







作者:PP鲁
链接:https://www.zhihu.com/question/395145313/answer/1257660174
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
对于主流机器学习库,比如TensorFlow、PyTorch、LightGBM等,主要都是使用C/C++编写的。C/C++有如下优势:
- 如果用Python语言实现,Python解释器(例如CPython)会将Python代码翻译转化成机器能够理解的代码。而C/C++代码被直接编译成机器码,能够充分利用CPU、GPU等硬件的算力。
- CPython有一个限制并行计算的GIL锁。C/C++程序能够更好地进行并行计算,避免了CPython的GIL锁。
- C/C++可以显式(Explicitly)管理变量和内存,处理结果具有确定性(Deterministically)。
以TensorFlow为例,它提供了Python的调用接口,用户一般用Python来调用TensorFlow。实际上,其底层代码绝大多数是用C/C++编写的。Python只是TensorFlow的一个前端(Front End),Python需要通过调用C语言的API,进而调用底层的TensorFlow核心库。它的架构图如下所示:
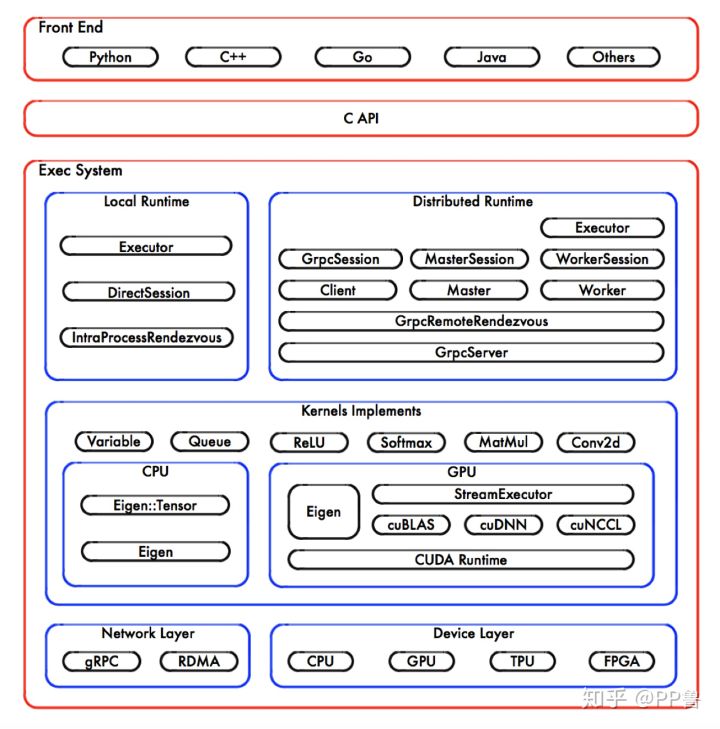
TensorFlow架构图 来源:TensorFlow Internals
上图中,最底层是硬件,包括了网络和计算设备,这里先只关注计算设备。由于CPU、GPU等硬件设计的区别,一些矩阵运算在不同硬件上的机器码有质的区别。线性代数部分一般基于Eigen库,这是一个专注于向量和矩阵运算的C++库;Eigen::Tensor是一个使用C++模板技术,它可以为多核 CPU/GPU 生成高效的并发代码。

英伟达GPU软硬件依赖栈
GPU部分最底层是操作系统和驱动,再往上是提供给程序员的开发接口CUDA。英伟达在CUDA之上提供了cuBLAS、cuDNN等库,cuBLAS是运行在英伟达GPU上的线性代数库(Basic Linear Algebra Subprograms,简称BLAS),cuDNN是英伟达为优化深度神经网络,在CUDA上包装的库,里面包含了Tensor计算、卷积、池化等常见DNN操作。cuBLAS和cuDNN代码会最终编译成英伟达GPU可运行的机器码。
cuDNN对英伟达硬件、驱动和CUDA版本有依赖要求,由于版本迭代,新版本的cuDNN只能运行在高版本的驱动和CUDA上。英伟达官方提供了版本依赖表。对于使用英伟达GPU的朋友,第一件事是基于自己的硬件安装最新的驱动。如果驱动、CUDA和cuDNN版本与上层应用不匹配,容易出现各类问题。很多时候,我们按照网上的教程安装了驱动、CUDA,并用pip安装了TensorFlow,最后发现有99%的概率依然用不了。因为,TensorFlow提供的pip安装包主要基于下面的版本进行构建的。

TensorFlow官方提供的经过测试的版本依赖关系
到底什么是包
广义上来讲,包(Package)其实就是一个软件集合,安装完包之后,我们就可以使用包里的软件了。Windows上缺少包的概念,类Unix系统一般使用包管理软件(Package Manager)来管理和安装软件,我们在手机上常用的应用商店其实就是一个包管理软件。软件发布者将编译好的软件发布到包管理仓库(Repository,简称Repo),用户通过包管理软件来下载和安装,只不过类Unix系统一般使用命令行来安装这些软件。
常见的包管理有:
- 在操作系统上安装软件:
- Ubuntu的apt、CentOS的yum、macOS的homebrew
- 在编程语言中安装别人开发的库:
- Python的pip、Ruby的Gem
- 包管理软件有对应的Repo:
- pip的PyPI,conda的http://Anaconda.org、R的CRAN
无论包管理模式如何,这些包管理系统都会帮助我们解决:
- 管理源码(Source Code)或者编译打包之后的二进制文件(Binary)。
- 解决软件包之间的依赖问题。比如,LightGBM还依赖了NumPy等其他包。部分依赖还对版本号有要求。
从源码开始编译一个包其实很麻烦:
- 很多时候需要基础环境一致,这包括操作系统版本(高版本的操作系统glibc版本比较高,一些新兴机器学习包一般基于更高版本的glibc,这些包无法安装到低版本的操作系统上)、编译工具(例如类Unix系统的GCC、CMake,Windows上的Visual Studio等)。
- 当前包所依赖的其他软件,比如GPU版的TensorFlow所依赖的cuDNN、LightGBM所依赖的NumPy等。
- 编译过程相当耗时。比如,TensorFlow的构建时间就非常长。
因此很多包管理系统在发布的时候,提供二进制文件。二进制文件下载解压之后就可以运行了,有点像Windows上的绿色免安装软件。但是:
- 别人编译好的软件是在别人的基础环境上进行的,这就导致这个软件非常依赖当初编译它的环境。
- 安装当前包之前肯定要先安装好这个包所依赖的软件包。
可见,包管理也是一个有一定挑战的问题。就像很多桌面软件和游戏只有Windows的版本一样,一些大数据、深度学习类的应用因为基于Linux环境开发和构建,常常对Linux支持更好。
作者:PP鲁
链接:https://www.zhihu.com/question/395145313/answer/1257660174
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
机器学习库安装方法
TensorFlow
如果想在GPU上使用TensorFlow,官方建议使用Docker。用户只需要安装GPU驱动即可,连CUDA都不需要安装。Docker在一定程序上能解决环境的隔离。
如果不习惯使用Docker,一些文章推荐使用conda来安装TensorFlow。因为conda不仅管理Python,还支持C/C++的库。因此在安装TensorFlow时,它不仅将TensorFlow所需要的一些二进制文件下载安装,还安装了一些其他依赖包。
使用conda创建一个名为tf_gpu的虚拟环境,安装GPU版本的TensorFlow:
conda create --name tf_gpu tensorflow-gpu
安装过程中显示除了TensorFlow本身,conda还将安装包括CUDA、cuDNN在内的依赖包:
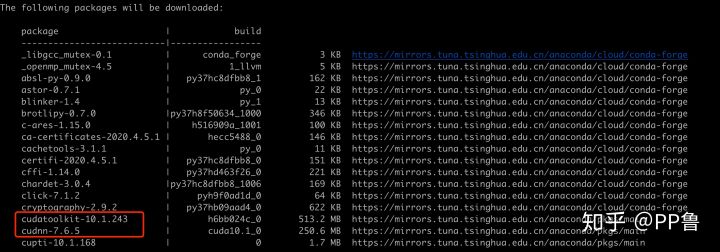
conda安装TensorFlow时会安装相关依赖,包括CUDA、cuDNN、BLAS等
小结
为了避免依赖问题,我们可能需要按照下面的顺序来管理我们的Python包:
- Docker
- conda
- pip
- 源码安装















 3067
3067











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









