







背景
在现代软件开发和运维实践中,随着系统架构从单体应用向微服务和分布式系统的演进,传统的监控方式已经无法满足复杂系统的故障诊断需求。APM(应用性能监控)、链路追踪(Distributed Tracing)、可观测性(Observability)这三个概念经常被混用或误解,很多技术人员对它们的真实关系和实际应用场景存在困惑。
本文旨在通过深度分析和真实案例,彻底厘清这三者的历史脉络、逻辑关系,并通过一个完整的电商系统故障排查实战,展现现代分布式系统中可观测性体系的实际价值和应用方法。
三者关系:层次关系,而非演进关系
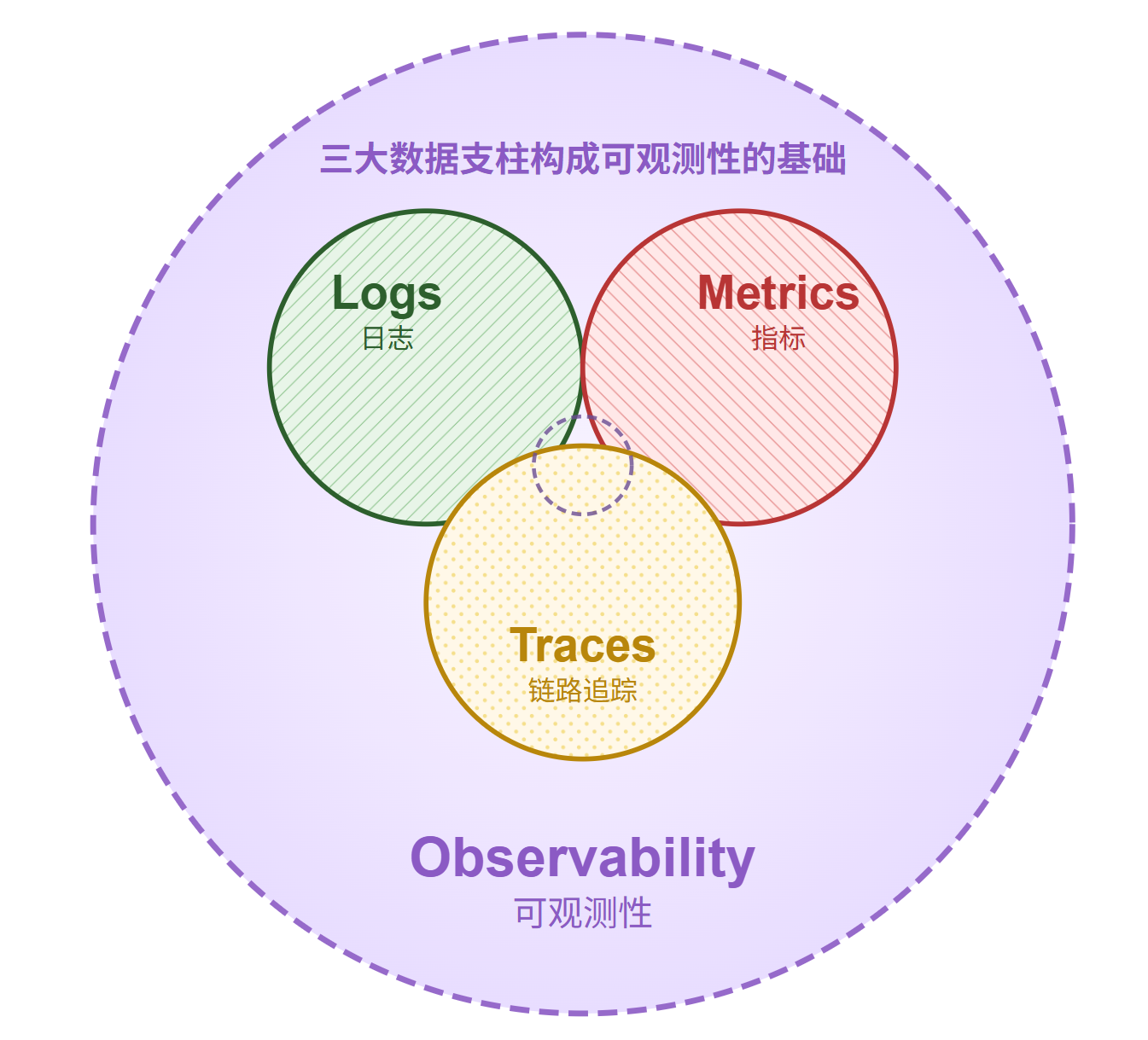
APM、链路追踪、可观测性 - 真实关系是一个目标、支柱与工具的层次结构,而不是简单的时间线演进:
- 目标 (Goal): 可观测性 (Observability) - 我们追求的最终目的,是希望系统具备的一种能够被深入理解和探索的属性
- 数据支柱 (Pillars): 指标 (Metrics)、日志 (Logs)、链路追踪 (Traces) - 构建可观测性的三大核心原材料,是客观存在的遥测数据基石
- 工具/平台 (Tools/Platforms): APM / 可观测性平台 - 用来收集、处理、关联和分析上述三大数据支柱的手段和工作台
历史发展脉络
APM(应用性能监控)- 最早出现
时间:2000年代初期 背景:单体应用时代,主要关注应用本身的性能问题 核心功能:应用响应时间监控、数据库查询性能分析、代码级别的性能瓶颈定位、错误率统计 代表工具:New Relic、AppDynamics、Dynatrace
链路追踪(Distributed Tracing)- 微服务催生
时间:2010年代中期 背景:微服务架构兴起,单个请求跨越多个服务,传统APM无法有效追踪 核心价值:跟踪请求在分布式系统中的完整路径、识别服务间的依赖关系、定位跨服务的性能瓶颈 技术标准:OpenTracing、OpenTelemetry
可观测性(Observability)- 理论升华
时间:2017年左右开始流行 背景:系统复杂度急剧增加,传统监控方法不足以应对未知问题 理论基础:来自控制理论,强调从外部输出推断内部状态
真实关系定位
可观测性:终极目标与系统属性,不是可以"购买"或"安装"的工具,而是通过精心设计赋予系统的一种可以被任意提问和探索的能力
链路追踪:三大数据支柱之一,是分布式语境下的"上下文关联器",与指标、日志平起平坐的基础遥测数据类型,携带因果关系和调用拓扑
APM平台:实现目标的手段,是"工作台"和"分析引擎",核心价值是将三大支柱数据进行智能的关联和整合
真实场景:电商系统订单处理故障排查实战
背景:某知名电商公司的后端程序员老王,负责维护基于Golang微服务架构的电商系统,包括商品浏览、下单、支付等核心功能。
第1步:指标告警触发 - "什么"出了问题
时间:双十一预热期,晚上20:30,正值购物高峰
事件:老王收到Prometheus告警:
ALERT: order-service P99响应时间异常
- 服务: order-service (Golang)
- 时间窗口: 最近5分钟
- 阈值: > 1.5s,实际: 4.2s
- 影响: 用户下单提交接口
- 告警级别: Critical
- 受影响用户: ~2000/分钟
老王的反应:
- 立即打开Grafana监控面板,确认指标趋势
- 观察到从20:25开始,http_request_duration_p99{service="order-service",endpoint="/api/v1/orders/create"}从正常的200ms飙升到4秒+
- 同时发现http_requests_total{status="500"}错误率从0.1%激增到15%
- 运营群里已经炸锅:"用户反馈下单失败,购物车商品提交不了!"
- GMV实时大盘显示订单转化率断崖式下跌
角色分析:
- 指标 (Metrics) 扮演"哨兵"角色,告诉我们**"什么"**出了问题 - 订单服务响应时间异常
- 此时老王只知道症状,但不知道根本原因
- 业务影响巨大:每分钟损失订单可能达到数十万元
第2步:APM平台定位问题边界 - "在哪里"出了问题
工具:公司使用SkyWalking APM平台
老王的操作:
-
1. 登录SkyWalking Dashboard,选择order-service
-
2. 查看服务拓扑图,发现该服务依赖:user-service、product-service、inventory-service、coupon-service、payment-gateway、Redis集群、MySQL主从
-
3. 点击慢链路追踪样本分析
关键发现:随机查看几条耗时超长的Trace:
Trace ID: order_20241127_203156_abc123
总耗时: 4.1s
用户: user_888888 | 商品: iPhone15_256GB | 金额: ¥6999
span1: POST /api/v1/orders/create (order-service) [4.1s]
├─ span2: ValidateUser() -> user-service [45ms]
├─ span3: GetProductInfo() -> product-service [38ms]
├─ span4: CheckInventory() -> inventory-service [3.8s] ⚠️
├─ span5: CalculateCoupon() -> coupon-service [52ms]
├─ span6: CreatePaymentOrder() -> payment-gateway [89ms]
└─ span7: SaveOrderToDB() -> MySQL [76ms]
进一步分析inventory-service的内部调用:
span4: CheckInventory() -> inventory-service [3.8s]
├─ span4.1: ValidateRequest() [12ms]
├─ span4.2: QueryProductStock() -> MySQL [3.7s] ⚠️⚠️
└─ span4.3: UpdateStockCache() -> Redis [45ms]
老王的分析:
- 问题定位明确:瓶颈在inventory-service的库存查询操作
- 具体到MySQL的QueryProductStock()操作耗时3.7秒,占总耗时的90%
- 其他服务调用都正常,排除了用户服务、商品服务、支付网关的问题
角色分析:
- APM平台 是"作战指挥室",汇集所有遥测数据,提供精确的下钻路径
- 链路追踪 (Traces) 是"GPS导航仪",精确定位问题在inventory-service的数据库查询
- 老王现在知道了问题**"在哪里"** - 不是订单服务本身,而是库存服务的数据库操作
第3步:深挖根本原因 - "为什么"出了问题
事件:问题已定位到inventory-service的数据库查询,但为什么会这么慢?
老王的操作:
-
1. 在SkyWalking的链路详情页面,点击耗时3.7秒的span4.2
-
2. 平台自动关联并跳转到ELK日志系统
-
3. 自动筛选条件:service=inventory-service AND trace_id=order_20241127_203156_abc123 AND timestamp=[20:31-20:32]
关键日志发现:
// inventory-service 日志
2024-11-27 20:31:45 ERROR [trace_id=order_20241127_203156_abc123]
MySQL slow query detected in CheckProductStock:
SQL: SELECT stock_quantity, reserved_quantity FROM product_inventory
WHERE product_id = ? AND warehouse_id IN (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
FOR UPDATE
Duration: 3.652s
Rows_examined: 15,000,000
Rows_sent: 10
Lock_wait_timeout: 3.2s
2024-11-27 20:31:45 WARN [trace_id=order_20241127_203156_abc123]
Database connection pool near exhaustion: 95/100 connections in use
Active transactions waiting for locks: 847
2024-11-27 20:31:45 ERROR [trace_id=order_20241127_203156_abc123]
InnoDB lock wait timeout exceeded; try restarting transaction
继续深挖 - 查看数据库相关日志:
-- MySQL slow query log
Time: 2024-11-27T20:31:45.123456Z
Query_time: 3.652134 Lock_time: 3.201567
Rows_sent: 10 Rows_examined: 15000000
SELECT stock_quantity, reserved_quantity FROM product_inventory
WHERE product_id = 'iPhone15_256GB'
AND warehouse_id IN ('WH001','WH002','WH003','WH004','WH005','WH006','WH007','WH008','WH009','WH010')
FOR UPDATE;
-- 表锁等待情况
SHOW ENGINE INNODB STATUS;
-- 发现大量事务等待同一行级锁,热门商品库存记录成为瓶颈
根本原因分析:
// 老王查看 inventory-service 的问题代码
func (s *InventoryService) CheckProductStock(productID string, quantity int) error {
// 问题1:使用行级锁 FOR UPDATE 查询热门商品库存
// 在高并发下,大量请求争抢同一行记录的锁
query := `SELECT stock_quantity, reserved_quantity
FROM product_inventory
WHERE product_id = ? AND warehouse_id IN (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
FOR UPDATE`
// 问题2:查询多个仓库库存,但没有合适的复合索引
// 1500万条库存记录中进行低效查询
rows, err := s.db.Query(query, productID, warehouseIDs...)
if err != nil {
return err
}
// 问题3:事务持有时间过长,没有及时释放锁
time.Sleep(50 * time.Millisecond) // 模拟其他耗时操作
// ...
}
深入分析发现的问题:
-
1. 数据库锁竞争:iPhone15等热门商品在双十一期间并发查询量巨大,FOR UPDATE行锁导致严重排队
-
2. 索引不当:product_inventory表1500万条记录,缺乏(product_id, warehouse_id)复合索引
-
3. 事务设计问题:事务持有锁时间过长,没有快速释放
-
4. 架构设计缺陷:热门商品库存成为单点瓶颈,缺乏水平扩展能力
角色分析:
- 日志 (Logs) 是"现场记录员"和"黑匣子",提供了最关键的证据
- 真相大白:双十一高峰期,热门商品库存查询引发数据库锁等待雪崩
- 这完美回答了**"为什么"**的问题:高并发+锁竞争+索引缺失的完美风暴
第4步:应急处理与验证
老王的分层应急方案:
第一阶段:立即止血(5分钟内)
-
1. 数据库优化:
-- 紧急添加复合索引
CREATE INDEX idx_inventory_product_warehouse ON product_inventory(product_id, warehouse_id);
-- 调整数据库参数
SET GLOBAL innodb_lock_wait_timeout = 10; -- 降低锁等待时间
SET GLOBAL max_connections = 200; -- 增加连接数
-
2. 应用层限流:
// 对热门商品添加限流
rateLimiter := rate.NewLimiter(rate.Limit(100), 200) // 每秒100次,突发200次
第二阶段:架构优化(30分钟内)
// 优化后的库存查询代码
func (s *InventoryService) CheckProductStockOptimized(productID string, quantity int) error {
// 优化1:使用缓存前置,减少数据库压力
if cached := s.getStockFromCache(productID); cached != nil {
if cached.Stock >= quantity {
return nil
}
}
// 优化2:使用读锁而非排他锁,允许并发读取
// 只在真正需要扣减库存时才使用 FOR UPDATE
query := `SELECT stock_quantity, reserved_quantity
FROM product_inventory
WHERE product_id = ? AND warehouse_id = ?
LIMIT 1` -- 优化3:只查询主仓库,避免多仓库复杂查询
var stock, reserved int
err := s.db.QueryRow(query, productID, s.getPrimaryWarehouse()).Scan(&stock, &reserved)
if err != nil {
return err
}
// 优化4:快速判断,只有库存充足时才进入锁定逻辑
if stock-reserved < quantity {
return errors.New("insufficient stock")
}
// 优化5:缩短锁持有时间,独立事务处理
return s.reserveStock(productID, quantity)
}
// 独立的库存预留操作,最小化锁时间
func (s *InventoryService) reserveStock(productID string, quantity int) error {
tx, err := s.db.Begin()
if err != nil {
return err
}
defer tx.Rollback()
// 仅在此处使用 FOR UPDATE,且快速执行
updateQuery := `UPDATE product_inventory
SET reserved_quantity = reserved_quantity + ?
WHERE product_id = ? AND stock_quantity - reserved_quantity >= ?`
result, err := tx.Exec(updateQuery, quantity, productID, quantity)
if err != nil {
return err
}
if affected, _ := result.RowsAffected(); affected == 0 {
return errors.New("stock reservation failed")
}
return tx.Commit()
}
第三阶段:部署与验证(20:50完成)
- 20:45 数据库索引和参数调整完成
- 20:48 新代码热部署到生产环境
- 20:50 开始验证修复效果
验证结果:
Grafana指标监控:
- order-service P99延迟:4.2s → 280ms ✅
- 错误率:15% → 0.2% ✅
- 数据库连接池使用率:95% → 45% ✅
SkyWalking链路追踪:
- inventory-service调用耗时:3.8s → 45ms ✅
- 数据库查询时间:3.7s → 25ms ✅
业务指标:
- 订单转化率快速恢复 ✅
- 用户投诉量断崖式下降 ✅
- GMV损失控制在预期范围内 ✅
角色分析:
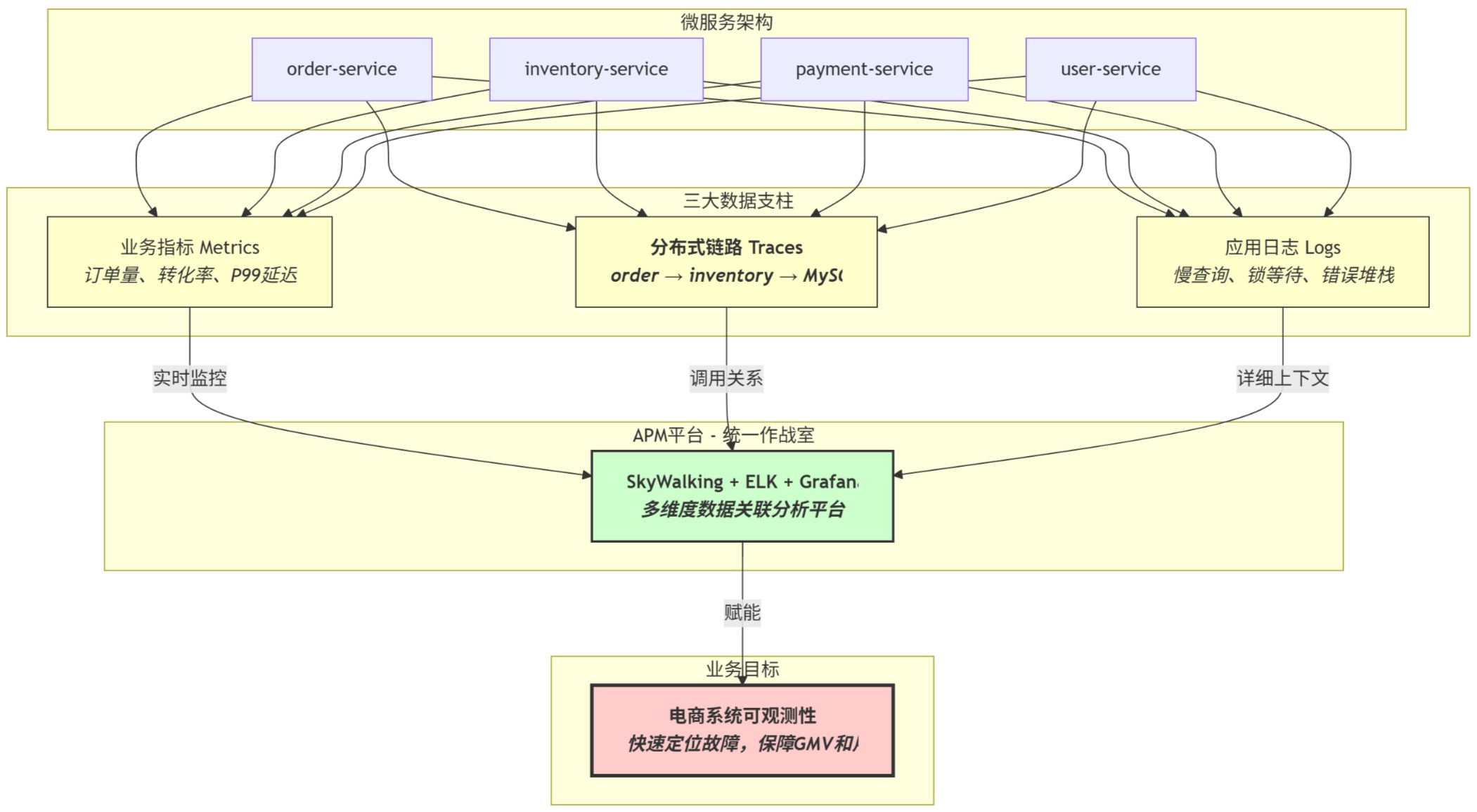
完整的可观测性闭环:指标发现问题 → 链路精确定位 → 日志揭示根因 → 指标验证修复 → 业务数据确认恢复
深度思考:电商场景下的可观测性价值
通过这个真实的双十一故障处理案例,我们深刻认识到:
-
1. 可观测性的商业价值:20分钟的快速定位和修复,避免了数百万元的GMV损失
-
2. 数据支柱的协同效应:指标、链路、日志缺一不可,单一数据源无法完成复杂故障的诊断
-
3. APM平台的核心价值:不是简单的数据收集,而是智能关联和快速下钻能力
电商系统可观测性架构图
总结
可观测性、APM、链路追踪三者并非简单的演进关系,而是目标导向的层次结构:
- 可观测性是我们追求的终极能力 - 让系统具备可被深入理解和探索的属性
- APM平台是实现这种能力的核心工具和工作台
- 指标、日志、链路追踪是支撑可观测性的三大数据支柱
比如在电商这样的高并发、高可用、高价值场景下:
- 时间就是金钱:20分钟的快速故障定位,避免了数百万GMV损失
- 数据驱动决策:基于精确的遥测数据,而非经验猜测进行故障处理
- 系统性思维:从业务指标到技术细节的完整链路分析
技术架构的演进启示, -现代分布式系统的可观测性建设应该:
- 数据先行:建立完善的指标、日志、链路追踪数据采集体系
- 平台整合:通过APM平台实现多维度数据的智能关联分析
- 业务导向:始终以业务连续性和用户体验为最终目标
未来发展趋势 - 可观测性正在从技术运维工具向业务洞察平台演进:
- AIOps融合:结合机器学习进行智能故障预测和根因分析
- 全栈可观测:从基础设施到业务流程的端到端可视化
- 实时决策:基于可观测性数据的自动化应急响应和容量调度
实践指导原则 - 对于技术团队而言:
- 投资回报:可观测性建设的成本远低于故障损失的代价
- 分层建设:先建立基础数据采集,再完善平台整合,最后实现智能分析
- 文化转变:从被动应急向主动运维,从经验驱动向数据驱动的转变
最终结论:
在数字化时代,可观测性不再是可有可无的技术装饰,而是现代分布式系统的核心竞争力。通过APM平台整合指标、日志、链路追踪三大数据支柱,我们能够构建真正"可被理解"的系统,这正是应对日益复杂的技术挑战和业务需求的关键所在。
正如案例中老王在20分钟内完成从故障发现到根因定位再到问题解决的全过程一样,优秀的可观测性体系能够将"不可能完成的任务"变成"标准化的操作流程",这就是现代运维工程的核心价值所在。

















 855
855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









