







今天来讨论一个话题,Oncall与稳定性。为什么要有Oncall,Oncall应该如何保障稳定性,Oncall的日常守则有哪些?

1 为什么要有Oncall呢?
我们可以从日常生活中寻找答案,大家肯定在晚上去过医院,那么应该去哪里呢,答案是急诊;医院的oncall制度的目的是最快的速度来保障病人的生命安全和健康。警察的oncall制度是什么110,警察的oncall目的最快的速度来保障社会的稳定;军队的oncall制度的目的是最快的速度来保障国家的安全。那么程序员的oncall是干什么呢,最快的速度来保障系统的稳定。
2 Oncall最重要的是什么?
我们可以看到Oncall最重要的是什么呢?是稳定。稳定是一切的基础,没有一个稳定的环境,无论社会,还是系统。如果一个系统的稳定性无法达到两个9以上,这个系统就只能称之为玩具了。
3 怎么样算稳定呢?
一个系统怎么样算稳定呢,看看系统的对立面故障。我们肯定听过各种指标比如SLA等等,比如发现时间,恢复时间,平均故障间隔时间(MTBF):是指两个相邻故障间的时间的平均值;平均故障修复时间(MTTR):是指系统故障修复时间的平均值。
我的理解完全不用纠结和关心这些指标,没有任何实际意义,简单来说就一句话,故障越少、影响越小、系统就越稳定。
4 最为Oncall应该如何做呢? 我整理总结了9条经验。
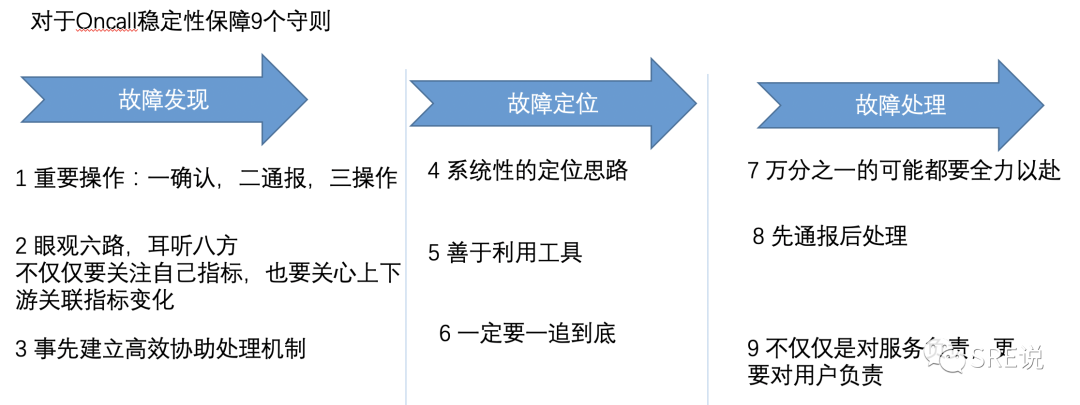
1 重要操作:一确认,二通报,三操作
Case1:有一个团队的同学上线了一个错误的策略会影响到上游业务的指标,但是这个同学以为是一个正常的操作,没有影响影响,但上游发现之后已经是很多天以后的事情了。故障和影响已经产生。
2 眼观六路,耳听八方不仅仅要关注自己指标,也要关心上下游关联指标变化
Case2:有一个中台团队,上线了几次发现自己的指标正常,没有观察上游的指标,但是上游各种指标都随即出现了异常。这个原因就是作为中后台不仅仅只是局限在自己系统的指标更要关心业务的指标。
3 事先建立高效协助处理机制
Case3: 我记得有一次机房故障之后,所有的服务都跪了,然后机房故障很快就恢复了,但是所有的服务恢复用了8个多小时,原因是出现问题在凌晨,根本不知道哪些服务有影响,该找谁,如何去找。必须事前建立一些高效的处理机制,一旦有事可以快速的响应和处理
4 系统性的定位思路
Case4: 作为Oncall肯定一旦遇到问题就会有些抓瞎,网络问题?接入问题?后端服务的问题?还是中后台的问题?DB问题?如何快速定位到到底是哪层的问题这个是需要有一个全局的定位的思路的,需要来日常在Oncall之前可以把关键指标和边界指标整理出来。
5 善于利用工具
Case5:工欲善其事,必先利其器。对日常的定位工具必须要有系统化的梳理。我在之前写过问题定位的整体思路大家可以参考。
6 一定要一追到底
Case6: 我之前刚工作的时候遇到一个问题,发现不是自己的问题就抛给另一个团队去解决了,后来leader问到底是啥问题,影响是啥,我一问三不知,就受到leader的批评。对于问题一定要一追到底并形成长期有效的机制,彻底解决。而不是发现不是自己的问题就管了。
7 万分之一的可能都要全力以赴
Case7: 最近遇到一次机房电路检修,就是双路市电断电,只有柴发供电,一旦出现故障影响极大;我们就全力以赴,准备了各种预案,并且提前12个小时就启动了来观察各种设备,当然最终结果是0事故。过了几天我们使用云厂商也面临相同的问题,但是没有做任何的预案,而且只是提前两个小时启动柴电,启动后系统很快出现故障,这个时候市电已经断了,最终造成了非常严重的故障。
8 先通报后处理
Case8:作为Oncall最容易迷失的就是一出现问题马上就埋头出处理了,没有做任何的通报,最后老板就问为啥没有看到任何的通报,老板也不清楚。其实这个同学一直在埋头处理并且弄了一晚上。不仅受累而且挨骂,作为Oncall来说不是自己去埋头处理,而是让更多人知道发生了什么,让应该处理的人去处理。
9 不仅仅是对服务负责,更要对用户负责
Case:最近发生了一次故障,就是用户看不到自己的金币了,但是发生故障以后,用户极端恐慌,客服同学电话都被打爆了,影响极差。后来复盘如果当时能有告示出来金币正常,系统维修大家不要紧张,其实影响会小很多。
更多精彩文章欢迎关注微信公众号“SRE说”















 4327
4327











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









