







Non-Autoregressive Coarse-to-Fine Video Captioning
- 发表:AAAI 2021
- idea:(1)针对推理阶段不能并行,推理效率低的问题使用一种双向解码(在bert中不使用sequence mask)。(2)对于视觉词汇训练不充分(由于视觉词汇数量远小于非视觉词汇)导致生成的描述比较宽泛的问题,考虑使用一种coarse-to-fine的解码方式,先生成主要的视觉词汇,然后基于这个“模板”进行填充和细调
1. Architecture
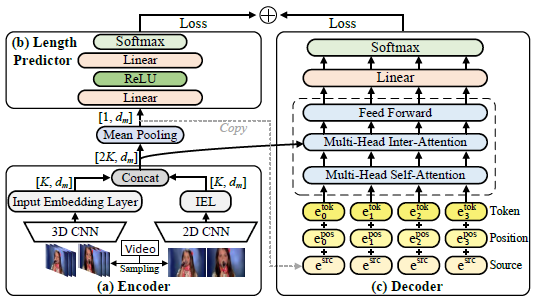
Encoder
对2D、3D特征做以下处理
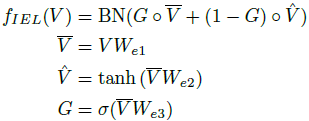
Length Predictor
这里需要预先预测序列的长度L
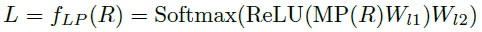
Decoder
- 这里使用了bert,修改了两处:第一不使用sequence mask,这样解码的时候就变成了bi-directional;第二,没看懂,跟随NMT通过整合复制的源信息来增强解码器输入(上图中右侧的虚线)。
- 同样用了完形填空任务。(这里是mask掉 β l \beta_l βl~ β h \beta_h βh的概率)
2. Visual Word Generation
-
生成视觉词汇(动词和名词),在上述decoder的基础上。目标就是将序列中所有不是视觉词汇的单词都mask掉
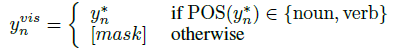
-
优化目标
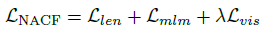
从左到右依次是长度 L L L损失,完形填空损失以及视觉词汇损失
3. Coarse-to-Fine Captioning
这里真的没看懂。。。
就是迭代优化,感觉很繁琐。。。
后期需要这方面的工作再仔细研读研读。。。
4. Experiments
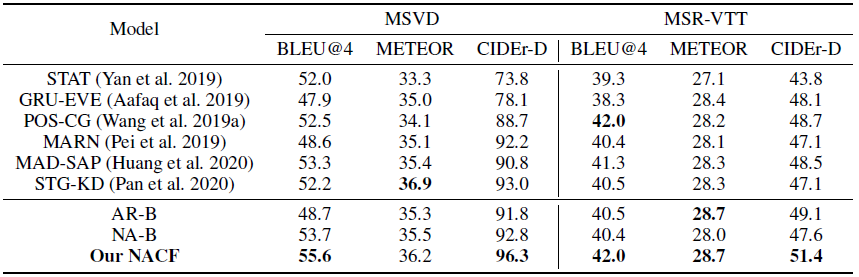















 238
238











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









