









前面简单学习过pyWebio,但是这种类型的只适合简单的小程序,甚至左右布局的方式都没有(也有可能我没找到),目前我现在使用他的应用就只是那个sanger。
现在想学习下Streamlit,特此记录,因为是从头开始,大部分还是根据官方文档来,学习完了之后,才是自己尝试写应用。
Install
#Python 3.7 - Python 3.9
#在使用pip安装时,请保证你经常使用的python和其对应的pip是同一个版本,经常看到有人明明已经安装成功了,但是import的时候,还是报没安装成功。
pip install streamlit
#使用conda安装的话
conda config --add channels conda-forge
conda config --set channel_priority strict
conda install streamlit
#要等好一会,也不知道是我的网速问题还是怎么滴
#最好还是建一个虚拟环境,在里面进行测试运行,毕竟要装120个包,可能会影响到自己原来的包简单的应用
#!/bin/env python
import streamlit as st
import pandas as pd
import numpy as np
#安装完成,没出什么大毛病
DATE_COLUMN = 'date/time'
DATA_URL = ('https://s3-us-west-2.amazonaws.com/streamlit-demo-data/uber-raw-data-sep14.csv.gz')
#缓存机制,再一个函数前使用@st.cache,用户在第二次使用时,可以直接读取。当然,前提是传进去的参数要是一样的。
@st.cache
def load_data(nrows):
data = pd.read_csv(DATA_URL, nrows=nrows)
lowercase = lambda x: str(x).lower()
data.rename(lowercase, axis='columns', inplace=True)
data[DATE_COLUMN] = pd.to_datetime(data[DATE_COLUMN])
return data
# 创建一个文本框,让用户知道数据正在加载
data_load_state = st.text('Loading data...')
# 展示数据的前1000行
data = load_data(1000)
# 告诉用户数据已经加载成功
data_load_state.text('Done! (using st.cache)')
#添加一个单选框,是否要显示表格里面的内容
if st.checkbox('Show raw data'):
st.subheader('Raw data')
st.write(data)
st.subheader('Number of pickups by hour')
hist_values = np.histogram(data[DATE_COLUMN].dt.hour, bins=24, range=(0,24))[0]
#绘制柱状图
st.bar_chart(hist_values)
# Some number in the range 0-23
hour_to_filter = st.slider('hour', 0, 23, 17)
filtered_data = data[data[DATE_COLUMN].dt.hour == hour_to_filter]
st.subheader('Map of all pickups at %s:00' % hour_to_filter)
st.map(filtered_data)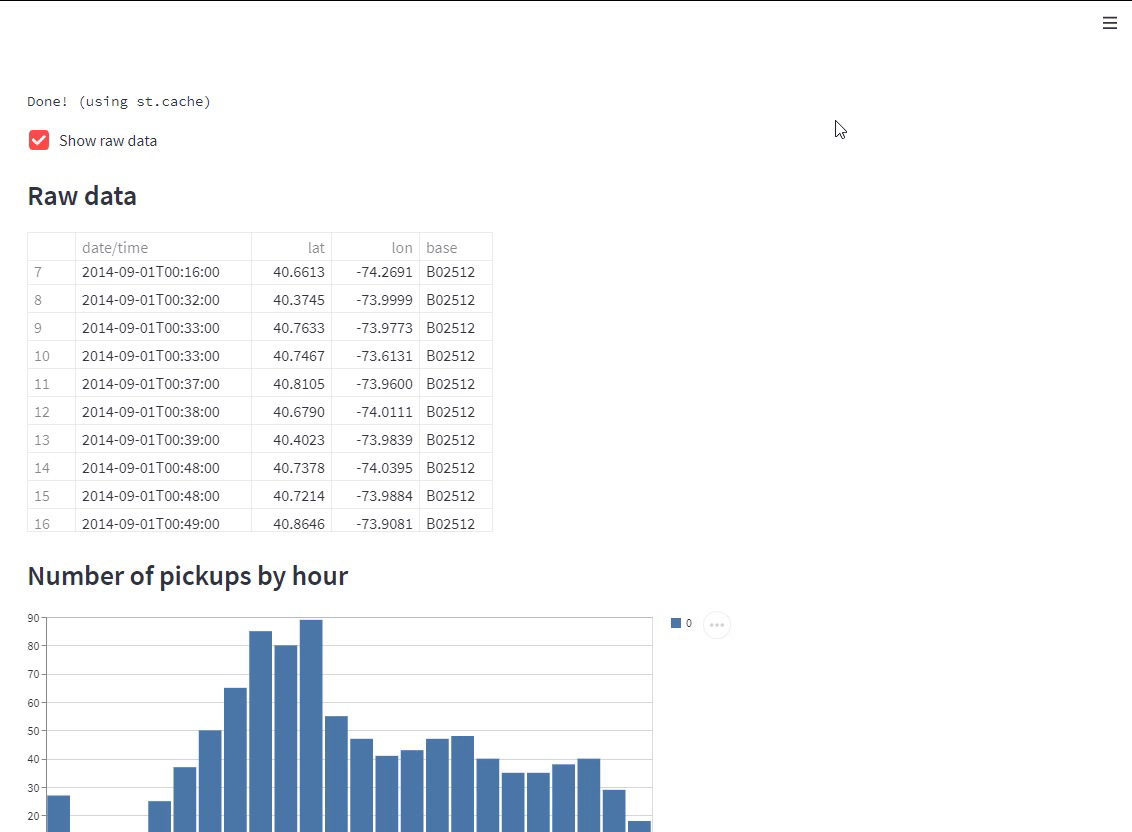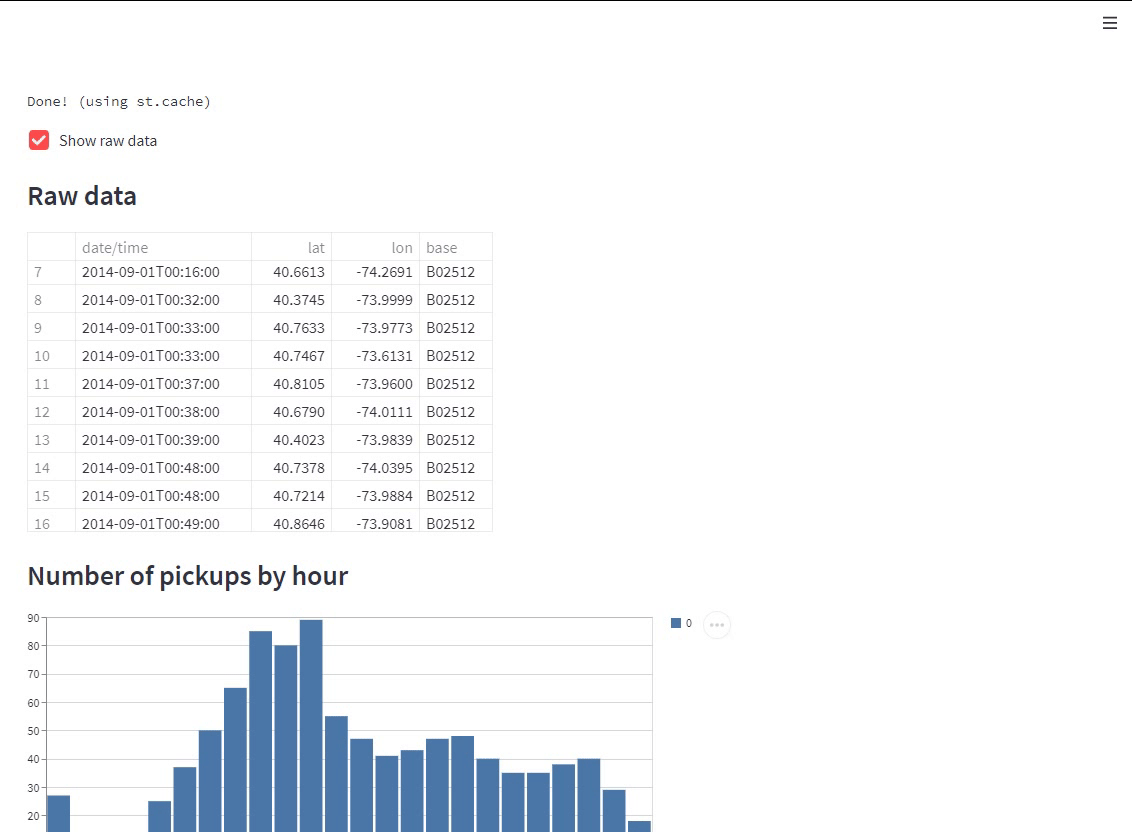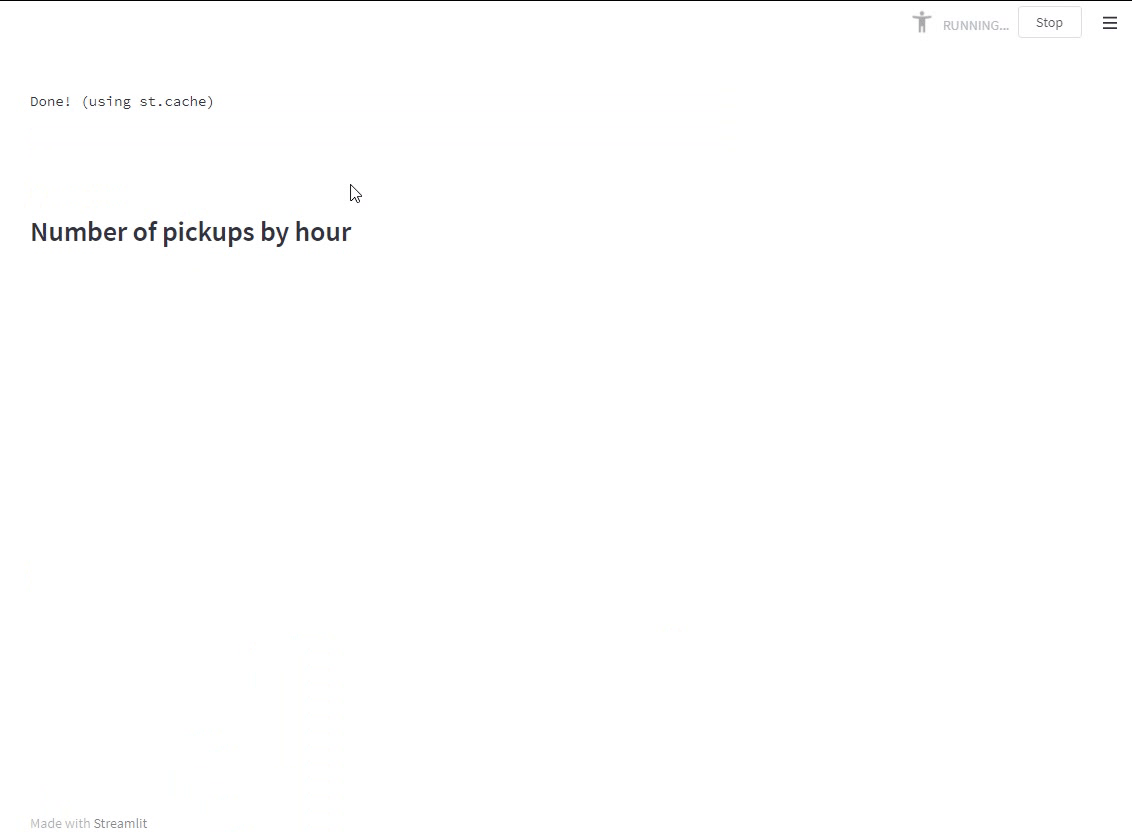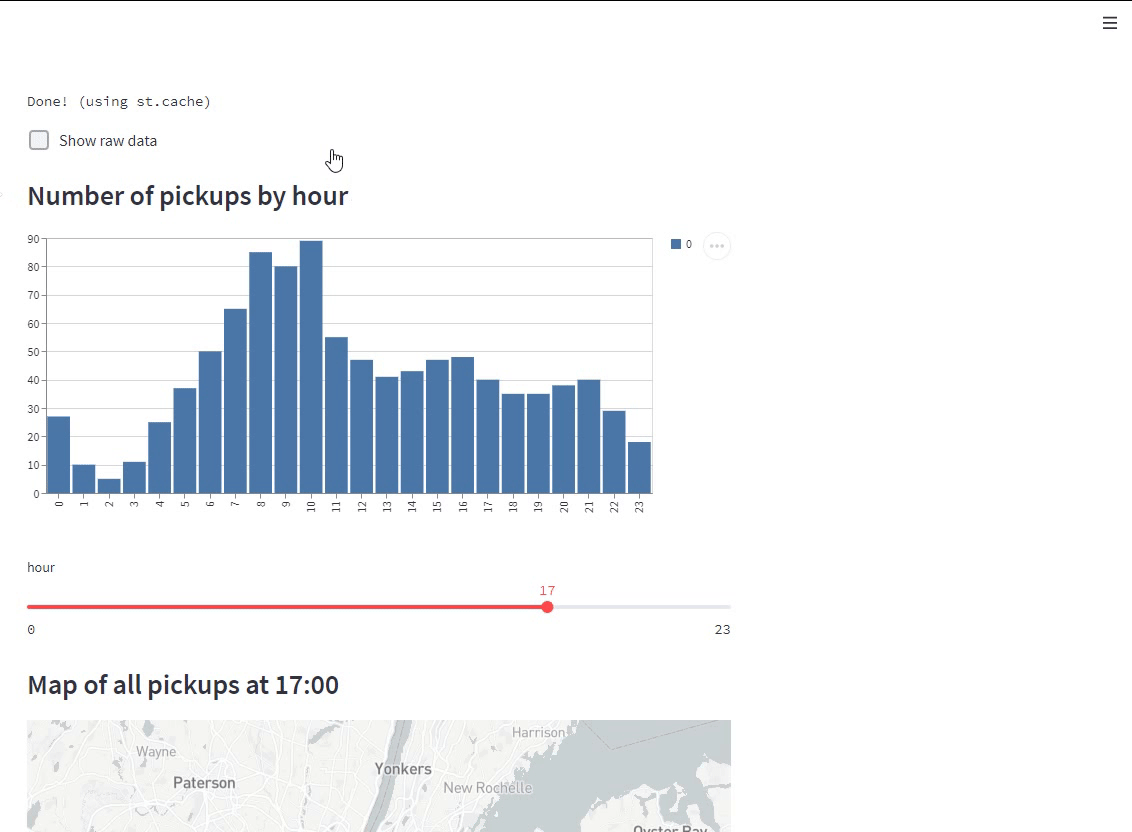
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











