







目录
1.1 Rescaling (min-max normalization、range scaling)
1.3 Standardization (Z-score Normalization)
记录下Feature scaling的相关知识点
一、概念和公式
Feature scaling是对数据做变换的方式,会将原始的数据转换到某个范围,或者某种形态。
Feature scaling的目的是为了获得某种“无关性”----偏置无关、尺度无关、长度无关……当归一化/标准化方法背后的物理意义和几何含义与当前问题的需要相契合时,其对解决该问题就有正向作用,反之,就会起反作用。所以,“何时选择何种方法”取决于待解决的问题,即problem-dependent。
1.1 Rescaling (min-max normalization、range scaling)
min-max 归一化:
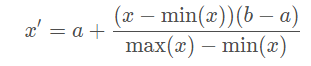
将每一维特征线性映射到目标范围[a,b],即将最小值映射为a,最大值映射为b,常用目标范围为[0,1]和[−1,1];
1.2 Mean normalization
mean 归一化:
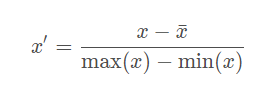
将均值映射为0,同时用最大值最小值的差对特征进行归一化;
1.3 Standardization (Z-score Normalization)
标准化:
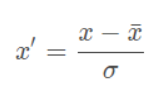
其中是样本的标准差(std);每维特征0均值1方差(zero-mean and unit-variance);
1.4 Scaling to unit length
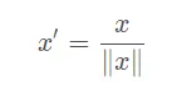
将每个样本的特征向量除以其长度,即对样本特征向量的长度进行归一化,长度的度量常使用的是L2 norm(欧氏距离),有时也会采用L1 norm;
二、什么时候需要feature scaling?
下表给出了几个常见监督算法是否需要监督算法:

- 涉及或隐含距离计算的算法,比如K-means、KNN、PCA、SVM等,一般需要feature scaling;
- 损失函数中含有正则项时,一般需要feature scaling;
- 梯度下降算法,需要feature scaling;
三、什么时候不需要feature scaling?
- 与距离计算无关的概率模型,不需要feature scaling,比如Naive Bayes;
- 与距离计算无关的基于树的模型,不需要feature scaling,比如决策树、随机森林等,树中节点的选择只关注当前特征在哪里切分对分类更好,即只在意特征内部的相对大小,而与特征间的相对大小无关;
四、代码示例
def normalization(data):
_range = np.max(data) - np.min(data)
return (data - np.min(data)) / _range
def standardization(data):
mu = np.mean(data, axis=0)
sigma = np.std(data, axis=0)
return (data - mu) / sigma

















 383
383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











