







Sensor-Augmented Egocentric-Video Captioning with Dynamic Modal Attention
概要
- 发表:ACMM 2021
- 代码:MMAC
- idea:本文提出了一种新的视频描述任务,以自我为中心的视觉描述(例如第一人称视角、第三人称视角),可以用于更近距离的视觉描述。同时,为了缓解设备等原因可能导致的运动模糊、遮挡等问题,使用传感器进行视觉描述的辅助工具。
在网络设计上,主要是两大模块:AMMT模块用于合并视觉特征 h v h_v hv和传感器特征 h s h_s hs得到合并的特征 h V + S h_{V+S} hV+S,然后将这三种特征( h v , h s , h V + S h_v, h_s, h_{V+S} hv,hs,hV+S)输入到DMA模块中对其进行选择性的注意力学习。然后输入GRU中进行word生成
详细设计
1. 特征提取
- 视觉特征 h V h_V hV:Vgg16
- 传感器特征 h S h_S hS:LSTM(时序)
2. Asymmetric Multi-modal Transformation(AMMT)
实质上是特征合并
出处:FiLM: Visual Reasoning with a General Conditioning Layer,知识点参考feature-wise linear modulation
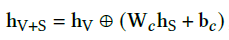
ps:初始化
W
c
=
I
,
b
c
=
0
W_c=I, b_c=0
Wc=I,bc=0,即初始化为concate,随着训练的深入,学习二者的合并特征
注意这里输出的特征是三种特征:
(1) 视觉特征
h
V
h_V
hV
(2)传感器特征
h
S
h_S
hS
(3)合并的特征
h
V
+
S
h_{V+S}
hV+S
- 一些使用不对称的解释
一方面缓解数据冗余可能带来的过拟合;另一方面,传感器数据中有时包含不需要的噪声,因此需要对它进行调节。
3. Dynamic Modal Attention (DMA)
对三种特征进行动态选择注意力
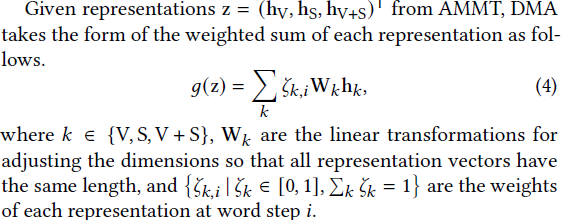
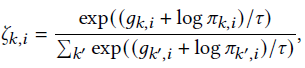

这里使用了Gumbel Softmax
ps:使用三种特征的原因:因为在许多情况下,只使用单一模态是可取的(例如,包含不需要的噪声的传感器数据)。















 1110
1110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









