






1.1主要研究内容
本次实验利用CNN对类别数据集进行分类,并掌握卷积神网络搭建的过程,了解卷积模块,池化模块,Batch Normalization模块,激活函数等各个模块的原理,以及对图像进行卷积操作,池化操作等计算方法与过程;对每次训练损失进行可视化,不断调整参数,例如优化器的选取、学习率等;通过混淆矩阵来评判分类结果好坏。
该实验所需的类别数据集
1.2 数据集描述
实验使用的类别数据集有6400张大小不统一的彩色图片,这些彩色图片归属八个类别,该类别包括猫、狗、飞机、花、水果、摩托车、汽车、人;每个类别含有800张图片。在整个数据集中,采用随机分配原则,按3:1来分为训练集和测试集。
通过数据集可以观察处,每个类别与之对应大小不一样,在其训练和测试过程要先对数据集进行处理统一裁剪成128X128大小,其每个类别(未裁剪)下图片如下:

1.3 特征提取过程描述
卷积具有旋转不变性和平移不变性特点,图像可以看成带有数值的矩阵,利用卷积核与图像矩阵做卷积操作,提取对应特征的特征向量;而且卷积神经网络有局部连接的特点,也就是每个卷积核都与之对应图像某块区域的特征,而在后续更深度卷积提取特征时,这块区域的卷积核权值共享,在进行误差反向传播更新权重也针对某块区域对应的卷积核。
1.4 分类过程描述
对于多分类问题,采用softmax分类进行分类;这个分类器封装于nn.CrossEntropyLoss()中,其结构如下图所示:
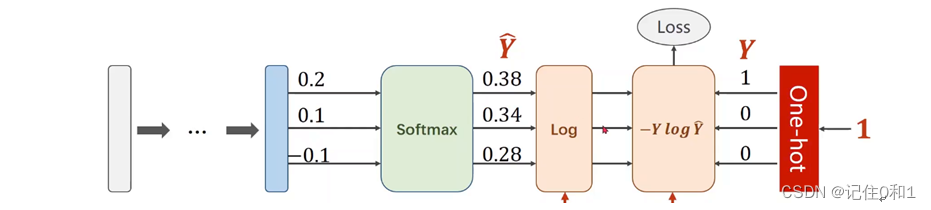
本次实验要分成8类,在经过卷积神经网络提取完特征后,经最后一个全连接层得到类别的得分,此时再送到softmax分类器转成概率问题,得出与之对应的概率值大小,也等同与预测的标签;上图的右半部分损失的计算是那预测与真实标签(-预测log真实),分类的正确最后以one-hot向量来展示出来。
1.5 主要程序代码
此次代码主要分为三个部分,第一部分是数据集的制作,把八类图片统一裁剪成相同大小;第二部分是网络的搭建,网络的搭建参考谷歌的Inception模块;第三部分是训练与测试,并用混淆矩阵来评判分类的好坏。
第一部分,统一裁剪成128X128,默认黑色填充;通过PIL模块下的裁剪函数thumbnail()和python自带函数paste将裁剪后的图像以复制方式存入新的类别文件里。
def resize_image(src_image,size=(128,128),bg_color="black"):
src_image.thumbnail(size,Image.ANTIALIAS)
new_image = Image.new("RGB",size,bg_color)
new_image.paste(src_image,(int((size[0] - src_image.size[0]) / 2),
int((size[1] - src_image.size[1]) / 2)))
return new_image
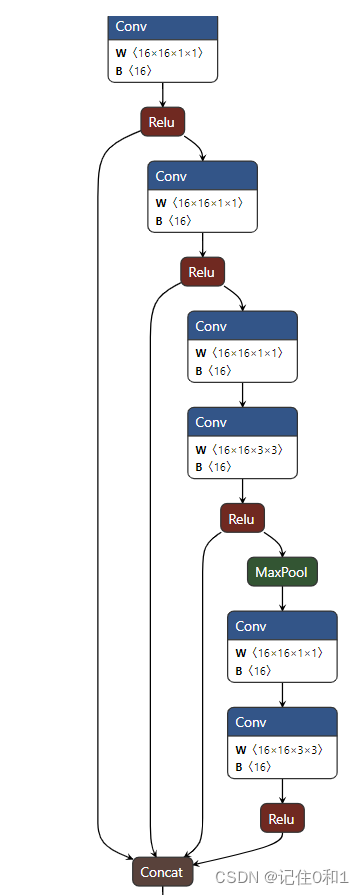
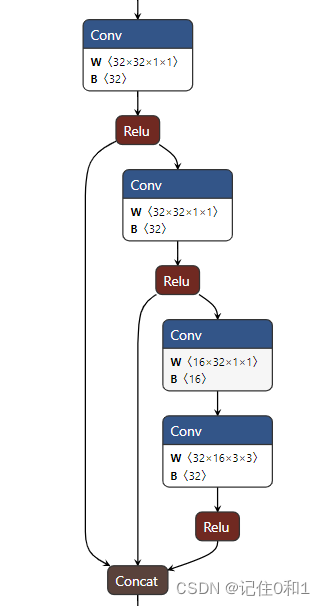
第二部分,网络搭建。参考谷歌的Inception模块进行网络的搭建,以堆叠两个为例开始搭建。参考的模块图如下:

与之对应的代码如下:
第一个Inception
self.branch1 = nn.Sequential(nn.MaxPool2d((2,2),1,padding=1)
,nn.Conv2d(16,16,1),nn.ReLU()) # outcome 16 32 32
self.branch2 = nn.Sequential(nn.Conv2d(16,16,1),nn.ReLU())
self.branch3 = nn.Sequential(nn.Conv2d(16,16,1),
nn.Conv2d(16,16,3,padding=1,bias=False),nn.BatchNorm2d(16),nn.ReLU()) # 16 32 32
self.branch4 = nn.Sequential(nn.MaxPool2d((3,3),1,padding=1),
nn.Conv2d(16,16,1),
nn.Conv2d(16,16,3,padding=1,bias=False),nn.BatchNorm2d(16),nn.ReLU())
第二个Inception:
self.branch2_1 = nn.Sequential(nn.MaxPool2d((3,3),1,padding=1)
,nn.Conv2d(32,32,1),nn.ReLU()) # 32 16 16
self.branch2_2 = nn.Sequential(nn.Conv2d(32,32,1),nn.ReLU()) # 32 16 16
self.branch2_3 = nn.Sequential(nn.Conv2d(32,16,1),
nn.Conv2d(16,32,3,padding=1,bias=False),nn.BatchNorm2d(32),nn.ReLU())
与之对应两个Inception模块可视化如下:
第一个Inception
第二个Inception
第三部分,训练与测试
首先,将处理好的数据集按4:1进行划分,训练4份,测试1份。其次,多类图片特征混杂,利用卷积旋转,平移不变的特点对数据集进行增强,并进行归一化操作。接下来,按批次进行带入模型开始训练,并在训练完后一个epoch进行测试。
总体流程:利用迭代器送入数据,梯度更新;数据导入模型;利用交叉熵计算损失;反向传播更新误差;优化器更新。
测试:采用Softmax分类器进行分类,选出概率最大的标签与真实标签来计算损失,并将预测正确的图片进行累加与测试集来求准确率。
def train(model,train_loader,optimizer,epoch):
model.train()
train_loss = 0
print("Epoch:",epoch)
for batch_idx,data in enumerate(train_loader):
inputs,labels = data
optimizer.zero_grad()
output = model(inputs)
loss = loss_criteria(output,labels)
train_loss += loss.item()
loss.backward()
optimizer.step()
# 此时一轮训练以及完了
print('\ttrain batch {} Loss: {:.6f} '.format(batch_idx + 1,loss.item()))
average_loss = train_loss / (batch_idx + 1)
print('train Average loss: {:.6f} '.format(average_loss))
save_path = './CNN.pth'
torch.save(model.state_dict(),save_path)
return average_loss
def test(model,test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
batch_count = 0
for data in test_loader:
batch_count += 1
data,target = data
output = model(data)
test_loss += loss_criteria(output,target).item()
_,predicted = torch.max(output.data,1) # torch.max()返回两个值,第一个值是具体的value,,也就是输出的最大值(我们用下划线_表示 ,指概率),
correct += torch.sum(target == predicted).item()
avg_loss = test_loss / batch_count
test_acc = 100. * correct / len(test_loader.dataset)
print('test Average loss: {:.6f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
avg_loss,correct,len(test_loader.dataset),test_acc))
return avg_loss
1.6 运行结果及分析
打印迭代10个eproch的训练和测试的平均损失以及在测试集上的准确率
Epoch: 1
train Average loss: 0.599938
test Average loss: 0.466966, Accuracy: 1466/1725 (85%)
Epoch: 2
train Average loss: 0.349040
test Average loss: 0.388526, Accuracy: 1468/1725 (85%)
Epoch: 3
train Average loss: 0.317507
test Average loss: 0.329491, Accuracy: 1507/1725 (87%)
Epoch: 4
train Average loss: 0.276383
test Average loss: 0.227195, Accuracy: 1549/1725 (90%)
Epoch: 5
train Average loss: 0.232911
test Average loss: 0.191380, Accuracy: 1585/1725 (92%)
Epoch: 6
train Average loss: 0.199521
test Average loss: 0.266515, Accuracy: 1539/1725 (89%)
Epoch: 7
train Average loss: 0.204359
test Average loss: 0.234018, Accuracy: 1562/1725 (91%)
Epoch: 8
train Average loss: 0.183928
test Average loss: 0.219552, Accuracy: 1571/1725 (91%)
Epoch: 9
train Average loss: 0.172145
test Average loss: 0.196981, Accuracy: 1595/1725 (92%)
Epoch: 10
train Average loss: 0.154918
test Average loss: 0.208049, Accuracy: 1579/1725 (92%)
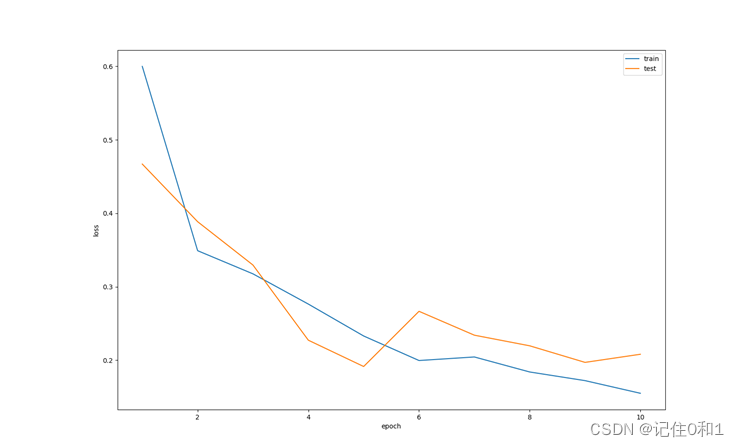
训练平均损失和测试平均损失可视化如下图:
混淆矩阵评判分类结果如下:
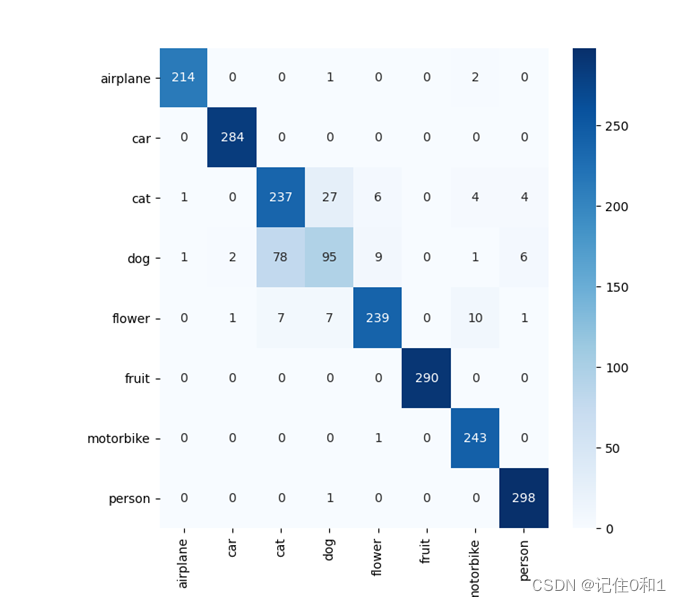
X轴对应真实标签;Y轴对应预测标签
对角线对应的预测准确的个数,以猫狗这两个类别来看,测试集上总共有264张猫的图片,有237张预测正确,有27张预测成了狗;由于随机分割,在测试集上狗的图片有192张。以猫狗为对比,预测正确只有95张,准确率比较低。在其他六个类别效果很好,在预测猫狗类上稍微差点,主要原因在猫狗图片相似处较多,得用深层得网络来提出特征。















 2970
2970











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











