






“Simulating the Real World: A Unified Survey of Multimodal Generative Models”
Yuqi Hu, Longguang Wang, Xian Liu, Ling-Hao Chen, Yuwei Guo , Yukai Shi, Ce Liu, Anyi Rao, Zeyu Wang, and Hui Xiong
由香港科技大学、中山大学等机构撰写。文章通过多模态生成模型,从数据维度增长的角度,系统回顾了真实世界模拟方法,涵盖2D、视频、3D和4D生成等方面,并探讨未来研究方向。
以下是按照章节对论文做简要概述。
引言
理解和复制现实世界是人工智能领域的关键挑战。文章指出传统方法在模拟现实世界时存在依赖手动设计、计算成本高以及未充分整合多模态数据等问题。而多模态生成模型为现实世界模拟带来了新的视角和方法,该文章旨在从数据维度增长的角度,对多模态生成模型进行统一的综述,为该领域的研究提供全面的参考。
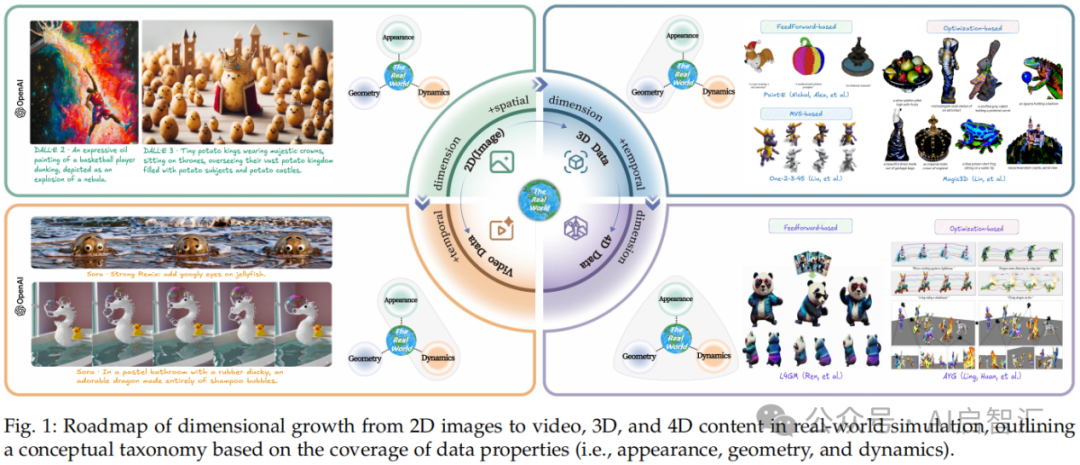
图1:展示从2D图像到视频、3D 和4D内容在现实世界模拟中的维度增长路线图
预备知识
依据现有生成模型的基础方法,论文列出必要的深度生成模型的基本概念,包括生成对抗网络(GANs)通过生成器和判别器对抗训练,使生成样本分布收敛到真实数据分布,但训练不稳定;变分自编码器(VAEs)通过变分推断最大化对数似然的下界,存在后验崩溃和模糊问题,但可进行数据压缩;自回归模型(AR Models)将联合概率分解为条件概率乘积,建模像素时难以并行化;归一化流(NFs)利用可逆神经网络变换数据分布,容量有限;和扩散模型(Diffusion Models)通过迭代添加和去除噪声生成样本,计算成本高。对比了这些模型的优缺点。这些模型是后续多模态生成模型研究的基础。
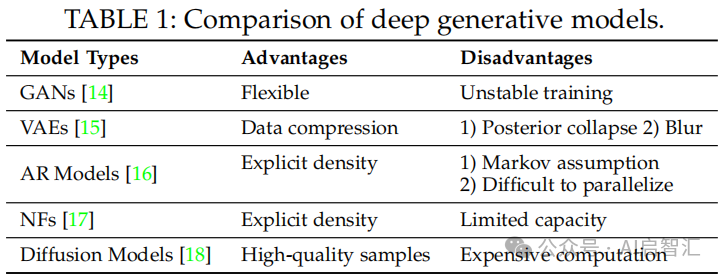
表 1:对比深度生成模型的优缺点
范式
从数据维度角度系统回顾相关算法
2D生成:文本到图像生成技术借助扩散模型、大语言模型和自动编码器等取得显著进展,能生成高质量、语义准确的图像。如Imagen利用预训练语言模型减少计算量,DALL-E系列不断改进架构提升图像质量和文本对齐度,Stable Diffusion及其扩展版本通过优化网络结构和训练方式提高生成效果。
视频生成:文本到视频生成模型通过适应文本到图像框架处理动态维度。分为基于VAE 和GAN 的方法(如SV2P、MoCoGAN 等)、基于扩散的方法(包括U - Net和Transformer架构,如Video Diffusion Models、VIT等)和基于自回归的方法(如CogVideo、VideoPoet等)。这些方法在视频编辑、新视图合成和人类动画等应用中发挥重要作用

图 2:按主要方法分类概述文本到视频生成技术
3D生成:聚焦几何和外观以模拟现实场景。3D表示分为显式(如点云、体素网格、网格、3D高斯)、隐式(如Signed Distance Field、Neural Radiance Field)和混合(如混合体素网格、DMTet、Tri-plane)表示。算法包括文本到3D(如Michelangelo、DreamFusion等)、图像到3D(如3DGen、RealFusion等)和视频到3D(如SV3D、CAT3D等)生成,在头像生成、场景生成和3D编辑等领域广泛应用。
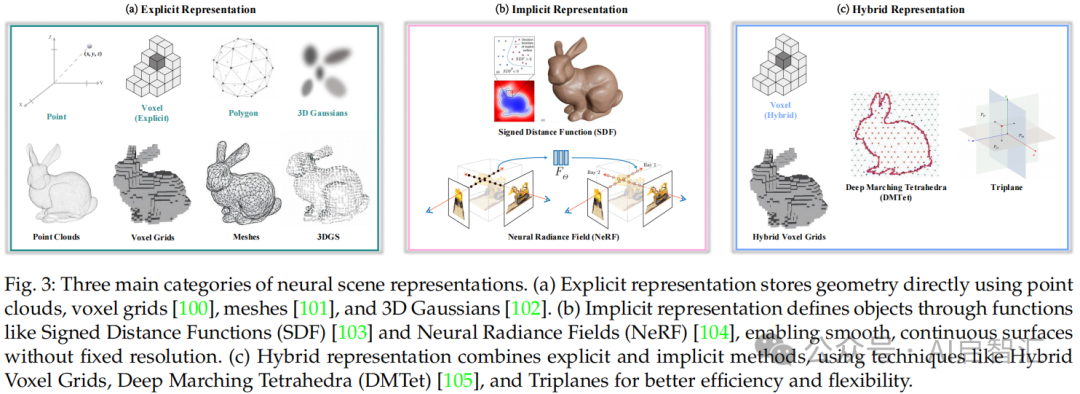
图3:展示神经场景表示的三种主要类别
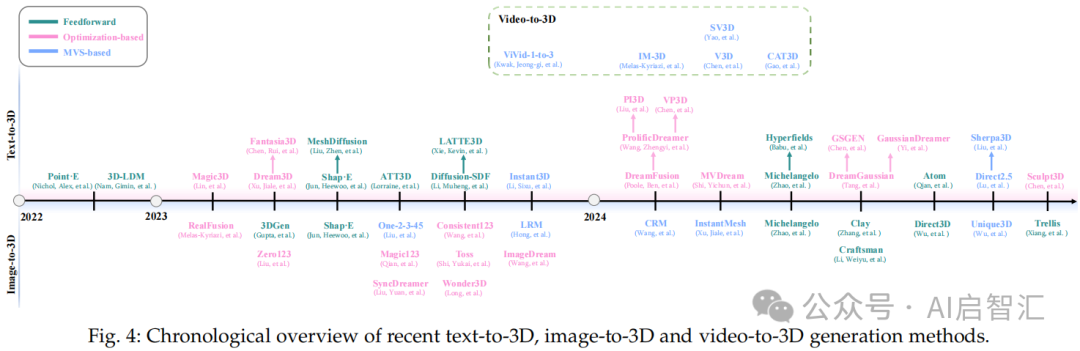
图 4:按时间顺序概述文本到 3D、图像到3D和视频到3D生成方法
4D生成:整合所有维度,合成基于多模态输入的动态3D场景。4D表示通过扩展3D 建模引入时间维度,如平面分解、哈希表示等方法提高效率。算法包括前馈方法(如Control4D、Animate3D等)和优化方法(如MAV3D、4D-fy等)。在4D编辑和人类动画等应用中面临挑战。
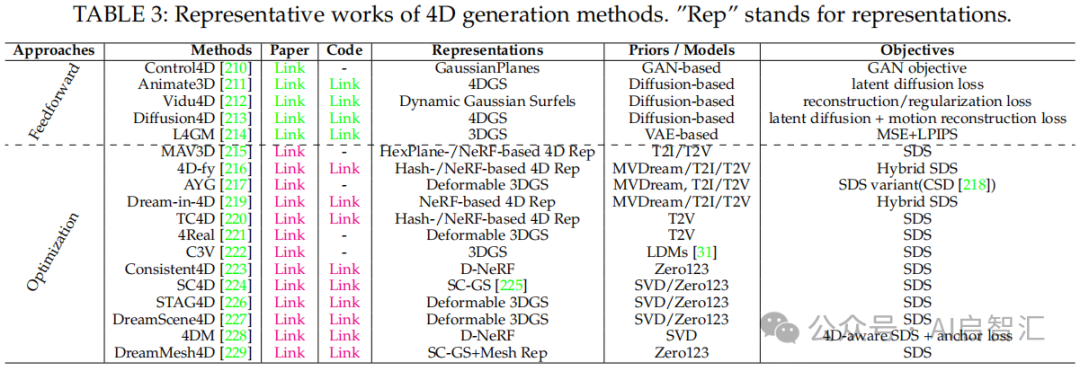
表3:总结4D生成方法的代表性工作
数据集和评估
总结了2D、视频、3D和4D生成常用的数据集,如2D生成的MS-COCO、视频生成的UCF-101等,介绍其数据规模、类型、评估指标和贡献亮点。评估指标分为定量分析(如PSNR、SSIM评估图像保真度,CLIP Similarity 衡量文本-图像对齐度)和定性分析(基于人类偏好的指标,如Appearance Quality、Geometry Quality等)
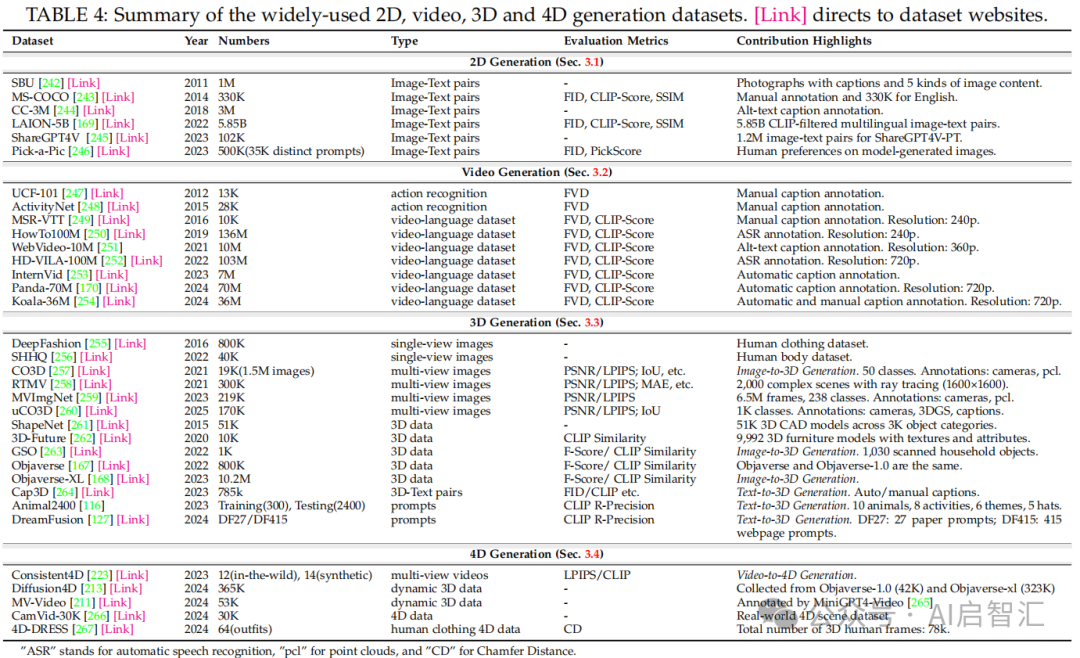
表4:总结常用数据集
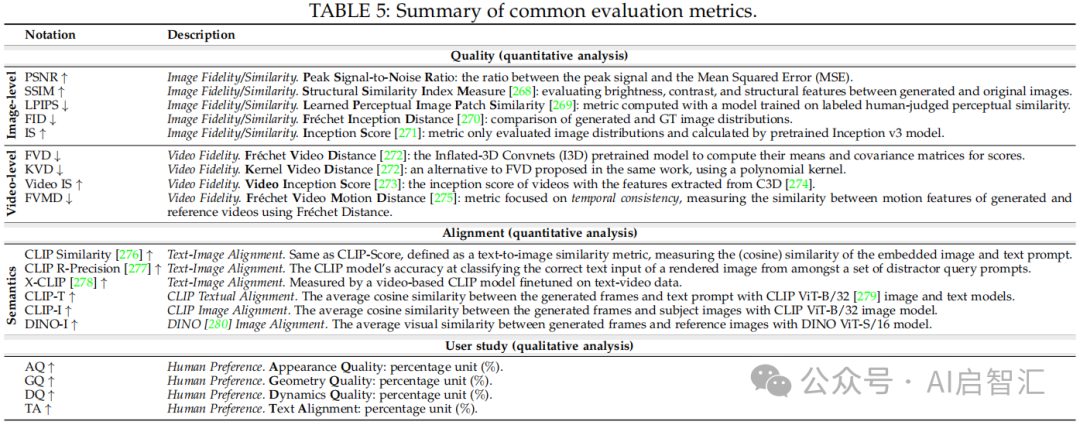
表5:总结常用评估指标
未来方向
尽管在2D、视频和3D生成方面取得进展,但4D生成仍面临挑战。包括生成多样化和合理的多模态4D内容、确保时间一致性和连贯性、进行物理和动力学建模、提高模型在不同场景的泛化能力、实现灵活的用户控制以及降低高计算成本等。解决这些问题将推动4D生成以及2D、视频和3D生成的发展。
结论
文章回顾了通过多模态生成模型在模拟现实世界方面的进展和挑战,总结了常用数据集和评估指标。尽管取得了显著进展,但在可扩展性、时间连贯性和动态适应性等方面仍存在挑战,为未来研究指明了方向,以实现更逼真的现实世界模拟。
仅供学习交流参考,感谢阅读!
可微信搜索公众号【AI启智汇】获取更多AI干货分享。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









