







目录
1.course overview
2.语音辨识
3.
4.
5.
6.
7.
8.
9.
10.
一、Course Overview
- 自然语言
(1)概念
- 人造语言:程序语言,Python、c++
- 自然语言:用于人类互相沟通的语言,eg:中文、英文
(2)语音 audio
- 重要性:很多语言没有具体的文字系统,计算机只能通过语音进行理解
- 复杂性:16k sample points/s,256 possible values/points。因此声音信号的可能性非常大,没有一模一样的声音
(3)文字 text
-
核心任务(6种技术)

应用分别有这些应用speech recognition(语音辨识)、Text-to-Speech Synthesis语音合成、speech separation(将一段多个speaker同时发出的声音信号分离),voices conversion(类似变声器)、Speaker Recognition(判断声音信号的speaker),Keyword Spotting(关键字辨识)、、text generation、机器翻译,syntactic parsing(文法剖析) -
其他技术
- Meta Learning:让机器学习学习的算法。先让模型在很多任务上进行学习,学习目标是找到学习方法,使得在新的任务上进行简单的训练(更少的训练资料,更短的训练时间)就可以有很好的效果

- Learning from Unpaired Data
将图像中的风格迁移应用到语音和文字中。将一种语音/文字视为一种风格,学习输入风格和输出风格之间的映射关系

- Knowledge Graph
通过让机器阅读大量训练资料学习knowledge,让后再讲学到的knowledge应用到其他任务模型中

- Adversarial Attack
(1)语音
判断一段语音信号是不是经过合成或变声;
在语音中加入噪声迷惑机器
(2)文字

- Explainable AI

二、语音辨识
任务:语音信号->文本

输出单位(token)的类别:
- Phoneme:声音信号的基本单位,有点类似音标。但是需要词典(Lexcion音标与词汇的映射)辅助


- Grapheme:字母,文本的最小单位。优点在于不需要Lexcion。对于英文来讲,Grapheme的容量是26个英文字母+空格+标点符号;对于中文,Grapheme是汉字集合,常用字大约在4000+。

- Word:词汇。对于一些语言来讲,词汇的数量过大
- Morpheme:词素。传达含义的最小单位。(获取可以通过老专家或统计)
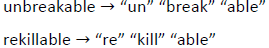
- Bytes:字节。优势在于不依赖于语言,所有语言都可以表示成bytes,数量是256

总结

Grapheme简单易上手,不需要老专家,容易获得;Phoneme跟语音的关系更明确,在语音方面更简单,但是需要更强大的模型将其映射到文字;
语音辨识与其他应用的结合

输入:声音信号(长度为T,纬度为d)

通过一个长度为25ms的滑动窗口提取特征,将声音信号转化成d纬的特征向量(frame),使用不同的策略得到的纬度不同(上图展示了三种策略)。每个窗口之间的间隔是10ms(窗口之间有重叠)意味着1s的声音信号将转化成100个特征向量(100*d) - 语音信号的特征提取过程

Waveform:25ms的声音信号。听起来相同的声音,他们的声音信号可能非常不同
DFT:离散傅里叶变换
spectrogram:频谱图。和声音信号的关联性非常明确,可以通过频谱图猜到声音内容
filter bank:滤波器组(专家设计)
DCT:离散余弦变换

filter bank output成为主流
训练数据量


对比图像
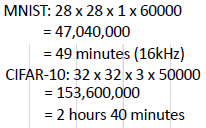
模型使用趋势

八、bert















 776
776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









