪婪解码【选择当前时间步概率最高的 token(单词或子词)作为输出,而不考虑后续 token 的影响】实现的
训练数据:NuminaMath-CoT(数学)和NaturalReasoning(自然语言推理)。
评估基准:(1) 数学:MATH, Minerva Math, OlympiadBench, AMC23和 AIME24;(2) MMLU-Pro和GPQA。
- 数学任务: 报告 Pass@1 准确率。
- 自然语言任务 (MMLU-Pro): 报告多项选择准确率。
- 自然语言任务 (TrivialQA): 报告精确匹配 (EM) 率。
Open-Instruct 是一个开源的指令微调框架,旨在通过监督学习(Supervised Fine-Tuning, SFT)优化大语言模型(LLM)的指令遵循能力和任务性能。
4.2 实验结果
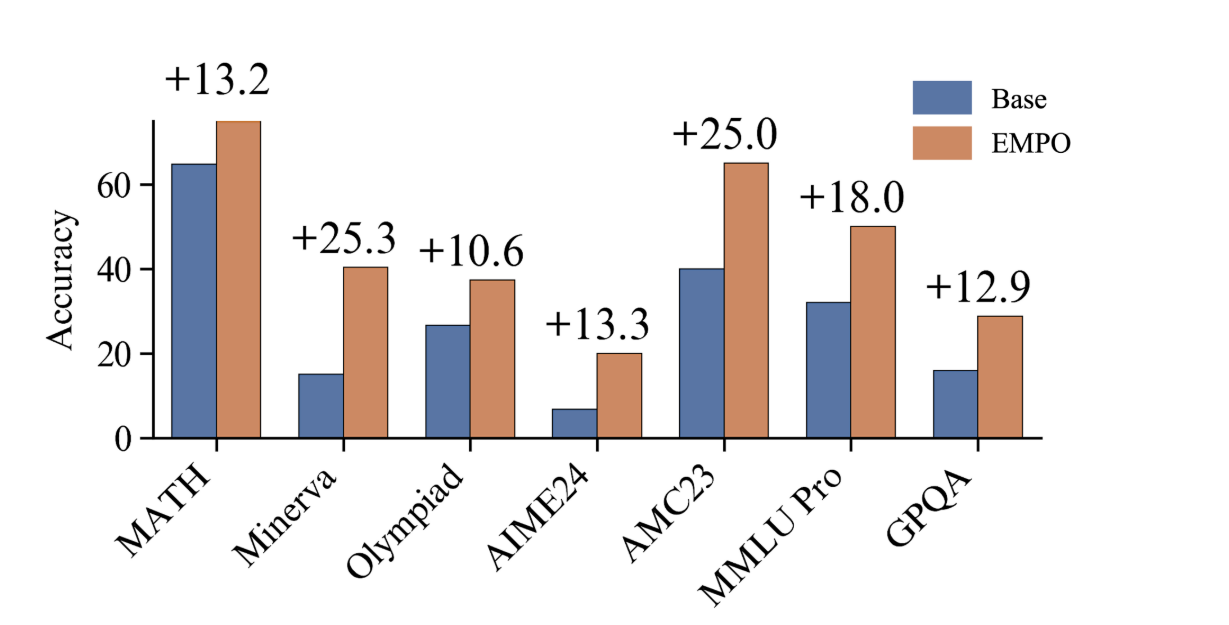
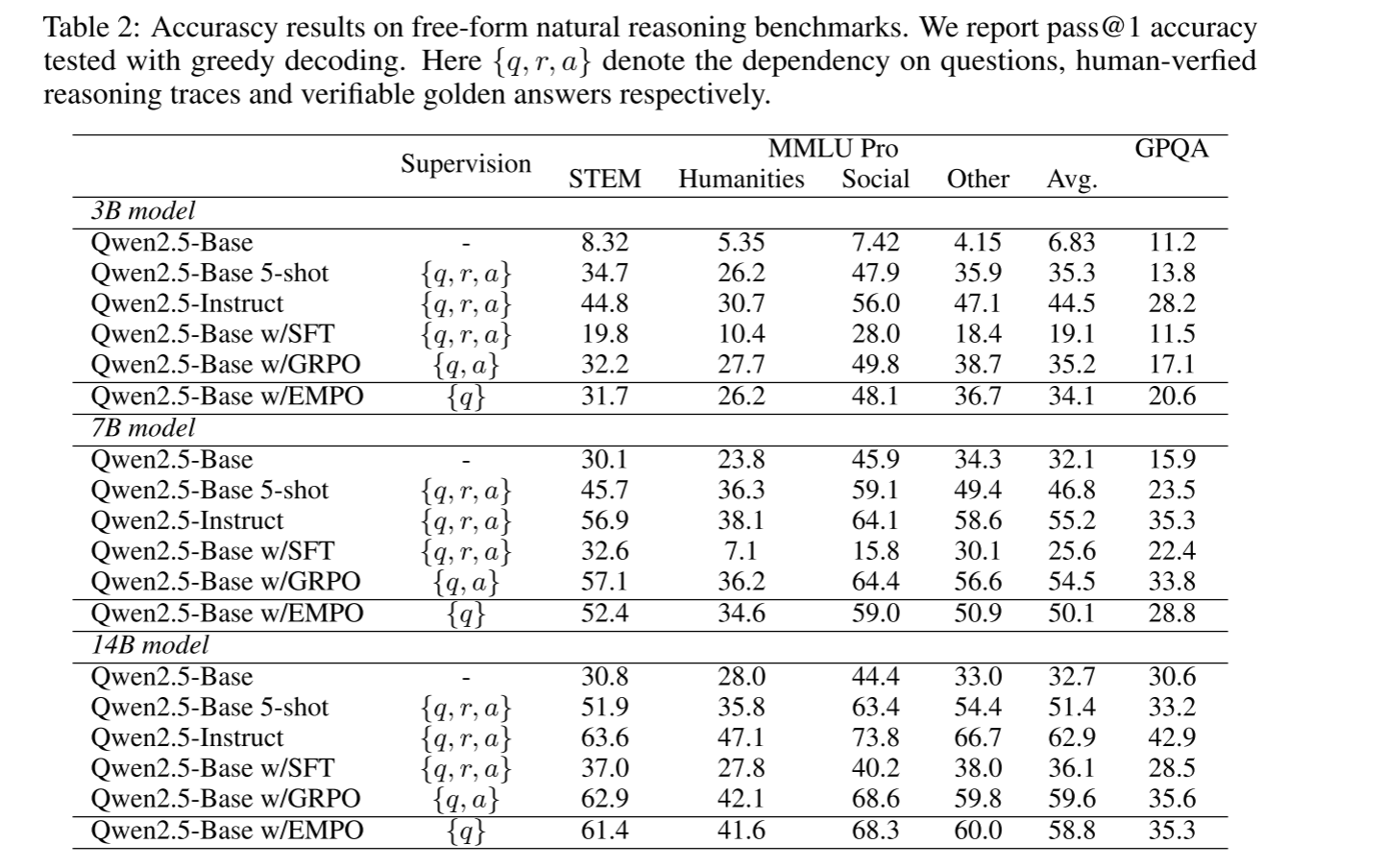
在数学推理方面对比base模型获得了显著提升,而且和GRPO等非无监督学习的效果一致,或者超越。

其次在自然语言推理任务中,在MMLU-Pro和TrivialQA数据中也取得了非常良好的效果。除此之外,模型有时会展现出类似“顿悟”的自我反思【其他安全相关论文中也显示出了同样的自我反思】:在没有外部纠正信号的情况下,模型能够修正自己先前迭代中可能存在的错误思路,并最终输出正确的推理和答案。
也验证了语义熵和训练的准确率上存在负相关,证明了降低输出语义的不确定性有助于提高推理的准确性。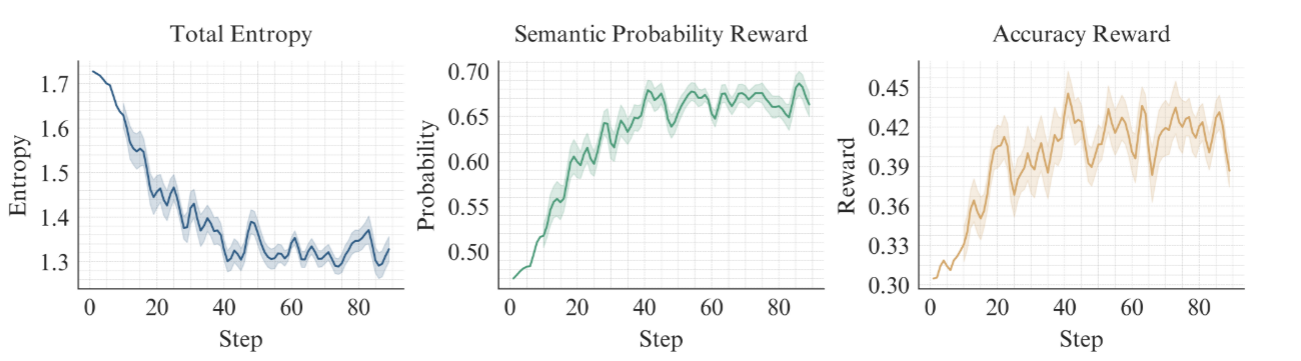
五、讨论与思考
amazing : 强化学习并不会改变LLM固有的推理能力,表明了基本推理途径在很大程度是预先存在的。RL和本文提出的EMPO,主要是改进模型有效访问、优先排序和一致选择这些潜在推理模式的能力,而不是灌输基本的新模式。 所以改进已有LLM主要是引导LLM去使用这些技能(在训练的过程中已经存在了)。
数据以及问题答案的复杂不一致性——>聚类质量问题
EMPO 效果高度依赖预训练 Base 模型本身蕴含的推理潜力。
自然语言推理任务聚类质量依赖于小验证模型
由于只对比最终的"\boxed{}"的结果进行聚类——>难以区分正确和错误的推理路径
扩展到多模态数据集推理
by whx

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









