







论文标题:MINIMA: Modality Invariant Image Matching
导读:论文提出了一种统一的图像匹配框架MINIMA,旨在解决跨模态图像匹配任务中存在的挑战。该框架通过构建大规模多模态数据集,提升模型在不同模态图像间的匹配性能和泛化能力。
研究动机
跨模态图像匹配在多模态感知中至关重要,但面临诸多难题。不同成像系统产生的模态差异,使像素强度分布不同,难以提取通用匹配特征。现有跨模态匹配数据集规模小、场景覆盖有限,且标注成本高昂,导致模型训练数据不足、易受简单数据集主导,泛化能力差。因此,开发统一的跨模态图像匹配框架、填补数据缺口具有重要意义。
主要贡献
-统一框架:首次提出统一的匹配框架MINIMA,可处理任意跨视图和跨模态图像对,显著提升匹配性能。
-数据引擎与数据集:设计了简单有效的数据引擎,基于廉价的RGB 数据生成高质量多模态数据集MD-syn,填补了多模态图像匹配的数据空白。
-性能验证:在19种跨模态情况下,对域内和零样本匹配任务进行广泛实验,证明了MD-syn的高质量以及MINIMA良好的泛化能力。
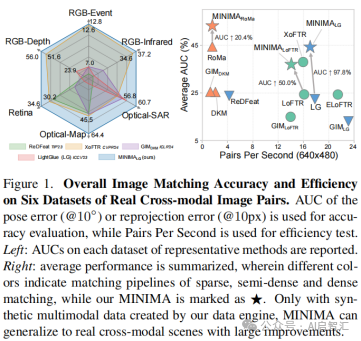
图1的左侧显示了各代表性方法在每个数据集上的AUC值,展示了不同方法在不同跨模态数据集(如 RGB-Event、RGB-Depth、RGB-Infrared等)上的匹配精度差异。右侧总结了平均性能,用不同颜色区分稀疏、半密集和密集匹配管道,MINIMA标记为 “⋆”。从右侧平均性能图可看出,MINIMA在整体性能上表现突出,表明其在不同类型匹配任务中都有较好的综合表现。
借助其数据引擎生成的合成多模态数据,MINIMA能在真实跨模态场景中实现显著的性能提升,相比其他方法,在精度和效率上都有更好的表现,证明了在跨模态图像匹配中的有效性。
方法
整体框架
图3展示了MINIMA管道的整体架构,这是一个用于实现任意跨模态匹配任务的单一模型框架,核心在于数据引擎和匹配模型训练过程,二者协同工作以达成跨模态匹配能力。
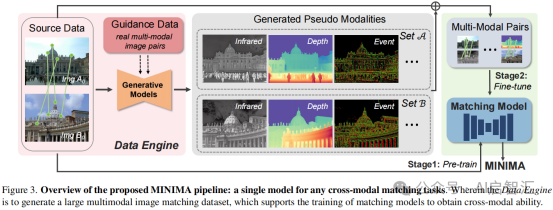
整体架构与目标:MINIMA旨在构建一个能处理任意跨模态匹配任务的单一模型。该框架通过独特的设计,利用数据引擎生成的多模态数据训练匹配模型,使模型具备在不同模态图像间进行准确匹配的能力。这种架构设计突破了传统方法针对特定模态的局限,实现了更通用的跨模态匹配。
数据引擎的关键作用:数据引擎是MINIMA的重要组成部分,其作用是生成大规模多模态图像匹配数据集。它以真实的RGB图像对为基础,借助强大的生成模型,从多个方面生成多种伪模态数据。通过数据引擎,不仅解决了多模态数据获取困难的问题,还保证了生成数据的质量和多样性,为匹配模型提供了丰富的训练素材,支持匹配模型学习不同模态间的特征和匹配关系,从而获得跨模态能力。
模型训练流程:在数据引擎生成数据的基础上,MINIMA采用了两阶段的训练策略。第一阶段在多视图RGB数据上预训练先进的匹配模型,利用RGB数据训练的成熟经验和良好的先验知识,使模型初步具备匹配能力。第二阶段在随机选择的跨模态图像对上进行微调,让模型进一步适应跨模态的特点,优化模型在不同模态间的匹配性能。通过这种预训练加微调的方式,充分利用数据引擎生成的数据,提升模型在跨模态匹配任务中的表现。
跨模态生成数据引擎:利用生成模型从真实RGB图像对生成多种伪模态数据。从MegaDepth数据集出发,选择该数据集是因其常用于户外多模态感知任务,具有丰富场景和准确标注。通过特定模型生成深度、事件、法线等模态数据,如用DepthAnything V2生成深度图像,基于事件相机原理模拟生成事件数据。数据引擎包含源数据(MegaDepth 的RGB 图像)、指导数据(真实跨模态图像对)和生成模型三部分。对于红外模态,基于StyleBooth 并利用LLVIP和M3FD数据集的RGB-IR 图像对进行微调生成。最终构建出包含480M图像对的MD-syn数据集。
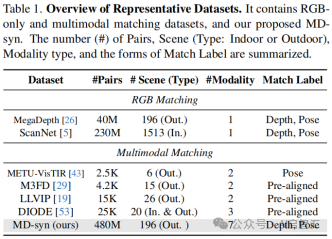
表格1是对代表性数据集的概述,主要涵盖RGB匹配数据集、多模态匹配数据集以及作者提出的MD - syn数据集,从多维度对这些数据集进行了总结,为理解不同数据集的特点和差异提供了清晰的信息。该表格包含了RGB匹配数据集和多模态匹配数据集两大类别,同时介绍了作者提出的MD - syn数据集。这样的分类有助于对比分析不同类型数据集在图像匹配任务中的特性。
图像对数(#Pairs):展示了各个数据集所包含的图像对数量。如MegaDepth有40M对,ScanNet 有230M对,而多模态匹配数据集(如METU - VisTIR有2.5K对 ,MD - syn有480M对)相对较少。这反映了不同数据集的规模大小,数据量的差异会影响模型训练的充分程度。
场景类型(SceneType):分为室内(Indoor)和室外(Outdoor)场景。MegaDepth 是室外场景,ScanNet为室内场景,多模态数据集中也各有不同场景类型。场景类型的不同意味着数据的多样性和应用场景的差异,对模型的泛化能力要求也不同。
模态类型(Modalitytype):RGB匹配数据集模态类型为1,即仅包含RGB信息;多模态匹配数据集的模态类型通常为2或3,如METU - VisTIR包含2种模态,DIODE包含3种模态;MD - syn则包含7 种模态,丰富的模态类型为跨模态匹配研究提供了更多可能。
匹配标签形式(Match Label):不同数据集的匹配标签形式不同,有深度、姿态、预对齐等。匹配标签的形式决定了数据标注的方式和精度,进而影响模型训练时对匹配关系的学习。
模态不变图像匹配模型(MINIMA):采用预训练和微调策略。首先在多视图RGB数据上预训练先进的匹配模型,如稀疏匹配的LightGlue、半密集匹配的LoFTR和密集匹配的RoMa 。然后在随机选择的跨模态图像对上微调,微调时针对不同模型设置合适的学习率和训练轮数,如LightGlue采用原学习率1×10^-4,训练50轮;LoFTR学习率降为1×10^-4,训练30轮;RoMa解码器学习率为1.5×10^-5,编码器为7.5×10^-7,训练4 轮。
实验
实验设置:
数据集:使用合成的MD - syn数据集及5个真实多模态数据集,共涵盖19种跨模态情况。MD - syn包含6种跨模态情况,部分用于域内测试,部分用于零样本评估;METU - VisTIR 是RGB - IR数据集;DIODE包含RGB - Depth/Normal数据;DSEC提供RGB - Event视频;MMIM 数据集用于遥感和医疗领域的跨模态评估。
评估指标:针对不同数据集的匹配标签,采用姿态误差AUC(如在MD - syn和METU - VisTIR中,报告5°、10°、20° 阈值下的姿态误差AUC)和投影误差AUC(如在DIODE中,收集四个角点的平均投影误差,报告3px、5px、10px 阈值下的AUC)来衡量匹配精度。为保证公平性,对对齐图像对施加合成单应性矩阵模拟变形后再进行评估,并统一将图像长维度调整为640。所有实验在单RTX 3090 GPU上进行精度和运行时测试。
基线方法:从稀疏、半密集和密集匹配管道中选取代表性方法。稀疏匹配包括SuperGlue、LightGlue、OmniGlue等;半密集匹配有LoFTR、ELoFTR、XoFTR等;密集匹配选择DKM、RoMa 等。部分手工制作的多模态匹配方法(如 RIFT、SRIT、LNIFT)和OmniGlue 仅在真实RGB - IR数据集上测试,因其在其他数据集上精度差且耗时多。
实验结果:
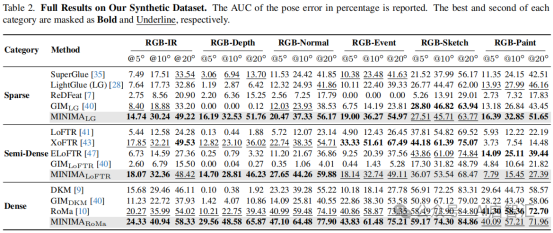
MD - syn数据集测试:MINIMA 能大幅提升基线方法的跨模态能力,但在RGB - Sketch和RGB - Paint 匹配上优势较弱,因为这两种艺术模态与RGB相似。GIM因过拟合RGB视频,在多模态情况下泛化性差;ReDFeat在新场景表现不佳,在事件模态匹配中甚至失败;LoFTR 系列中,原始LoFTR和ELoFTR在跨模态匹配上不如SuperGlue和LG,而XoFTR因预训练和特定设计取得较好结果;在密集匹配中,MINIMA结合RoMa表现突出。
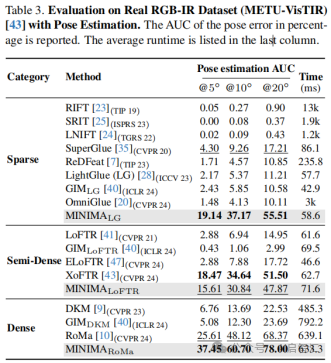
域内图像匹配:在RGB - IR(METU - VisTIR)和RGB - Depth(DIODE)的域内测试中,MINIMA_LG显著提升了稀疏匹配的AUC,在RGB - IR测试中甚至超越了SOTA半密集方法 XoFTR;在密集匹配中,MINIMA结合RoMa大幅超越其他方法。虽然基于LoFTR的MINIMA 半密集方法在RGB - Depth匹配上不如XoFTR,但相比原始LoFTR有显著提升。
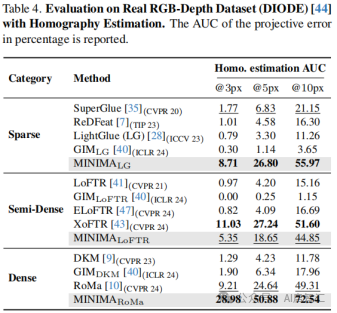
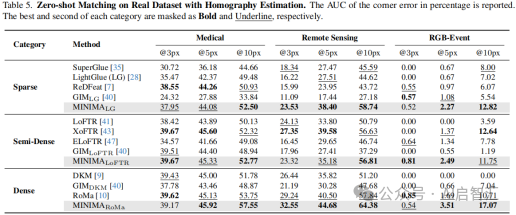
零样本匹配:在医疗、遥感和RGB - Event等零样本匹配任务中,MINIMA在不同场景下表现各异。在医疗场景中,各方法精度相近,但MINIMA_LG仍有一定优势;在遥感场景中,MINIMA在稀疏和密集匹配中取得较大增益;在RGB - Event匹配中,尽管任务极具挑战,MINIMA仍展现出良好的匹配能力。
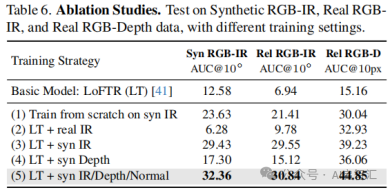
消融实验:以LoFTR为基础模型进行消融实验,结果表明微调优于从头开始训练,合成数据比真实数据集更具优势,不同合成数据组合能提升模型性能,使用RGB - IR/Depth/Normal 组合训练可获得最佳整体性能。
局限性讨论:生成伪模态数据可能存在与真实模态的差距和假信息,但实验验证这些对任务影响较小。现有扩散方法可使伪模态更接近真实,生成的假信息还有助于增强模型的鲁棒性。
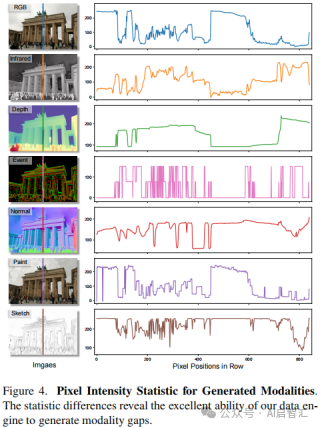
图4展示了生成模态的像素强度统计信息,其核心目的是验证数据引擎生成模态差异的能力,这对于构建有效的跨模态图像匹配数据集至关重要。
该图展现了不同生成模态(如 Normal、Paint、Event、Sketch 等)的像素强度统计情况。通过对这些模态像素强度的统计分析,可以观察到各模态之间的差异。不同模态在像素强度的分布、数值范围等方面表现出明显的不同,这些差异反映了不同成像模态的特性。
统计差异展示了数据引擎生成模态差异的卓越能力。在跨模态图像匹配中,不同模态之间的差异是需要学习和处理的关键因素。数据引擎能够生成具有显著差异的模态数据,意味着它可以模拟真实世界中不同成像系统产生的模态特征差异,为后续匹配模型的训练提供丰富多样的数据,帮助模型更好地学习跨模态的匹配模式,从而提高跨模态图像匹配的性能。
总结
论文提出了一种名为MINIMA(Modality Invariant Image Matching)的统一跨模态图像匹配框架,旨在解决多模态图像匹配中因模态差异带来的挑战。
仅供学习交流参考。
感谢阅读!可微信搜索公众号【AI启智汇】获取更多AI干货分享。


















 1615
1615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









